The Challenge of IO for Generative AI: Part 1

The Modern Enterprise AI Environment: Silos, Data Stalls and the Evolution of HPC
Over the next few weeks, we’re going to explore what’s going on with data IO in generative AI (and general AI) environments. The purpose of this series is to help bring to light some of the core information that WEKA has accumulated over the years in servicing IO for AI in a range of customer deployments, from those running rent-in-a-hyperscaler GPU environments, all the way up to some of the largest (12,000+) GPU farms in the world. We’re going to break it down into three (maybe four…) chunks:
- The modern enterprise AI environment: silos, data stalls and the evolution of HPC
- Data pipelines, consolidation, and the IO blender
- Real-world IO profiles and metadata
Let’s start out with Genesis: “In the beginning…” there was data. And not a lot of data in HPC by today’s standards. I call out HPC, because these environments were the direct predecessor to modern AI and a tremendous influence on infrastructure architecture. If you go back to the early 2000s, a massive HPC deployment would have only had 4-5 petabytes of storage and the average ones would be sub-petabyte. A lot of this architecture was designed with the idea that the fastest tier of storage to feed the compute was HDD. Because of the limitations of HDD, jobs were typically sized to load into memory as much as possible, avoid swapping out, and required checkpointing to ensure that if anything happened while loading or writing out a job to the slow and somewhat fragile HDDs, you wouldn’t have the incredibly slow process of waiting for re-load and re-start for a full data set to come back after an error.
As CPU and networking technologies got faster, the performance of HDD storage IO became a massive bottleneck. HDDs couldn’t keep up with the speeds at which the CPUs could consume IO. When flash SSDs arrived on the scene, they were fast, but prohibitively expensive. This forced customers into having a tiered and siloed approach in order to get the best performance at a reasonable price. Each silo would be optimized for a certain function to get the best value. The architected environments looked a lot like this:
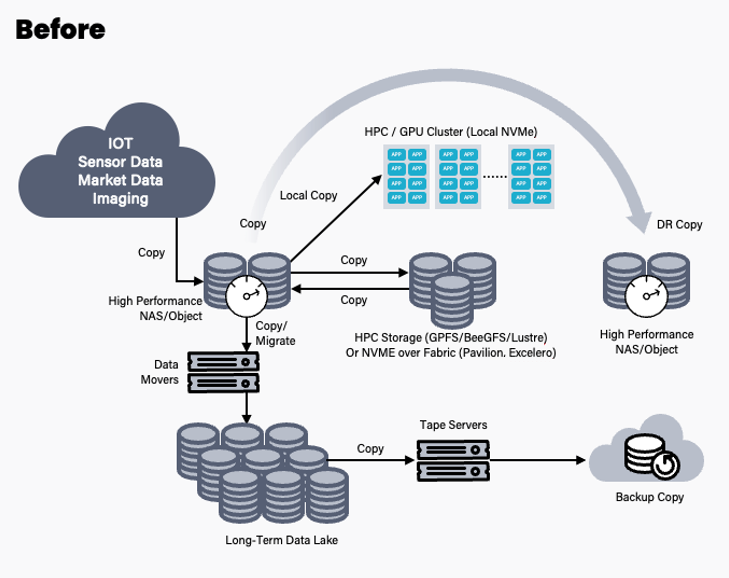
Data would come in and be stored in a data repository, usually consisting of an HDD or maybe some flash-based NAS, and then the data would be pre-processed and then copied off to either local high-performance drives in the compute nodes, or into a higher-performance storage tier, usually powered by a parallel filesystem of some sort. Afterward, the data would be copied back off to the NAS device, and then longer-term data retention and protection would come into play. This copying process, which was required in order to use the data and help saturate the compute nodes, introduced huge operational overhead and created “data stall”. Data stall became such an issue that significant research from the likes of Google, Microsoft, and research universities published papers about the problem.
This siloed architecture became the de facto way that HPC and early AI deployments were deployed and resulted in CPU farms idling sometimes 50% or more of the time waiting for job data to be sent to process. This is before the data even reached the point of core training or simulation processing. Eventually, filesystems got better and drives got faster, but even with these performance improvements, time, the idling problem got exacerbated. CPUs yielded the compute crown to GPUs. Networks moved from 10/25/40 Gbit up to 100/200/400 Gbit, and storage capacity was up as well. This far outstripped the performance that even NVMe flash drives could provide in general, and with the growth in enterprise data, the data stall problem now grew from about 50% up to as high as 90%. A recent S&P Global Market Intelligence report showed 32% of AI practitioners say data management and delays are the top problems to overcome.
And so started the quest for consolidation to remove as much data stall and copying as possible.
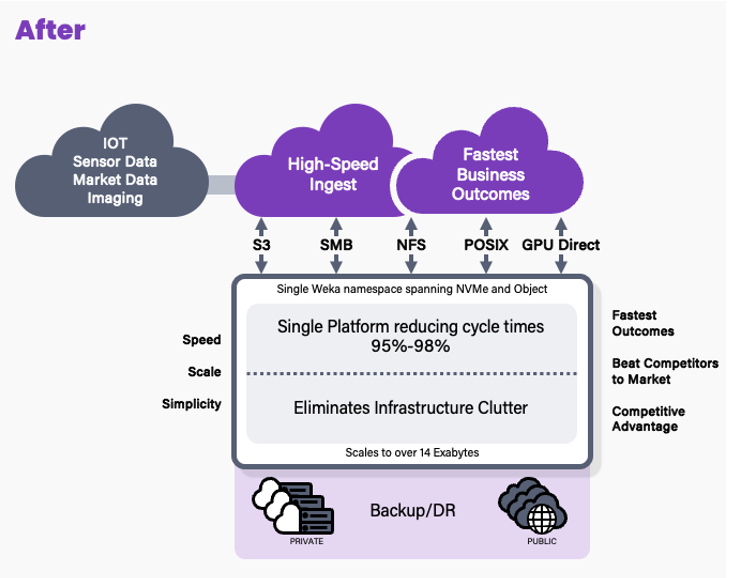
We started at Genesis, and now we’re into the exodus from old, siloed architecture into the new land of consolidation. Consolidation stops the data stall issue by removing the need to copy data around as much and centralizing it on a single platform. But consolidation also creates an IO issue that is much harder to deal with. When the data consolidation trend started, there was a clear advantage over data siloing, but is that still the case?
In Part 2 of this series, we’ll explore the implications of consolidating data and the impact on an AI data pipeline.
Popular Blogs From Joel Kaufman



Related Assets
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage