What is a GPU? Optimizing AI Infrastructure and Performance
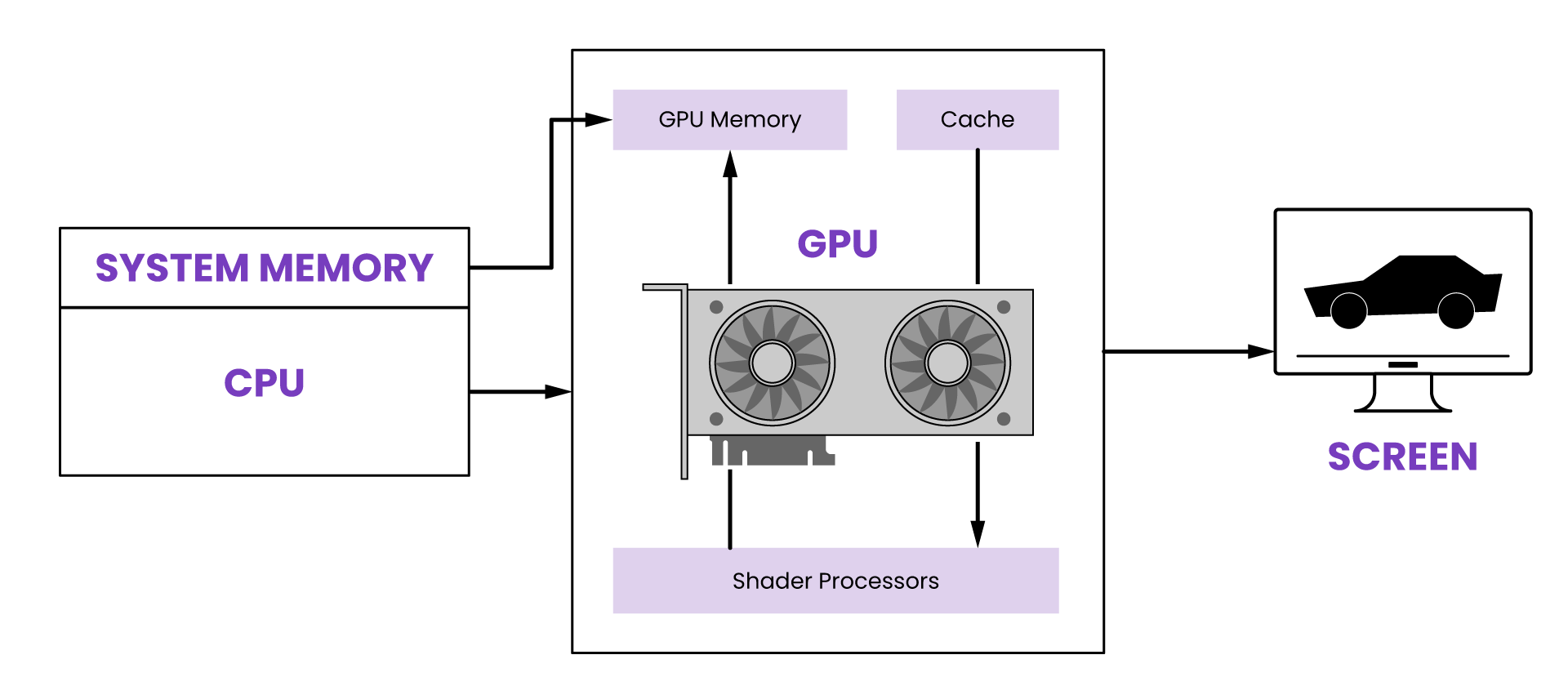
What is a GPU? The Foundation of AI Infrastructure
A GPU, meaning graphics processing unit, accelerates rendering images and videos on a device by design. Originally developed for rendering graphics in video games and computer-aided design (CAD) applications, GPUs have evolved to handle a wide range of parallel processing tasks.
What is a Graphical Processing Unit?
This is just another way of saying graphics processing unit.
What is a GPU Used For?
GPUs excel at performing repetitive calculations simultaneously, making them well-suited for parallel operations.
