Lustre File System Explained
What is Lustre?
Lustre File System Architecture
The Lustre Infrastructure
Why Lustre is not well suited for AI/ML I/O intensive workloads
WEKA vs. Lustre
What is Lustre Storage?
Lustre® is an open-source file system that was developed in 1999 and released to general production in December 2003. It was developed under the direction of the Department of Energy (DOE) and has been widely deployed in national laboratories and large super-computing centers.
Lustre is a parallel file system, which is a type of distributed file system. However, the difference lies in how data and metadata are stored. Distributed file systems support a single global namespace, as do parallel file systems, but a parallel file system chunks up files into data blocks and spreads file data across multiple storage servers, which can be written-to and read-from in parallel. Metadata is typically stored on a separate metadata server for more efficient file look up. In contrast a distributed file system uses standard network file access and the entire file data and metadata are managed by a single storage controller. For bandwidth intensive workloads, this single point of access becomes a bottleneck for performance. The Lustre parallel file system does not suffer this single controller bottleneck but the architecture required to deliver parallel access is relatively complex, which has limited Lustre deployments to niche applications.
Lustre File System Architecture
The Lustre file system architecture separates out metadata services and data services to deliver parallel file access and improve performance. The architecture consists of a series of I/O servers called Object Storage Servers (OSSs) and persistent storage targets where the physical data resides called Object Storage Targets (OSTs), typically based on spinning disk drives. In addition, Lustre has separate metadata services and file metadata is managed by a Metadata Server (MDS) while the actual metadata is persisted on a metadata target (MDT).
The OSSs are responsible for managing the OSTs, handling all I/O requests to the OST and. A single OSS typically manages between two and eight OSTs, after which an additional OST is required to maintain performance. The OSS requires a local file system to manage file placement on the OST, typically this requires XFS or ZFS file system.
For metadata, the MDS provides metadata services managing all physical storage locations associated with each file so that I/O requests are directed to the correct set of OSSs and associated OSTs. The metadata server is never in the I/O path, a key difference from traditional NAS and clustered file systems. The MDS also requires a local file system to manage metadata placement on the MDT.
The Lustre Infrastructure
When a Lustre client wants to access a file, it sends a request to the MDS, which in turn accesses the associated MDT. The location of the data is returned to the client, which then directly accesses the OSS and associated OST. In real production environments the infrastructure is significantly more complex as the storage hardware used for MDTs and OSTs typically require additional hardware RAID devices or the addition of ZFS for the back end file system, which provides software-based RAID protection on JBOD (Just a bunch of disks) storage.
The following diagram (figure 1) provides a simplified view of the physical configuration of a Lustre environment. It is important to note that installing Lustre is not like installing a NAS appliance, it is composed of several different services that are deployed on separate server infrastructure.
Following the diagram below, the environment requires a Lustre management service (MGS) server whose job is to support the multiple file systems running in the Lustre environment. Clients and servers have to connect to the MGS on startup to establish the file system configuration and get notifications of changes to the file systems. While not compute or storage resource intensive, the MGS can pose a single point of failure because if the host fails all the client and server services will be unavailable while the MGS if offline. In order to alleviate this, the MGS must be deployed in a high-availability configuration. Again, just like other services in Lustre, the MGS must have a local file system deployed to managed the physical data storage on the management service target (MGT).
The second set of server infrastructure is composed of metadata servers (MDSs). As described earlier, these servers manage the namespace for the Lustre file system. MDS servers are typically configured in a RAID 1 (mirror) to ensure the MGS server can access the metadata server in the event of a server failure. It requires careful consideration how many metadata servers are required per file system and how much memory is required to support the number of Lustre clients accessing the MDS. For I/O intensive applications, getting the ratios correct can be a huge administration challenge and it is recommended to reference the Lustre tuning and sizing guide.
The third major component of server infrastructure is the object storage servers that house the file data. Typically the OSS make up the majority of the infrastructure as they manage the data services for individual files. Each OSS communicates with the OSTs that persist the physical data blocks. OSS nodes are connected over multiple paths to the physical media, protected with RAID controller or protected using the ZFS software RAID for file protection. Each RAID or ZFS stripe is an OST. Several strategies are utilized to manage storage services including layering file services on top of SAN infrastructure for more storage scale.
The final component of a Lustre environment is gateway servers to provide Linux and Windows user access via gateway services. These services are optional and may not be found in many HPC environments but are required if individual user access to the file system data is required.

