How to Make Algorithmic Trading Work Faster

Barbara Murphy, Vice President of Marketing at WekaIO, addresses how WekaFS overcomes the performance and latency challenges in the Financial Services industry in this first blog of a three-part series. This initial part of the series is titled “How to Make Algorithmic Trading Work Faster”.
The Problems with Algorithmic Trading
Algorithmic trading is the fastest-growing segment of the finance market. Today, 90% of all public market trading is done by quantitative means and 75% is fully automated. The business challenge for quantitative trading is how to extract better insights from a given set of data when everyone has access to the same public data. The winners are the companies that can run more models, with more complex algorithms, faster than the competition. Technological advances have always been a source of market advantage; however, it is fair to say that financial institutions are now more dependent on technology than ever before and that the early movers have the advantage over the competition.
Just look at the quote below from one of Weka’s customers that indicates the new workforce of trading firms: data scientists and engineers, not graduates with a finance degree.

We have come a long way from traditional trading strategies executed by humans, where the models had a limited number of market indicators and a small sample data set. When humans traded, the models typically had 6 to 8 technical indicators (because that was all the human brain could process), data sets were small, and traders focused on executing many short-window incremental trades.
Today, data scientists are exploiting technology and mining data for trading advantage. New machine models can have 100s of indicators and source data can be as varied as tick data, Twitter feed, macro-economic factors (Coronavirus statistics), and so on. The data sets are massive and the more indicators that make up the model, the longer it takes to execute on a trade. There is a constant battle between researchers, scientists, and traders because more complex models will be more insightful and better predictors, but trading windows are volatile.
The underlying technology of most finance houses was built on a model designed to serve individual traders, and when the data sets were relatively small, it worked well. You may remember that Fusion-io built an entire business with performance accelerators inside individual trading servers to speed up local storage, also called direct-attached storage (DAS). Today, however, the data sets and the number of variables in a market model are immense, making it impossible to fit within the storage capacity found in a single server. The reason DAS or dedicated SAN storage was the preferred solution was that the local area network was the bottleneck and direct-attached storage or Fibre Channel SAN offered significantly higher performance and lower latency. Latency is the amount of wall clock time lost between asking for something and getting it delivered to you; and latency is the #1 enemy of the finance industry. Network-attached storage (NAS) vendors brag about millisecond latencies, while a PCIe local bus works at the microsecond level.
Over the last few years, we have had a sea-change in networking capability with the introduction of low-cost 100-Gbit and now 200-Gbit networking from companies such as Mellanox. With the elimination of the network bottleneck, shared external storage is now viable. However, network-attached storage protocols (NFS and SMB) were never designed to work with fast networks and are limited to about 10% of what the network link can sustain. As a result, the technology habits of years have continued. Financial institutions still primarily use either DAS or all-flash SAN for their data store, with the view that this will give them the needed competitive advantage.
The Tyranny of Waiting to Access and Use Data
With the continued addition of more complex models and the integration of machine learning models to financial analytics, the bottleneck has shifted from the network to the users. This is because any communication with a DAS or SAN solution requires the system to be implemented in a single-threaded blocking mode in which any single user blocks data access to all others while performing data analysis or queries. The problem with DAS and SAN is that data cannot be shared, and the problem with NAS is that the protocol is too slow. You have two choices, neither of which is satisfactory. Either copy data from the NAS share to a local DAS server for faster access (assuming that the data will even fit on local NVMe drives) or block the access of other SAN users when any individual researcher is using a particular data set.
Modern analytics models process data sets that can span hundreds of terabytes and call upon dozens of parameters. A shared file system is the ideal way to present that data to a scientist because all data is always accessible. Using the DAS model, you take a copy of the relevant dataset and move it (slowly) from the NAS share straight into the server’s local storage. So now you have a copy on the server, and you have your authoritative copy that remains in the shared storage data catalog. The server is unusable while data is being copied into it, resulting in lost CPU or GPU processing time. Furthermore, other jobs must queue up and wait until the server eventually frees up. When you extrapolate this out to hundreds of servers, it quickly becomes a nightmare. Sure, your performance is great on your dedicated system, but on the reverse side, all that copying of data increases latency to the overall trading day, and the environment becomes incredibly complex to manage at scale.
For many of the market models that have long-running query cycles, the data sets can be inaccessible for hours at a time with a SAN approach. Meanwhile, other users must stand in line and wait until the data is unblocked. This leads to lower researcher and developer productivity and a much slower pace that results in lost opportunity and higher cost.
Problem Solved
As demonstrated below in Figure 1, Weka is the first and only company to build a solution for the finance space that delivers better performance than DAS and SAN, while also providing the shareability and ease of use of NAS and the massive scalability of parallel file systems.
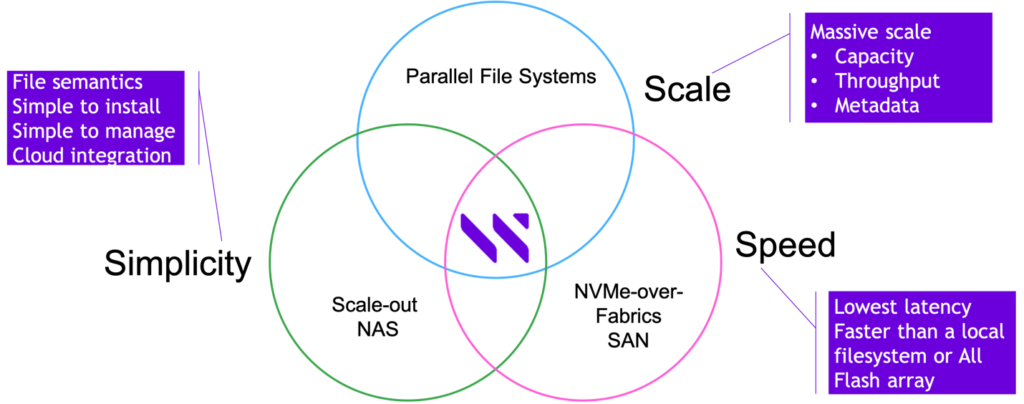
Figure 1: WekaFS – a Single Architecture for Financial Analytics
Weka has been delighting customers in the finance space, focusing on the most demanding workloads such as time series analytics on kdb+. The Weka file system – WekaFS – set multiple records on the STAC M3 benchmark test for time-series databases, beating out local DAS servers as well as SAN on many of the benchmark tests. In addition, WekaFS currently stands at #1 as the fastest parallel file system in the world on the IO-500, an industry benchmark that measures supercomputer storage performance.
All this emphatically demonstrates that Weka knows how to make algorithmic trading work faster! Stay tuned for parts 2 and 3 of this series!
To learn more about WekaFS check out our finance page or contact us to schedule an introductory meeting.
You may also like:
Isilon vs. Flashblade vs. Weka
Worldwide Scale-out File-Based Storage 2019 Vendor Assessment Report
NAS vs. SAN vs. DAS
Lustre File System
Popular Blogs From Barbara Murphy



Related Assets
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
