Fit for Purpose: Part One - Networking

When it comes to technology solutions, there's a stark difference between purpose-built systems and those that are simply trying to fit in. Purpose-built systems are designed from the ground up with a specific goal in mind, ensuring optimal performance, efficiency, and scalability for that particular use case. They seamlessly integrate into the workflow, offering robust features and reliability tailored to the task. On the other hand, “iterative” systems that are trying to fit in often involve retrofitting or repurposing generic solutions, leading to compromises in functionality, increased complexity, and a higher likelihood of issues. These makeshift solutions can result in inefficiencies, higher costs, and ultimately, a less satisfactory user experience. The superiority of purpose-built systems lies in their precision and alignment with the intended application, delivering unparalleled performance and ease of use.
The downsides of making legacy data infrastructure try to fit a modern application are significant. Legacy or iterative infrastructure often lacks the flexibility and scalability required to meet current performance demands, leading to frequent bottlenecks and suboptimal operation. In the long run, the hidden costs and operational inefficiencies of trying to make these types of infrastructure fit can far outweigh any initial savings, making it a less viable option compared to purpose-built solutions.
NeuralMesh is AI-Native Data Infrastructure
In 2013, we at WEKA set out with a blank sheet of paper and a vision to create a product that would eradicate the compromises of the past AND power the possibilities of the future. NeuralMesh™ is fit for purpose for large-scale AI whether on-prem or in multi-cloud environments. Its advanced architecture delivers radical performance, leading-edge ease of use, simple scaling, and seamless sharing of your data, so you can take full advantage of your enterprise AI workloads in virtually any location.
Being fit for purpose for AI workloads is more than just being able to run AI workloads, it denotes a fundamental reorientation of how data is collected, stored, and processed so that the wide variety of AI workloads can run efficiently at scale with a reasonable cost. The power of the NeuralMesh architecture is that we can deliver incredible IOPs, bandwidth, and latency in a highly efficient footprint. We find that when compared to solutions that aren’t AI-native, we are usually 10X or more efficient across a variety of measures that matter – power and cooling, CPU utilization, and others. In this blog series, we are going to detail how NeuralMesh stands out from the competition in efficiency and performance and what the impacts to your AI environment are.
Physical Network Efficiency
At WEKA, we talk a lot about our leading performance efficiency, but there are many other ways in which we are optimized. One meaningful way is that we deliver high per-port performance, which means that customers need fewer switch ports to achieve the desired performance levels required for checkpointing and inference at scale. In contrast, one legacy storage competitor requires 20X more cabling just to match the bandwidth needed for these capabilities. This results in expensive and sprawling backend connections, leading to more points of potential failure and increased physical infrastructure management overhead. The cost of additional switch ports and cabling can be a substantial hidden "tax" for those systems. Moreover, all the extra switching adds increased complexity, making it difficult to troubleshoot when something goes wrong let alone carry out basic maintenance such as expanding the system.
As a modern, fit-for-purpose solution, NeuralMesh is not constrained by 30+ year-old data access techniques, allowing our customers to implement and fully saturate the latest generation of network infrastructure, including up to 400Gb and 800Gb port speeds.
While a protocol like NFS is popular for its simplicity and compatibility, its design limits its ability to fully utilize high-speed network connections. As a result, iterative NAS solutions might architect their solutions using 100Gb (or lower) networking, which notably is already two generations behind.
To make matters worse, iterative NAS solutions often introduce new inefficiencies while attempting to solve the inefficiencies of their predecessors. For example, Shared-Everything Scale-Out NAS aims to address the inter-node communication inefficiencies found in Shared Nothing Scale-Out NAS designs. However, in trying to eliminate the serialization of data operations between cluster nodes, Shared-Everything merely shifts the bottleneck by creating inefficiencies in the networking stack.
A Baseline 1PB Comparison
A Disaggregated Share Everything architecture necessitates multiple network hops to connect compute nodes to capacity nodes. Data must travel from the capacity nodes to the compute nodes through a layer-2 RDMA fabric before reaching the application or user, adding significant latency. These issues become pronounced as systems scale, making shared-everything scale-out NAS inadequate for meeting the performance demands of AI and other HPC-class workloads. Beyond the logical data path, this vastly over-complicates the physical infrastructure requirements, often resulting in up to ten times more cabling.