A common GPU example is graphics rendering. GPUs are central to rendering high-quality images and videos. They manage shading, lighting, and texturing to create realistic visuals in video games, movies, and other visual content.
However, there are many other GPU applications:
Machine learning and artificial intelligence (AI). GPU architecture supports deep learning applications such as image recognition and natural language processing.
Scientific computing. The function of graphics processing units in this area is to accelerate complex calculations, such as replications of physical processes, weather modeling, and drug discovery, in research trials and simulations.
Cryptocurrency mining. GPUs perform the complex mathematical calculations required to verify and add transactions to a blockchain for cryptocurrency mining.
Video editing and rendering. The parallel processing power of GPUs speeds up tasks like video editing, rendering graphics, and effects processing.
3D modeling and rendering. Professionals in industries like architecture and industrial design use GPUs to accelerate 3D modeling and rendering tasks.
How Does a GPU Work
A GPU functions best for tasks that involve large amounts of data and repetitive calculations:
Parallel architecture. Unlike the design of traditional central processing units (CPUs, see “GPU vs CPU” discussion below), GPU design involves a massive number of smaller processing units (cores) that can handle tasks in parallel—tasks that can be divided into many smaller subtasks to be processed simultaneously.
Data and task parallelism. GPUs excel at both data parallelism (performing the same operation on multiple data elements simultaneously) and task parallelism (performing different operations on different sets of data simultaneously.
Thread execution. Threads, small units of work that allow concurrent execution, are central to how GPUs work. A GPU handles thousands of threads simultaneously so it can efficiently process multiple tasks at once.
CUDA cores (NVIDIA) or stream processors (AMD). These are the fundamental processing units within a GPU, each capable of independently performing calculations. Modern GPUs have hundreds to thousands of these cores.
Memory hierarchy. The memory hierarchy of GPUs includes high-speed memory caches that minimize data access times to maintain high throughput during parallel processing.
Memory bandwidth. GPUs have high memory bandwidth designed to feed data to the numerous cores quickly and optimally utilize their processing power.
Shader units. These specialized processing units within a GPU handle specific tasks, such as vertex shading, geometry shading, pixel shading (fragment shading), and compute tasks. These units collectively contribute to rendering graphics and performing computations.
APIs and libraries. To efficiently utilize GPU power, software applications use programming interfaces like CUDA or OpenCL to manage and execute parallel tasks. These APIs provide tools and libraries so developers can create programs that efficiently leverage GPU capabilities.
Task distribution. Workloads in tasks like graphics rendering or scientific simulations are divided into many smaller tasks, each assigned to a different thread which the GPU then executes in parallel. This approach significantly speeds the overall processing time.
Is a GPU a Graphics Card?
Although people often use these terms interchangeably, there are differences between GPUs vs graphics cards. A graphics card (GPU) is a hardware component. It may be part of a graphics card or a different types of GPU.
However, graphics cards, also called video cards or GPU cards, are separate expansions that house the GPU as the primary processing unit, along with dedicated memory (VRAM), a cooling system, and other necessary components to render and display graphics on a computer monitor or other output devices. The graphics card connects to the motherboard and often includes display outputs to connect to monitors or other display devices.
The Data Storage Bottleneck
In high-performance AI environments, a Data Storage Bottleneck occurs when your storage architecture cannot deliver data at the same velocity that your GPUs can process it. While a modern GPU can execute billions of calculations per second, it remains ‘starved’ and underutilized if it is forced to wait for data to be retrieved from legacy storage silos or slow mechanical drives. This mismatch, often referred to as GPU starvation, results in wasted compute costs and stalled innovation. To maximize your return on investment in AI infrastructure, you must eliminate these I/O wait states by implementing a parallel data platform that provides the massive throughput and ultra-low latency required to keep GPU cores fully saturated throughout the entire training and inference cycle.
GPU Types
Various types of graphics processing units meet specific requirements and usage scenarios, from gaming to scientific research. Here are some of the most common types of GPUs:
Consumer graphics cards. These are designed for general consumer use, including gaming, multimedia, and everyday tasks, and come in various performance tiers from entry-level to high-end to meet different user needs and budgets.
