The Challenge of IO for Generative AI: Part 3

Pre-processing, Training, and Metadata
One area that is typically underestimated is the overall metadata load when dealing with Lots Of Small Files (LOSF), which is the dominant data style for many AI workloads. This metadata issue is seen throughout the GenAI pipeline, but let’s focus on two stages of the pipeline where it has an outsized impact: pre-processing and deep learning training of the data.
During pre-processing, the ingest data is manipulated into a state that the model training expects to be able to use. This could involve annotating/tagging, image resizing, contrast smoothing, indexing, and more. When you have multiple researchers/scientists working on the same data, each one may need to pre-process the data differently, depending on what they intend to train or re-tune the model on. Even with the same data set, there are huge variations between the pre-processing steps each researcher performs.
The result is a mixed IO environment for pre-processing that can be up to 50% of an epochs’ training time.
AI Training Job
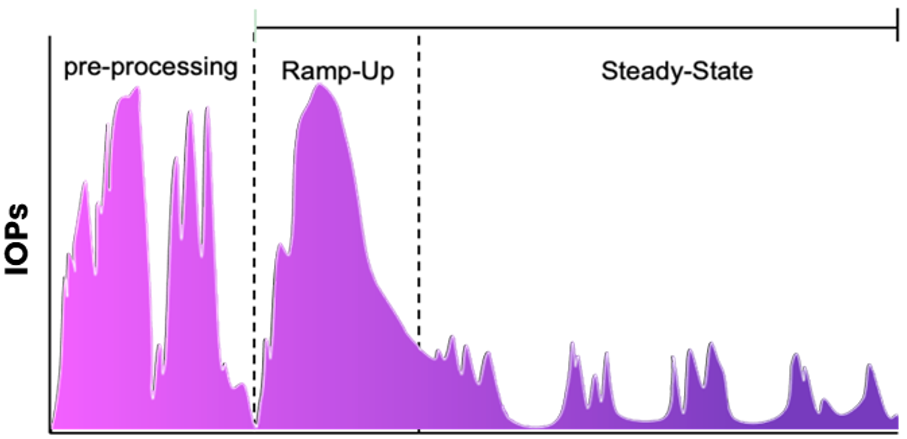
Time
The IO implications are massive. When accessing Lots Of Small Files (LOSF), you wind up with not only the IO Blender problem, but you now also have millions of file operations, reads, and writes with varying IO sizes and operations.
As an example of this metadata overhead, WEKA looked at a customer who was doing a deep learning pipeline using TensorFlow over ImageNet with a training database of 14 million images.
The pre-processing function has a large amount of writes against small files associated with it as it reads, modifies and writes data back. As mentioned before, the dominant style of storing AI datasets during pre-processing is an LOSF configuration. When this pre-processing is mixed in with all of the other IO in a system, you wind up with an IO blender problem again but with a bit of a difference: you can burn through the write cache in the system and get into a vicious cycle of having to do additional IO to refresh the cache, resulting in a slowdown of the system and extending the time needed to complete these metadata-intensive stages of the pipeline.
The second stage that has an outsized impact on metadata is a deep learning training stage. This tends to be less write-intensive, but has lots of random reads against small files. The data processing usually follows some variation of:
- Mini-batch and iterate over random subsets of the entire data set
- Train on each mini-batch
- Full epoch processing of the entire data set, usually in a random order
- Some form of hyperparameter set to control the process (e.g. precision needed, # of epochs, etc.)
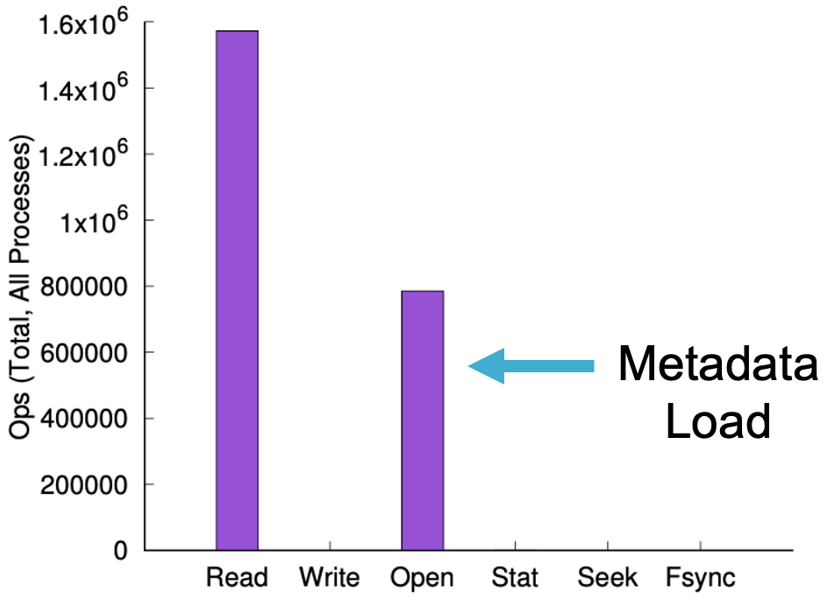
This process (or a variation of it) results in massive amounts of file opens, file stats, and more that don’t show up as traditional IO. In the chart below, you can see an example of a WEKA customer doing training with TensorFlow over ImageNet with a training database of 14 million images. During this training, 30% of the reads were file opens. WEKA has found that this overhead is indicative of deep learning training and ResNet-50 types of loads with transfer learning and can be anywhere from 25-75% depending on the training type being deployed and the size of the files. This “Hidden IO” can create overhead on a data platform that gets worse as the workload scales up. Picture a 10 million read IOP environment where you need to process an extra 5 million metadata IOPs on top of that.
I/O Operation Counts
The size of the files matters as well. In that same TensorFlow pipeline, WEKA saw that the data sizes were either extremely small (sub-100 bytes) or mid-large sized at 10KB-1MB in size. Because of the variance in file sizes, the data platform needs to be capable of handling both very small random IO as well as somewhat more sequential IO at the same time to accelerate the epoch times for training.
By now, it should be apparent that the case has been made for why multi-pipeline mixed IO and metadata is a real challenge that needs a highly performant data platform that can handle multi-dimensional performance at the same time. And we haven’t even touched on the issues involved with checkpointing a training cycle yet. And yet… some of you may be saying: “I’m not doing ResNet-50 and TensorFlow.” Or “My deep learning batching is way different than what you described, so your examples don’t apply to me!”
Well, hang on, because in part 4, we’ll show examples of IO access patterns based on different types of AI workflows and how they relate to the performance capabilities of a data platform.
Popular Blogs From Joel Kaufman



Related Assets
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
See NeuralMesh in Action

See NeuralMesh in Action