Figure 1: The Lustre file system infrastructure (simplified)
Why Lustre is not well suited for AI/ML I/O intensive workloads.
The Lustre file system, and other parallel file systems such as IBM Spectrum Scale (also known as GPFS), separate data and metadata into separate services allowing HPC clients to communicate directly with the storage servers. While separating data and metadata services was a significant improvement for large file I/O performance, it created a scenario where the metadata services became the bottleneck. Newer workloads such as IoT and analytics are small file (4KB and lower) and metadata intensive, consequently the metadata server is often the performance bottleneck for Lustre deployments. When setting up the Lustre environment the MDS size has to be calculated with the workload in mind. It most important factor is the average size of the file to be stored on the file system. Based on the average file size the number of anticipated inodes is calculated, the default inode size is 1024 bytes for the MDT and 512 for the OST. A file system must have at least 2x the number of inodes on the MDT as the OST or it will run out of inodes and the file system will be full even though there is still physical storage media available. Every time a file is created in Lustre it consumed one inode, if the file is large or small it is allocated a single inode. Many AI workloads produce billions of tiny files which quickly consume inodes, the result is the file system is “full” even though the physical storage capacity is only partially used up. This Lustre forum provides a great example where the application generates tonnes of small files, the file system is “full” while only using 30% of the disk space.
Managing node count to match an unpredictable workload is one of the major problems using Lustre in an environment where file count and file size is unpredictable. Yet another challenge is poor metadata performance. AI and machine learning workloads require small file access with low latency. The Lustre file system was built for large file access, where the initial file request was the only latency experienced because after that the I/O streamed directly from the persistent media. Comparing Lustre metadata performance to a local file system such as XFS or ext4 shows that Lustre metadata performance was only 26% of the local file system capability. There are many strategies to alleviate metadata performance, NASA’s Pleiades Lustre file system has an excellent knowledge base on Lustre best practices including:
- Limit the number of files in a directory
- Avoid putting small files on Lustre to begin with and put on an NFS mount instead
- Put small files in a dedicated directory so that only one OST is needed for each file
- Avoid “stat” operations
- Avoid repetitive Open and close operations to minimize metadata operations
All of these operations require intervention by administrators to change best practices or they require changes to applications to minimize metadata operations. In any event, it is an ongoing challenge to maintain performance to metadata intensive applications.
WEKA parallel file system versus Lustre
Lustre is now a 21 year old file system that has continued to be deployed in high performance environments because legacy shared file systems based on Network File System (NFS) or SMB just cannot scale to the demands of modern workloads in AI and machine learning. That said, although it delivers much better parallelism, its inherent large file optimized design limits its ability to effectively work for mixed workload and metadata intensive applications. WEKA is a modern parallel file system which was released in 2017 to address I/O intensive workloads that require massively parallel access and huge metadata performance demands. WEKA has been built from scratch to leverage flash based technology, delivering ultra low latency and excellent small file performance. Unlike Lustre, which has been optimized for hard disk based storage and prefers 1MB file size, the WEKA file system stripes every file into 4KB chunks and serves them back in parallel. In essence, every file for WEKA is a small file problem, hence the reason it can so effectively manage tiny file performance.
WEKA has also solved the metadata choke point which too often cripples the Lustre file system. While the early design of separating data and metadata alleviated many of the problems of legacy NAS, it creted a new bottleneck for modern workloads. WEKA has solved the metadata performance issues by equally spreading data and metadata across all the nodes in the storage cluster. Each WEKA node provides metadata services, data services, NFS and SMB access and internal tiering to S3 based object storage for massive scalability. The infrastructure is greatly simplified while the performance on small file and metadata is orders of magnitude better than the Lustre design. Performance scales linearly as more nodes are added and there is no requirement for complex inode setup to a ensure file system will scale to the size required by the application.
In the IO500 benchmark, that was officially compiled at Supercomputing 2019, WEKA was place in #1 position overall (figure 2) as the world’s fastest supercomputing file system. Running in virtual instances in AWS, WEKA recorded over 2x the overall performance of the nearest Luster submission, the National Supercomputing Center in Changsha, China. While the Lustre system scored 19% better than WEKA for the bandwidth test, WEKA was 5.13x better than Lustre for metadata performance, highlighting the modern design.
With its huge parallelism, distributed metadata, enterprise feature set, integrated access to NFS and SMB, and greatly simplified infrastructure design, the WEKA file system is much easier to configure and manage for enterprises wishing to leverage a parallel file system for modern workloads in AI and machine learning. It supports high speed Ethernet and InfiniBand networks and supports NVIDIA GPUDirect storage for direct access to GPU clients. It is fully cloud enabled and can be deployed as a private cloud, in the public cloud or a hybrid cloud storage model between the two for cloud bursting and backup.
The following diagram (figure 3) shows a typical WEKA deployment in production.
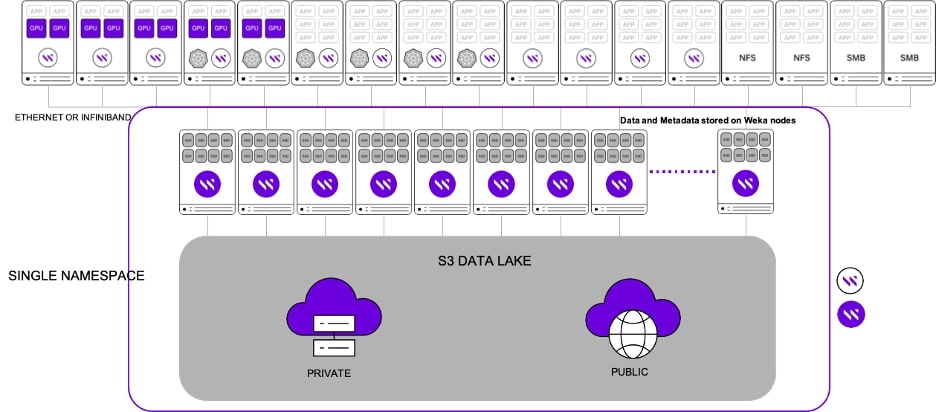
Figure 3: WEKA in a production environmenet
Additional Helpful Resources
FSx for Lustre
BeeGFS Parallel File System Explained
Clustered File System
Learn About HPC Storage, HPC Storage Architecture and Use Cases
Worldwide Scale-out File-Based Storage 2019 Vendor Assessment Report
5 Reasons Why IBM Spectrum Scale is Not Suitable for AI Workloads
Isilon vs. Flashblade vs. WEKA
Gorilla Guide to The AI Revolution: For Those Who Are Solving Big Problems
NAS vs. SAN vs. DAS
What is Network File System?
Network File System (NFS) and AI Workloads
Block Storage vs. Object Storage
General Parallel File System (GPFS) Explained
Introduction to Hybrid Cloud Storage
Distributed File System Explained
Recommended Resources



Related Assets
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
The Buyer’s Guide to Modern Storage

The Buyer’s Guide to Modern Storage