Professional graphics cards (workstation GPUs). These are optimized for professional applications that require high accuracy and reliability such as 3D modeling, animation, CAD, video editing, and scientific visualization.
Mobile GPUs. These are optimized for power efficiency and thermal management while still providing reasonable graphics performance for mobile devices.
Server and data center GPUs. These are used in data centers and cloud computing environments for tasks like AI training, deep learning, scientific simulations, and virtualization. They are designed in tandem with high-performance computers and optimized for parallel processing.
AI accelerators. These specialized GPUs are designed for artificial intelligence and machine learning tasks and often include hardware optimizations for matrix operations and deep learning frameworks.
Ray tracing GPUs. GPUs with dedicated hardware for ray tracing enable real-time ray tracing effects in games and rendering applications.
General purpose GPU (GPU). GPUs are used for general-purpose computations beyond graphics in scientific research, simulations, data analysis, and other tasks that benefit from parallel processing capabilities. CUDA and OpenCL are programming frameworks for GPGPU.
Embedded GPUs. These GPUs are designed for embedded systems, to minimize size and optimize power efficiency and integration. Use cases include in-car entertainment systems, robotics, and IoT devices.
Legacy GPUs. Older or legacy GPUs may no longer be in active production but are still used in older systems. These GPUs may lack modern features and performance, but they can still handle less demanding tasks.
Cloud GPUs. Cloud computing platforms offer GPUs on-demand for users to rent that allow access to high-performance computing resources without the need to own physical hardware.
Integrated GPU
Built directly into the CPU, integrated GPUs are commonly found in laptops and smaller, lightweight desktop systems. The difference between integrated graphics vs GPUs is that integrated GPUs can handle basic graphics tasks and video playback but are typically less powerful than dedicated graphics cards.
Dedicated GPU
A dedicated GPU or dedicated graphics card is a hardware component designed specifically for graphics with its own dedicated memory (VRAM) and processing power. Unlike integrated graphics, share system memory, a dedicated GPU is significantly more powerful and well-suited for demanding graphics tasks, including gaming, content creation, and professional applications.
Discrete GPU
A discrete GPU is a separate, dedicated graphics card apart from the CPU. Discrete GPUs are designed specifically for graphics processing tasks and are distinct from integrated graphics, which are built into the CPU.
It is the next step beyond the dedicated GPU which can be integrated into the CPU or come as a discrete graphics card, but will always be designed specifically for graphics tasks and have its own resources. A discrete GPU is a standalone component known principally for high graphics performance.
What is an External GPU?
An external GPU is housed outside the device and connects via a high-speed interface. It is primarily used to enhance graphics performance, but there are other reasons to use an external GPU:
Flexibility. An external GPU allows upgrades to graphics capabilities without replacing an entire system.
High-performance connectivity. Because they require sufficient bandwidth to process graphics effectively, external GPUs typically use high-speed interfaces to connect to devices.
Compatibility. Designed to be compatible with a range of computers that support the external interface, it is possible to use an external GPU with various laptop models.
Plug-and-play portability. Modern external GPUs are often designed to connect and disconnect easily without needing to restart, offering more portability compared to desktop systems.
Upgradability. External GPUs have similar upgradability to desktop graphics cards.
VR and gaming. External GPUs have sufficient graphics power for virtual reality (VR) experiences and demanding games that might not run smoothly on integrated graphics.While external GPUs offer great advantages, they can also be more expensive compared to upgrading the internal graphics card of a desktop system. Additionally, actual performance improvement may be limited by factors such as CPU capabilities or bandwidth.
GPU Memory
GPU memory or video random access memory (VRAM) is used to store graphical data and computations. It helps render graphics, handle textures, and store frame buffers. In tandem with its processing power, GPU memory works to produce visuals. Data storage, speed of data access, texture mapping, memory type, memory bandwidth, and other factors also ultimately affect performance.
Dedicated vs Shared GPU Memory
The difference here is in how the GPU accesses and utilizes memory for graphics-related tasks, although the terms are often used in the context of integrated graphics and dedicated graphics cards.
