Introduction to HPC: What are HPC & HPC Clusters?
This is a 3-part series on High-Performance Computing (HPC):
Part 1: Introduction to HPC & What is an HPC Cluster?
Part 2: What is HPC Storage & HPC Storage Architecture
Part 3: HPC Storage Use Cases
Introduction to High-Performance Computing (HPC) and HPC Systems
Leaders across diverse industries such as energy exploration and extraction, government and defense, financial services, life sciences and medicine, manufacturing, and scientific research are tackling critical challenges using HPC computing. HPC is now integrated into many organizational workflows to create optimized products, offer insights into data or execute other essential tasks.
Given the breadth of domains using HPC today, a flexible solution for a range of computing services, storage, and networking requirements is what many organizations require to design and implement efficient infrastructure and plan for future growth. Many organizations may use HPC in multiple industries, which demands flexibility in computing, storage, and networking. For this reason, there is a range of HPC storage solutions available today.
The market for HPC servers, applications, middleware, storage, and service was estimated to be $27B in 2018 and will grow at a 7.2% CAGR to about $39B in 2023. In 2023, HPC storage alone will grow from an estimated $5.5B in 2018 to $7.8B.
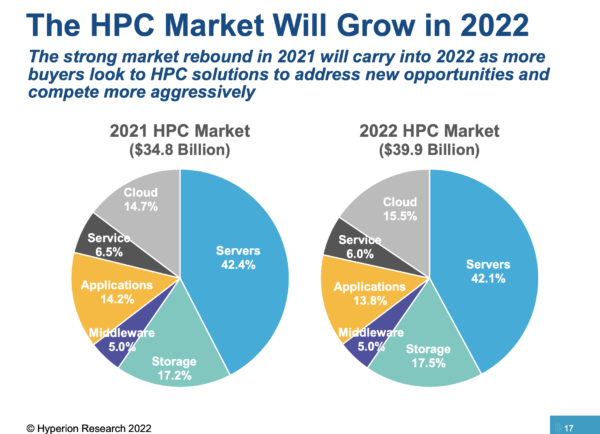
The infrastructure of an HPC system contains several subsystems that must scale and function together efficiently: compute, storage, networking, application software, and orchestration.
- Compute: The compute portion of an HPC system runs the application, takes the data given to it, and generates an answer. Over the past 20 years, most algorithms have been parallelized, meaning the overall problem is broken up into many parts, with each run on a separate computer or core. Periodically the resulting answers or partial answers must be communicated with the other calculations or stored on a device. Modern servers contain two to four sockets (chips), each with up to 64 cores. Since each core may need to store recently computed information, the demands on the storage device may increase as core counts increase.
- Storage: Massive amounts of data are needed to start a long-running simulation or keep it running. Depending on the algorithm, the application may require more data as it runs as well. For example, when simulating the interaction of different drug molecules, thousands of molecular descriptions will have to be ingested at once. As the application runs, more of these descriptions may merit investigation, requiring a low latency and high bandwidth storage infrastructure. In large installations, the amount of online hot storage may be in the Petabyte range. HPC storage is a key component of any smooth and efficiently run high-performance computing cluster.
- Networking: Communications between the servers and storage devices should not limit the overall performance of the entire system. Each core that is performing computations may need to communicate with thousands of other cores and request information from other nodes. The network must handle this server-to-server and server-to-storage system communication by design.
- Application Software: Software that simulates physical processes and runs across many cores is typically sophisticated. This complexity lies not just in the mathematics underlying the simulation, but also in the reliance on highly tuned libraries to manage the networking, work distribution, and input and output to storage systems. The application must be architected to keep the overall system busy to ensure the high-performing infrastructure offers a high return on investment.
- Orchestration: Setting up a part of a large cluster can be challenging. A massive supercomputer will rarely have the entire system dedicated to a single application. Therefore, software is needed to allocate a certain number of servers, GPUs if needed, network bandwidth, and storage capabilities and capacities. All of these sub-systems, as well as the installation of an Operating System (OS) and associated software on the allocated notes, needs to be handled seamlessly and effortlessly. Setting up the software for HPC data storage is critical for applications that require fast data access.
How Does HPC Work?
It is important to see the differences in how HPC works and how a standard computing system operates. The standard system solves problems principally by dividing the workload into tasks, and then executing them in sequence on one processor—serial computing.