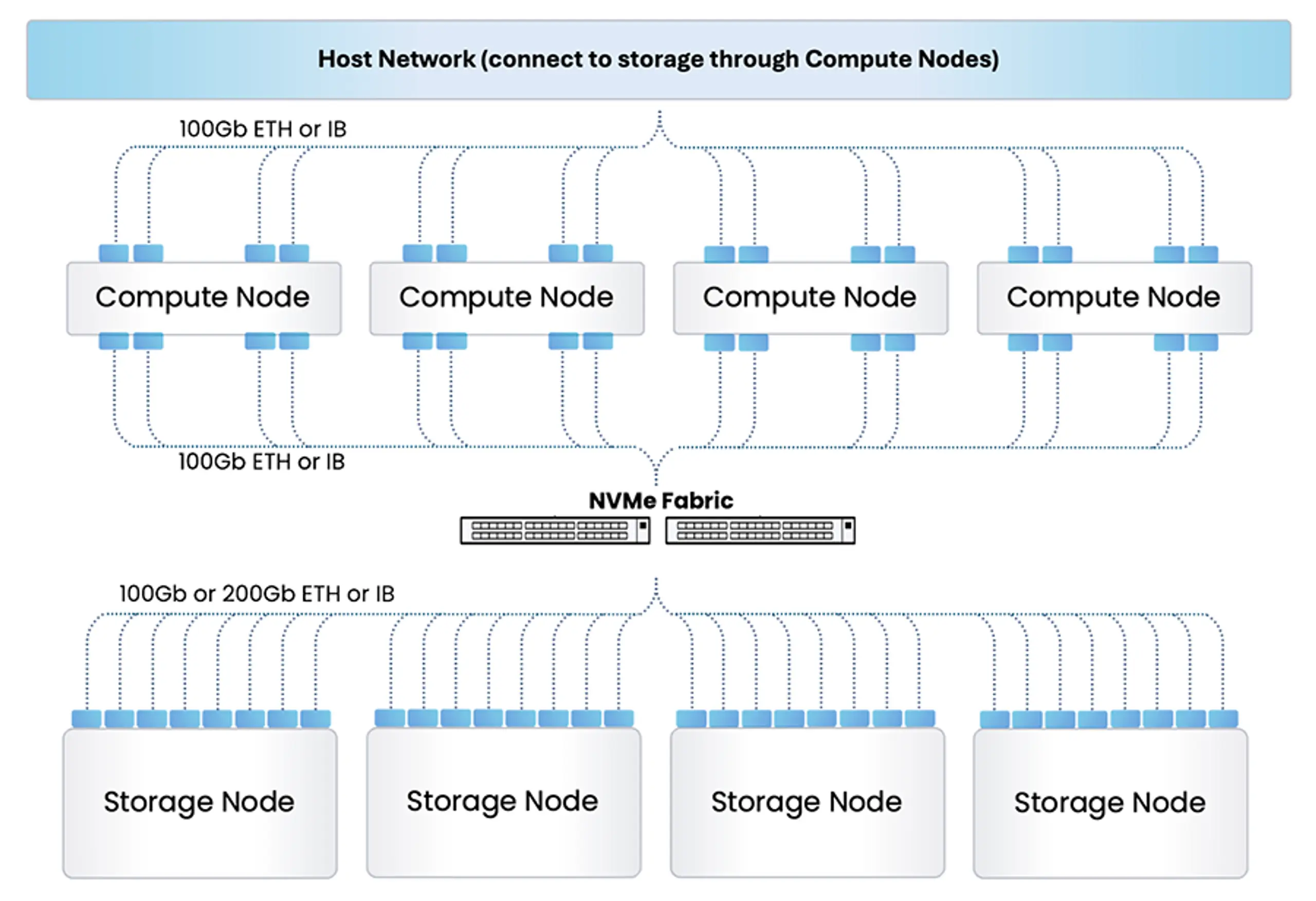
Figure 1: Shared-Everything Scale-Out NAS network topology
The cost of independently scaling performance and capacity is high. High port count, higher cable counts, and ultimately higher latency. Figure 1 illustrates a design for a 1PB Shared Everything Scale-Out NAS solution. This setup includes 4 x storage nodes connected to 4 x compute nodes through a pair of fabric switches, totaling 14 rack units.