Dedicated GPU Memory
Dedicated GPU memory is exclusively reserved for the GPU’s use. A dedicated GPU graphics card has its own separate memory chips that are used solely for storing graphics-related data, textures, frame buffers, and other graphical elements. Dedicated GPU memory is faster and more efficient to access, as it’s optimized for graphics processing tasks.
Shared GPU Memory
Shared GPU memory uses system memory (RAM) which can cause bottlenecks and limit performance, especially in graphics-intensive applications.
GPU vs CPU
The central processing unit (CPU) and GPU are optimized for different tasks. Here are the key differences between CPU and GPU:
Role and function. The CPU handles a broad range of tasks, and is not particularized in its focus, coordinating the overall functioning of the computer with its faster basic clock speed.
The GPU is specialized for graphics-related and parallel processing tasks like scientific simulations, machine learning and artificial intelligence. The advantages of GPU over CPU usually relate to these kinds of specialized applications.
Architecture. The CPU has a small number of powerful cores optimized for sequential processing and excels at complex calculations and decision-making. GPU architecture has a larger number of simpler cores optimized for parallel processing making it well-suited for tasks that can be broken down into many smaller operations.
Processing power. CPUs are designed for high single-thread performance to support tasks that cannot easily be parallelized. GPUs are designed for parallel processing to support tasks that involve massive amounts of data and simultaneous calculations.
Memory hierarchy. CPUs and GPUs each have their own memory hierarchy. The complex CPU memory hierarchy has various levels of cache, system memory (RAM), and storage devices, and is designed to minimize latency and optimize data access. The simpler GPU memory hierarchy includes only high-speed memory caches and VRAM and is optimized for rapid access to graphical data during rendering and parallel processing.
Software utilization. CPUs are versatile and can run many software applications, while GPUs are often utilized with specific programming frameworks and specialized for certain tasks.
GPU CPU Bottleneck
A CPU-GPU bottleneck, also called CPU-GPU bottlenecking, CPU bottlenecking GPU, or CPU-GPU bottleneck effect, refers to a situation where the performance of a computer system is limited or “bottlenecked” by the capabilities of either the CPU or the GPU, causing the other component to be underutilized and limiting overall system performance.
There are two possible CPU-GPU bottleneck scenarios:
CPU bottleneck. If the CPU is not powerful enough to keep up with the demands of the GPU, it can cause the bottleneck, meaning that the CPU is unable to feed data to the GPU quickly enough, leading to lower GPU utilization and reducing graphics performance.
GPU bottleneck. If the GPU is significantly powerful enough that it processes data much faster than the CPU can provide it, the GPU causes the bottleneck again leading to GPU underutilization, but in this case also limiting overall system performance.
The impact of a bottleneck depends on the specific tasks of the GPUs and CPUs. For example, a game that requires significant CPU processing to handle AI, physics calculations, and game logic and causes the CPU to struggle may be a sign that the GPU is not fully utilized, resulting in lower frame rates and less smooth gameplay. A balanced system with CPU and GPU of similar performance levels is a good way to reliably address CPU-GPU bottlenecks.
GPU Benchmarks
GPU benchmarks are standardized tests and measurements used to evaluate GPU performance under various conditions. These objective metrics allow users to compare the relative performance of different GPUs, and their results are usually presented in the form of scores, frame rates, or GPU benchmark comparisons.
Gaming benchmarks. These tests measure frame rates, graphics quality, and overall gameplay experience. Different games stress GPUs differently due to varying graphical demands.
Synthetic benchmarks. These synthetic tests simulate different graphical workloads and can include tasks like 3D rendering, particle simulations, and physics calculations.
Compute benchmarks. These focus on GPU computing capabilities, including ability to perform parallel calculations.
Ray tracing benchmarks. Benchmarks designed to test ray tracing performance measure how well a GPU handles ray tracing effects in games.
Virtual reality (VR) benchmarks. VR benchmarks evaluate a GPU’s performance in VR applications, including frame rates, responsiveness, and overall VR experience.
Power and thermal benchmarks. These measure power consumption and thermal performance under load, which can be valuable for understanding efficiency and cooling requirements.