In contrast, HPC leverages several powerful tactics and tools: parallel computing, HPC clusters, and high-performance resources and components.
Parallel computing: By running multiple tasks on multiple computer servers or processors simultaneously using tens of thousands to millions of processors or processor cores, an HPC system achieves much greater speed.
HPC clusters: An HPC cluster consists of multiple high-speed computer servers, called nodes, networked together. Just one HPC cluster may include over 100,000 nodes.
High-performance computing resources and components: In pace with the rest of the HPC cluster’s performance, the other computing resources—file systems, memory, networking, and storage—are high-throughput, high-speed, and low-latency to optimize computing power.
HPC Architecture Explained
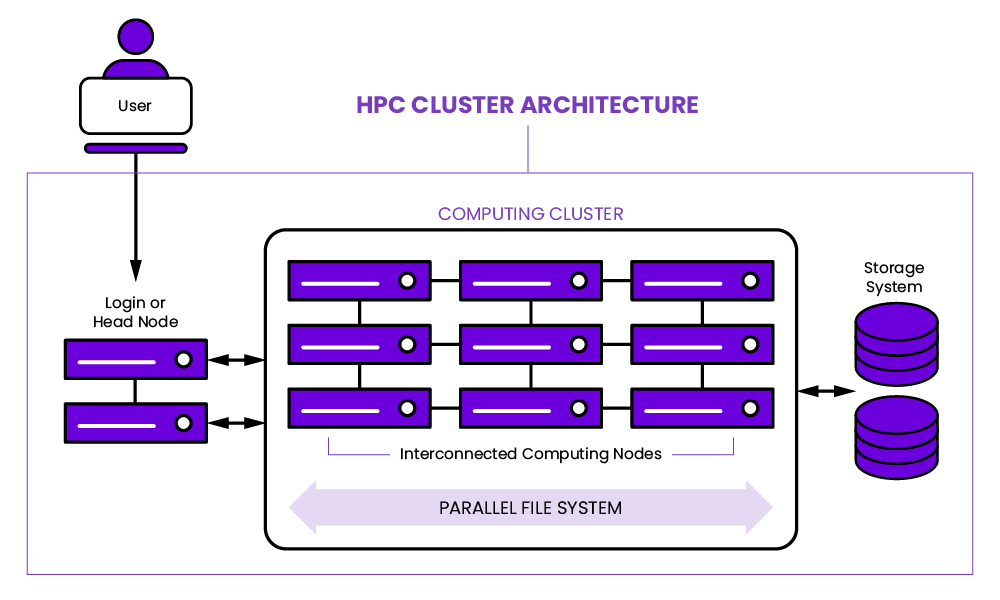
HPC cluster architecture consists of multiple computer servers networked together to form a cluster that offers more performance than a single computer.
How does HPC architecture differ from traditional computing architecture?
Although consumer-grade computers can share GPU computing, hardware acceleration, and many of the same techniques that HPC systems do, there are major differences between HPC and traditional computing systems. Especially in areas where HPC is essential to operations, computing and processing power from HPC systems is exponentially higher than traditional computers.
This difference is particularly acute for throughput, scaling speed, and processing. Thus HPC architecture tends to serve as the foundation for the cloud. However, HPC architectures can take various forms—most often cluster, parallel, and grid systems.
Cluster Computing Architecture: A cluster is a set of multiple computers that together operates as a single entity, called a node, to collectively work on the same set of tasks.
Parallel Computing: With a parallel computing configuration, nodes are arranged to execute calculations or commands in parallel similar to GPU processing to scale computation volume and data processing across a system.
Grid Computing: Grid computing systems distribute parts of a more complex problem across multiple nodes.
What is an HPC Cluster?
HPC meaning: An HPC cluster is a collection of components that enable applications to be executed. The software typically runs across many nodes and accesses storage for data reads and writes.
Typically, HPC cluster components include:
- Head or Login Node: This node validates users and may set up specific software on the compute nodes.
- Compute Nodes: These perform numerical computations. Their persistent storage may be minimal, while the DRAM memory will be high.
- Accelerator Nodes: Some nodes may include one or more accelerators, while smaller HPC clusters, purpose built for a specific use may be set up where all nodes contain an accelerator.