Each compute node connects to the host network with up to 4 x 100Gb connections per node (8 connections per box). Additionally, compute nodes must connect to the backend NVMe fabric using another 8 x 100Gb network cables to communicate with the storage nodes. Each storage node is also connected to the NVMe fabric with up to 8 x 100Gb network connections per box. This solution, capable of roughly 200GB/s read bandwidth, 40GB/s write bandwidth and roughly 1 million IOPS requires 96 x 100Gb data connections, excluding management connections, which would increase cable count by up to an additional 32 x 1Gb connections.
By comparison, a 1PB WEKA cluster design (Figure 2) only requires 8 homogenous storage nodes, each node connecting to the host network using redundant 400Gb networking cables for a total 16 x 400Gb connections. Management would add 8 x 1Gb connections. This particular WEKA solution, which fits into 8 rack units, delivers over 720GB/s read bandwidth, 186GB/s write bandwidth, and over 18 million IOPS. This baseline 1PB configuration with NeuralMesh requires 1/6th the number of network cables and ports, while delivering anywhere from 3.5x-18x the performance of shared-everything NAS.

Figure 2: WEKA Data Platform network topology
Comparing “Best” Solutions for AI
When designing AI solutions at scale, training 175 billion parameter LLMs on 1,000 GPUs, 530 billion parameter LLMs on 2,000 GPUs, and 1 trillion parameter LLMs on 4,000 GPUs, it becomes increasingly important to ensure that storage does not become a bottleneck.
NVIDIA provides guidance around recommended storage performance for NVIDIA Cloud Partners (NCP) who are designing the next generation of data center architecture for artificial intelligence (AI) for cloud service providers (CSPs). The storage performance required to maximize training performance can vary depending on the type of model and dataset. Table 1 outlines the performance required to meet inference and checkpointing requirements at 1,000s of GPU scale.
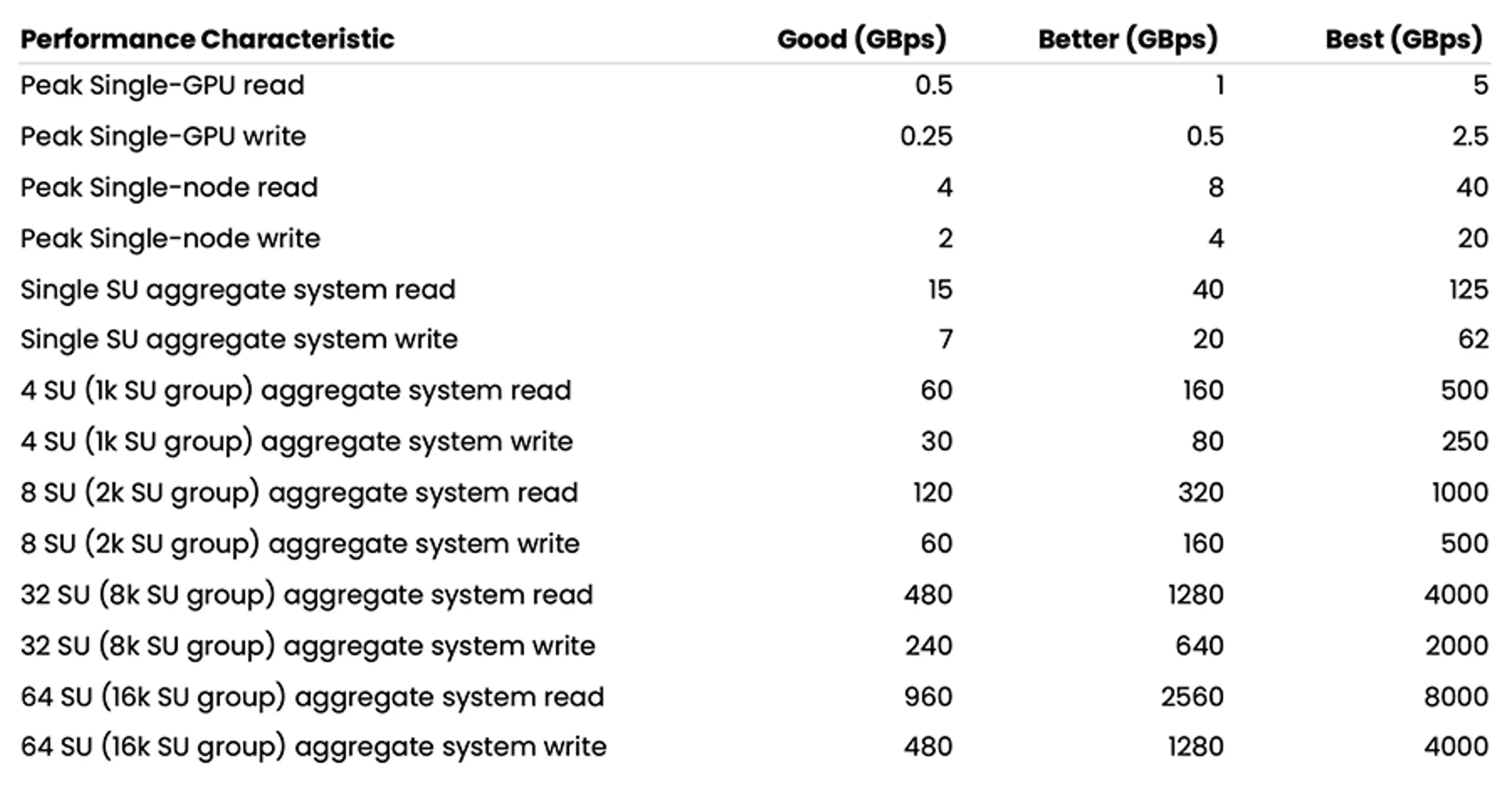
Table 1. Guidelines for storage performance
Using NVIDIA’s recommended sizing in Table 2, let’s do a sizing exercise to build and compare accommodating Shared Everything NAS and WEKA solutions for a 1,000x GPU infrastructure, which consists of 4x NVIDIA Scalable Units (SU). A "Scalable Unit" (SU) is a basic building block designed to efficiently scale compute, storage, and networking resources in a data center.