Multi-GPU benchmarks. In systems with multiple GPUs, benchmarks assess scalability and performance gains.
Advantages and Disadvantages of GPUs
We have already covered many of the advantages of GPUs above in their specialized applications. However, here are a few more to consider:
Energy efficiency. For some applications, particularly in data centers and supercomputing environments, GPUs may offer higher per watt performance compared to traditional CPUs.
Scalability. Some tasks benefit from using multiple GPUs in a system for additional parallel processing power.
Cost-effective solutions. GPUs are cost-effective for a wide range of computational tasks without the need for custom hardware or specialized processors.
There are also some disadvantages of GPUs:
Limited single-thread performance. GPUs excel at parallel processing, but their individual cores are less powerful than CPU cores for single-threaded tasks, so they are less suitable for tasks that cannot be easily parallelized.
Memory constraints. GPU memory is typically limited compared to system memory (RAM), which can hamper tasks that require extensive memory access.
Programming complexity. Writing software to fully utilize GPU capabilities can be complex, requiring knowledge of specialized programming languages and frameworks.
Compatibility and driver issues. These can arise when using GPUs with certain applications or operating systems and keeping drivers up-to-date is crucial for optimal GPU performance.
Not universally beneficial. Not all tasks and applications benefit equally from GPU acceleration; some are better suited for CPU processing due to their nature and requirements.
Frequently Asked Questions (FAQ)
GPU starvation occurs when your data storage architecture cannot deliver data fast enough to saturate the GPU’s parallel processing cores. In large-scale AI training and inference, this causes the GPUs to sit idle (I/O wait states), leading to increased project costs, wasted compute power, and significantly slower time-to-market for AI models.
While CPUs handle sequential tasks, GPUs feature a massive parallel architecture designed to process thousands of data elements simultaneously. Because GPUs are exponentially faster at computation, they require massive data throughput and ultra-low latency from the storage layer to maintain peak efficiency.
Solving these bottlenecks requires moving away from legacy storage silos. Implementing a software-defined, parallel data platform like WEKA allows for high-performance data access, ensuring that even the most demanding AI and HPC workloads can scale without the storage layer becoming a performance “choke point.”
Yes. Beyond graphics, GPGPU (General-Purpose Computing on Graphics Processing Units) uses frameworks like CUDA and OpenCL to leverage parallel processing for complex scientific simulations, financial modeling, and drug discovery—all of which rely on high-speed data access to stay performant.
Unlock Your GPU Potential with WEKA
Born in the cloud, the WEKA Data Platform is a software solution that ensures you can constantly saturate your GPUs doing the model training by providing the highest throughput at the lowest latency. The more data a deep learning model can consume and learn from, the faster it can converge on a solution, and the greater its accuracy will be.
WEKA collapses the typical GPU-starving “multi-hop” AI data pipeline using a single namespace where your entire data set is stored. This zero-copy architecture eliminates the multiple steps needed to stage data before training. Your GPUs gain fast access to data needed for training, while WEKA automatically manages tiering of data between high-performance, NVMe-based storage, and low-cost object storage. Incorporating the WEKA Data Platform for AI into deep learning data pipelines saturates data transfer rates to NVIDIA GPU systems. It eliminates wasteful data copying and transfer times between storage silos to geometrically increase the number of training data sets that can be analyzed per day.
The WEKA Data Platform efficiently handles large numbers of files creating virtual metadata servers that scale on the fly with every server that is added to the cluster. WEKA’s patented data layout algorithms distribute and parallelize all metadata and data across the cluster in small 4k chunks, this creates incredibly low latency and high performance whether the IO size is small, large, or a mixture of both. Because the WEKA Data Platform is software-defined, the same technology is used on-premises or in the cloud, providing you the same benefits and user experience.
Recommended Resources



Related Assets
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
Microsoft Azure and WEKA’s Answer to Storage Bottlenecks

Microsoft Azure and WEKA’s Answer to Storage Bottlenecks
-
The NAND Flash Shortage Survival Guide

The NAND Flash Shortage Survival Guide