- Storage Nodes or Storage System: An efficient HPC cluster must contain a high performance, parallel file system (PFS). A PFS allows all nodes to communicate in parallel to the storage drives. HPC storage allows for the compute nodes to operate with minimal wait times.
- Network Fabric: In HPC clusters, typically low latency and high bandwidth are required.
- Software: HPC cluster computing requires underlying software to execute applications and control underlying infrastructure. Software is essential to the efficient management of the massive amounts of I/O that are inherent to HPC applications.
What are the Core/Basic HPC Cluster Components
High performance computing (HPC) generally processes complex calculations at high speeds in parallel over multiple servers in groups called clusters. Although hundreds or even thousands of compute servers may be linked in an HPC cluster, each component computer is still referred to as a node.
HPC solutions may be deployed in the cloud or on-premises. Flexibility is key. A typical HPC solution has 3 main components:
- Compute
- Network
- Storage
Compute
Compute hardware includes a dedicated network with servers and storage and focuses on algorithms, data processing, and problem solving. In general, a minimum of three servers must be provisioned as primary, secondary, and client nodes. more available to the cluster if you virtualize multiple servers.
The networking infrastructure to support the compute power demands high-bandwidth TCP/IP network equipment, such as NICs, Gigabit Ethernet, and switches. Typically, the HPC cluster is managed by the software layer, including tools for monitoring and provisioning file systems and executing cluster functions.
Network
Reliable, rapid networking is critical to successful HPC architecture, whether for moving data between computing resources, ingesting external data, or transferring data between storage resources. Physical space is needed to house HPC clusters, and sufficient power is necessary to operate and cool them.
Storage
Cloud storage offers high volume and speeds for access and retrieval, making it integral to the success of an HPC system. Traditionally, external storage has been the slowest piece of a computer system, but HPC storage meets the rapid needs of HPC workloads.
Other Aspects of HPC Architecture
HPC Schedulers
An HPC scheduler is specialty software that orchestrates how nodes work on an HPC cluster. An HPC system always has some form of dedicated HPC scheduling software in place.
GPU-Accelerated Systems
Although this isn’t an essential component of HPC architecture, accelerated hardware is common, especially in larger systems. GPU acceleration provides parallel processing to support large-scale compute. In turn, these accelerated clusters can support more complex workloads at much faster speeds.
Data Management Software
Underlying networking, file, and management system resources must be handled by a specifically optimized software system that directs management operations such as moving data between HPC clusters and long-term cloud storage.
Given these diverse components, it is clear that HPC infrastructure may include on-premise, cloud, or hybrid configurations—depending on the needs of the user. Cloud infrastructure remains, however, a critical component of some of the most demanding industries and workloads.
A Glance at HPC Cluster Design
With these essential elements in mind, let’s move on to HPC Cluster Design and how to build HPC clusters to specifications. We will approach this piece by piece.
HPC Cluster Configuration Explained
An HPC cluster is many separate computers or servers called nodes collected together and connected via some high-speed means. Different types of nodes may handle different types of tasks.
- As explained above, typical HPC clusters have:
- A login or headnode node
- A data transfer node
- Compute nodes, some with fat compute nodes with a minimum of 1TB of memory
- Graphical Processing Unit (GPU) nodes for computations
- Connecting switch for nodes
And while all cluster nodes share the same memory, CPU cores, and disk space as a laptop or desktop, the difference is in the quality, quantity, and power of the components—and their resulting applications.
What is HPC Storage?