If attempting to deliver “Best” requirements using a Shared Everything Scale-Out NAS solution, it’d require 25 x storage nodes and 30 x compute nodes and as many as 20 NVMe fabric switches since you’d be forced into a spine-leaf NVMe fabric topology. This would require 60 x 400Gb-to-2x200Gb splitter cables connecting compute nodes to the host network and 440 x 100Gb network cables to connect compute and storage nodes together, as well as 220 x 1Gb management connections. Your Shared Everything solution would deliver over 1,200GB/s read bandwidth and 250GB/s write bandwidth.
In order to deliver “Best” requirements in NeuralMesh, it’d only require 12 homogenous storage nodes, each node connecting to the host network using redundant 400Gb networking cables for a total of 24 x 400Gb connections. Management would add 12 x 1Gb connections. This solution would be capable of nearly 800GB/s read bandwidth and 264GB/s write bandwidth in just 12 rack units. This real-world configuration requires 20 times fewer network cables and ports with NeuralMesh.
Conclusion
In this first part of our series, "Fit for Purpose: Networking," we've delved into the crucial differences between purpose-built systems and legacy solutions that are merely trying to fit in. The advantages of a fit-for-purpose system like NeuralMesh are clear: high per-port performance, reduced complexity, and significant network cost savings. In contrast, retrofitting legacy infrastructure results in inefficiencies, higher costs, and greater potential for failure.
NeuralMesh's AI-native design exemplifies the power of a purpose-built solution, offering unparalleled performance, ease of use, and scalability. By eliminating the need for excessive cabling and complex backend connections, NeuralMesh not only reduces hidden costs but also simplifies maintenance and expansion. This focus on efficient design and architecture ensures that your AI workloads can run at scale without bottlenecks, providing a seamless and powerful user experience.
As we continue this series, we will explore more ways in which WEKA stands out from the competition in efficiency and performance. Stay tuned to learn how our solutions can impact your AI environment and why choosing a purpose-built system is the smart choice for future-proofing your infrastructure.
What's Next



Scale Production AI Faster with NeuralMesh
Your models aren't slow. Your data is. Fix AI bottlenecks with high-throughput infrastructure.