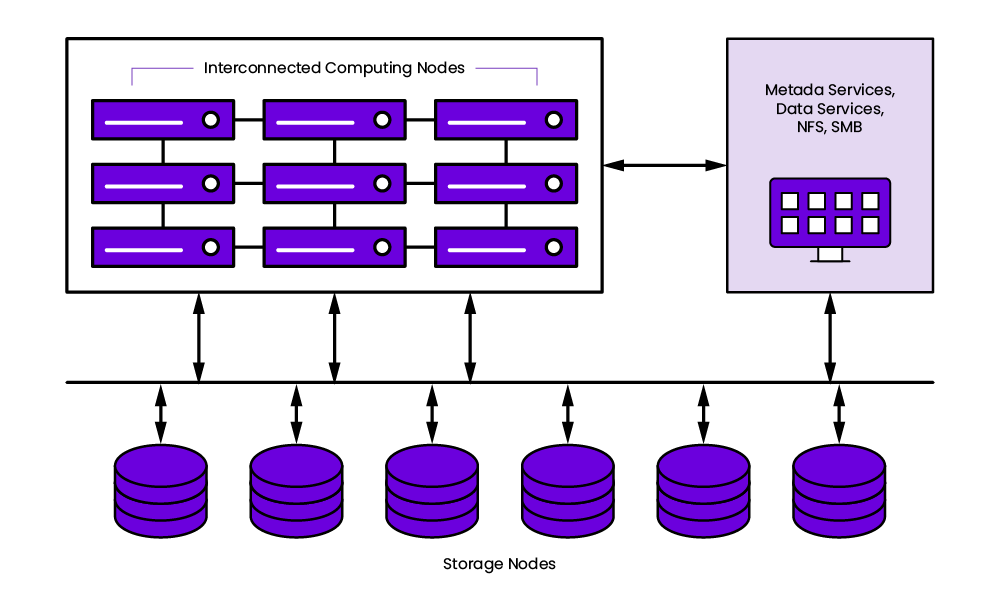
Most HPC storage solutions are file-based with POSIX support. These file-based HPC storage solutions can typically be divided into general purpose and parallel storage solutions.
While some solutions such as Blob (Binary Large Objects) storage or object storage can be used directly by some workloads, not all share that capability.
General-purpose storage
General-purpose storage in a HPC cluster is used to store available application binaries with their libraries to maintain consistency while an application runs. It is also used for consistent access to user data such as home directories throughout the HPC cluster.
Parallel file systems
A parallel or clustered file system is a shared file system multiple users access at once which serves the storage resources of multiple servers simultaneously. This direct client access to stored data avoids abstraction and eliminates overhead, resulting in high performance and low latency.
- Solutions in this space include:
- WEKA
- Ceph via CephFS
- BeeGFS
- Lustre / DDN Lustre
- DAOS
- GPFS / IBM Spectrum Scale
- VAST Data
- Panasas PanNFS
However, these are not always equally well-suited for artificial intelligence (AI)/machine learning (ML) or similar workloads.
Many parallel file systems such as Lustre and IBM Spectrum Scale (also called GPFS), separate data and metadata into distinct services. This enables HPC clients to communicate directly with storage servers and provides a significant improvement for large file I/O performance.
However, the metadata services become the bottleneck in these scenarios. This is mainly because newer workloads such as those for analytics and IoT are small file (4KB and lower) and metadata intensive.
In a Lustre environment, the MDS size is central to the average file size for storage on the system. The default inode size is 1,024 bytes for the MDT and 512 for the OST. A file system must have at least twice as many inodes on the MDT as it has on the OST or it will run out of inodes, and the file system will be full—even though physical storage media space may be available.
Each time a file is created in Lustre it consumes one inode—regardless of file size. Many AI workloads produce billions of tiny files which consume inodes rapidly. The result is a “full” file system despite physical storage capacity that is only partially used up. For an excellent example of a file system being “full” while only using 30% of the disk space, see this Lustre forum.
Poor metadata performance is an additional challenge. AI and ML workloads require small file access with low latency. The Lustre file system was built for large file access, which manages initial file request latency well.
NASA’s Pleiades Lustre knowledge base best practices include:
- Limiting the files in each directory
- Avoiding “stat” operations
- Placing small files on an NFS mount rather than Lustre where possible
- Placing small files in a dedicated directory so each file needs only one OST
- Avoiding repetitive open and close operations to minimize metadata operations
In other words, it is an ongoing challenge to minimize metadata operations and maintain performance in Lustre for these applications.
In contrast, WEKA is a modern parallel file system that was released in 2017 to address I/O intensive workloads that require massively parallel access and huge metadata performance demands. WEKA was purpose-built to leverage flash-based technology, delivering ultra-low latency and excellent small file performance.
Unlike Lustre and many other parallel systems, which have been optimized for hard disk-based storage and prefer 1MB file size, the WEKA file system strips every file into 4KB chunks and serves them back in parallel. For WEKA, every file problem is a small file problem—and that’s why it manages tiny file performance so effectively.
WEKA has also solved the metadata choke point which too often cripples these systems. The early design of data and metadata separation alleviated many of the legacy NAS issues, but it also created a new bottleneck for modern workloads.
WEKA spreads data and metadata across all nodes in the storage cluster equally, solving the metadata performance issue. Each WEKA node provides metadata services, data services, NFS and SMB access and internal tiering to S3-based object storage for massive scalability.
This greatly simplifies infrastructure while ensuring that performance on small file and metadata is orders of magnitude better than what the Lustre design delivers. And even as the need to add more nodes arises, there is no need to add a complex inode setup in order to scale to the size required by the application.
HPC Storage Architecture Overview
Architecting efficient storage capabilities for an HPC cluster can be daunting. There are several critical features that need to be designed into this system, including the simplicity of installing the software needed to satisfy these requirements. It is essential to remove the complexity and tuning from the server orchestration needed for efficient I/O of the data.
To ensure legacy parallel file systems are functional, a significant amount of infrastructure knowledge and systems expertise is required. This involves installing different software on metadata servers (MDS), metadata targets (MDT), object storage servers (OSS), and object server targets (OST). It also includes installing different services on different physical servers—and all of this demands a strong understanding of the overall HPC cluster architecture.
Legacy systems must be modified and updated continuously to access modern storage technologies. Modern servers often contain SSD drives, which offer significant performance advantages for HPC workloads over HDD drives. An HPC workload storage architecture should be able to service computer cluster requests and leverage SSD drive performance.
Additionally, some HPC applications must frequently access “hot” data, while “cold” data can be accessed less frequently. The system will keep the hot data close to the compute nodes on SSDs but may retain cold data in an object storage array.
An HPC architecture also fully distributes data and metadata services to simplify the management process for the overall environment. Metadata services always remain available, regardless of the tier the data rests on. Integrating object storage and NVMe drives into an HPC storage system achieves responses to application requests with higher bandwidth and lower latency.
The benefits of this sort of architecture are that critical, often-used data is stored close to the compute nodes, while less expensive storage devices should be used for less active data. Users can then create policies to automatically move data between the tiers, optimizing for specific data access patterns and use cases. By leveraging a broad range of storage devices, a modern HPC storage system architecture can store exabytes of data while responding with millisecond latencies as needed.
Advantages of HPC
The benefits of HPC assists users in surmounting challenges they face using conventional PCs and processors. HPC benefits include the following:
High speed
HPC delivers extremely fast processing, so HPC systems can rapidly perform massive numbers of calculations that regular computing systems would take days, weeks, or months to perform. HPC systems typically improve computing performance and processing speeds with block storage devices, modern CPUs, GPUs, and low-latency networking fabrics.
Lower costs
Faster processing and answers from an HPC system typically means saving time and money. And many such systems are in “pay as you go” format as well.
Reduced physical testing requirements
Often, modern applications such as self-driving cars demand extensive physical testing before commercial release. Application developers, researchers, and testers can use HPC systems to create powerful simulations, thus minimizing or even eliminating the need for costly physical tests.
Disadvantages of HPC
Despite impressive recent progress in the realm of HPC systems, some barriers to widespread HPC adoption remain:
Cost – While cloud infrastructure has made HPC more affordable, it is still an investment— in terms of money and time. And both upfront costs and the costs of managing HPC infrastructure over the long term are part of the equation.
Compliance – HPC and data systems upkeep must naturally incorporate any regulations and compliance. For example, an organization that focuses on life sciences developing HPC cloud applications that touch Personal Health Information (PHI) in any way must manage a complex set of compliance standards in the system.
Security and Governance – Outside of industry regulations, your organization will adopt data governance policies to help manage data in storage and during its time processed in an HPC environment. Additionally, your data governance will also include whatever security measure you must implement. Cybersecurity applies to all aspects of your high-performance computing environment, from networking to storage and computation.
Performance – An HPC environment needs tuning for optimal performance. Given the complexity of computing and cloud systems, there are dozens of tiny inefficiencies that can impact performance significantly.
What is High Performance Computing Used For?
Although there is no single use case or strict set of best practices for how to use HPC clusters, there are some common HPC use cases:
Artificial Intelligence (AI)/Machine Learning (ML). HPC applications are synonymous with AI apps and big data generally, and specifically with deep learning and machine learning (ML).
Healthcare, genomics and life sciences. What once took 13 years—sequencing a human genome—can now be done in less than a day by HPC systems. Other HPC applications in healthcare and life sciences include precision medicine and rapid cancer diagnosis, drug discovery and design, and molecular modeling.
Financial services – Along with fraud detection and automated trading, HPC powers high-performance simulation and other risk analysis, data analytics for real-time stock trading and financial services, and data and market analysis, etc. Users deploy HPC systems to identify hedging opportunities, product portfolio risks, and areas for optimization while modeling the impact of portfolio changes.
Defense, government, and administration – Rapidly growing HPC use cases in this area are intelligence work, energy research, and weather forecasting and climate modeling.
Energy – Often overlapping with defense and government, energy-related HPC applications include reservoir simulation and modeling, wind simulation, seismic data processing, geospatial analytics, and terrain mapping.
Additional HPC use cases include:
- Computational fluid dynamics for use in the aerodynamic design of aircraft, weather prediction, and similar applications
- Automated driving systems
- Cyber security
- Affinity marketing
- Business intelligence
- Internet of Things (IoT)
High Throughput Computing (HTC) vs HPC high performance computing
High throughput computing or HTC tasks are similar to HPC tasks in that they demand large amounts of computing power, but they typically extend over far longer periods of time (months and years, versus hours or days).
Enabling the Future of HPC in Cloud
Within the past ten years, the high cost of HPC and cloud computing necessarily included leasing or buying a location for an HPC cluster in an on-premises data center—keeping HPC cloud computing out of reach for most organizations.
But now this is completely different, as HPC in the cloud—sometimes called HPC as a service, or HPCaaS—offers a notably more scalable, faster, and more affordable way to leverage HPC. In general, HPCaaS includes access to HPC clusters and cloud-hosted infrastructure plus HPC expertise and ecosystem capabilities like data analytics and AI.
Several converging trends are driving the future of HPC applications in the cloud:
Surging demand – Across industries, organizations are becoming increasingly dependent on real-time insights and the competitive advantages that result from solving complex problems. For example, credit card fraud detection is something virtually everyone relies on. Modern fraud detection technology demands HPC to reduce the number of irritating false positives and identify real fraud more quickly, even as fraud activity expands and fraudsters’ tactics change constantly.
Emergence of viable lower-latency, higher-throughput RDMA networking – Remote direct memory access (RDMA) enables networked computers to access the memories of other networked computers without interrupting processing or otherwise involving either operating system. This helps minimize latency and maximize throughput, essentially making cloud-based HPC possible.
Widespread availability of public-cloud and private-cloud HPCaaS – HPC solutions and services are now widespread among all leading public cloud service providers.
Cloud adoption and container technologies are both central to HPC. Moving into the cloud is critical to transitioning away from an on-premise-only approach to a decoupled infrastructure. Containers offer automation, reliability, scalability, and security, improving performance of many HPC applications at low cost. They also provide the ability to package, migrate, and share application code, dependencies and even user data across multiple locations—and they are HPC system and cloud provider agnostic.
Hybrid use of local and public cloud-based resources is popular in the HPC space, giving users the benefits of control and cost optimization with the extreme scalability of public cloud-based clusters. By nature, hybrid cloud HPC use holds challenges associated with both public and private cloud use though it may also deliver the benefits of both solutions. In this way, it offers a complementary solution with increased complexity but greater overall resiliency.
WEKA provides the infrastructure necessary to empower high-performance workloads across any technical and scientific field, from AI and machine learning to manufacturing and life sciences. That is because we’ve created a comprehensive and purpose-built system with the following features:
- Streamlined and fast cloud file systems to combine multiple data sources into a single HPC system
- Industry-best, GPUDirect Performance (113 Gbps for a single DGX-2 and 162 Gbps for a single DGX A100)
- In-flight and at-rest encryption for GRC requirements
- Agile access and management for edge, core, and cloud development
- Scalability up to exabytes of storage across billions of files
Contact us to learn why high performance computing isn’t out of reach and how we can bring HPC infrastructure to your organization.
References:
1–https://www.slideshare.net/insideHPC/hyperion-research-hpc-market-update-from-isc-2019
You may also like:
Recommended Resources



Related Assets
-
The Buyer’s Guide to Modern Storage

The Buyer’s Guide to Modern Storage
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
Buyer’s Guide: Modern Storage for Financial Services

Buyer’s Guide: Modern Storage for Financial Services