HPC Storage Explained
This is a 3-part series on High-Performance Computing (HPC) Storage:
Part 1: Introduction to HPC & What is an HPC Cluster?
Part 2: What is HPC Storage & HPC Storage Architecture
Part 3: HPC Storage Use Cases
What is HPC Storage, And Why Is it so Important?
Saving your Word document or Excel spreadsheet to your laptops’ disk driver (either SSD or HDD) is a relatively simple task. The amount of data to be stored would max out at just a few megabytes (MB). However, in HPC, data to be read from or written out to the storage system may be on the order of exabytes (EB), which is a thousand million times more. The I/O to storage system should be offloaded from the CPU as much as possible as not to interrupt the valuable computations that are being performed. HPC storage systems allow for the CPUs to keep busy while the data is efficiently written to or read from disk drives.
The requirement for this massive retrieval and storage of data requires a different approach to HPC storage. Only using small direct-attached storage on each server that is only accessible to that individual server will not suffice. A modern parallel file system with a global namespace is needed that satisfies the following demands:
- Any data is available to any node at any time
- The data delivered is always the most recent available
- Takes advantage of the latest in storage technology, SSDs
- Can handle both large and small size data requests
- Scale with constant latencies as the capacity grows, in the millisecond range
- Supports the most popular and the most performance-oriented protocols.
HPC Storage Architecture
Architecting for efficient storage capabilities for an HPC cluster can be daunting. As stated above, there are several critical features that need to be designed into this system, not thought about afterward. High on this list is the simplicity of installing the software required to satisfy the above requirements. Removing complexity and tuning from the orchestration of the servers needed for efficient I/O of the data is of high importance. A goal of HPC storage software is to remove the complexity from the system administrator or developer.
Legacy parallel file systems require a significant amount of systems expertise and infrastructure knowledge to be installed just to get functional. The tasks would include installing different software on metadata servers (MDS), metadata targets (MDT), object storage servers (OSS), an object server targets (OST). Different services need to be installed on different physical servers. Performing these tasks can easily lead to operator mistakes and exposing the lack of understanding of the overall HPC cluster architecture. The following diagram (Figure 1) provides an overview of a typical deployment of the Lustre File system, an open-source parallel file system. This simplified view shows the many services that have to be configured, each requiring separate management. Large HPC environments frequently require significant investment in IT resources to keep operational due to the many moving parts. Figure 1 shows a complex hpc storage environment using the Lustre file system.
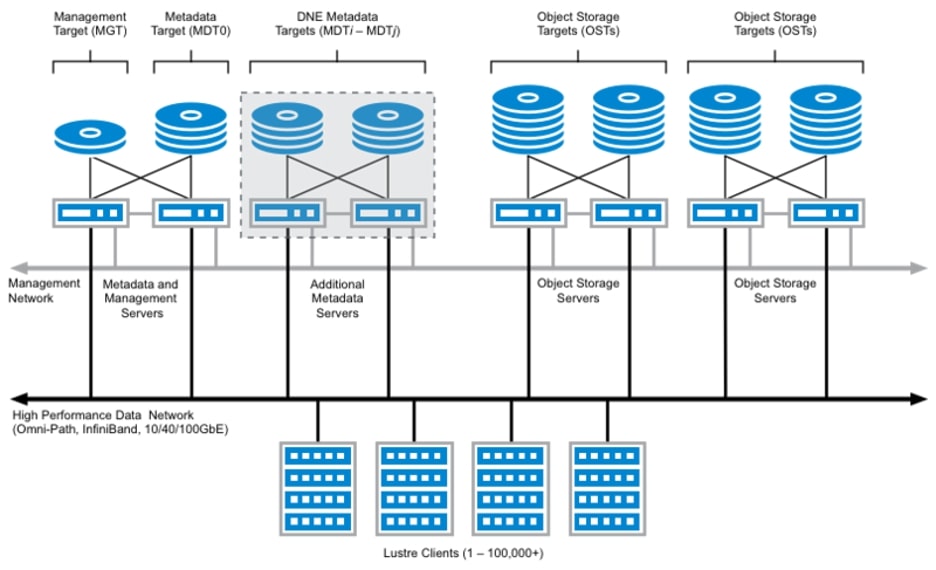
Figure 1: A Lustre Storage System – Courtesy of Lustre.org (reference 2)
These legacy systems continuously need to be updated and modified to take advantage of the latest in storage technologies. It is a complex undertaking for these legacy parallel file systems to incorporate SSDs, for example, when only upgrading a few systems out of many. All the software must be updated to recognize that specific storage devices contain more capable disk drives, and this can get complex.
Many modern servers contain SSD drives, which have significant performance advantages for HPC workloads over HDD drives. An overall storage architecture for HPC workloads needs to take advantage of the performance of the SSD drives and be able to service any requests from the compute cluster. Additionally, some HPC applications will have “hot” data that needs to be accessed frequently and “cold” data, which might only be read or used infrequently. The hot data needs to be kept close to the compute nodes on SSDs while the cold data can reside in an object storage array. Additionally, data and metadata services are fully distributed making the process of managing the overall environment simpler. A modern parallel file system architecture for a range of HPC workloads would look something like the following diagram (Figure 2) integrating hot and cold tiers, with scalable data and metadata servers. An essential piece of this modern design is that metadata services are always available, whether the data is on the hot or cold tier. Integrating NVMe drives and object storage into an HPC storage system the ability to respond to application requests with low latency and high bandwidth.
Figure 2: A modern parallel file system architecture, leveraging NVMe and object storage
The benefits to an architecture like this are that critical and often used data is stored close to the compute nodes, while less expensive storage devices should be used for less active data. Policies can then be set to automatically move data between the tiers, optimizing for specific use cases and data access patterns. By taking advantage of the range of storage devices, a modern HPC storage system architecture will respond with millisecond latencies when needed, yet can store exabytes of data as well.
With the emergence of GPUs to accelerate certain applications, the data access needs are increased. More computation (more computing elements) requires more retrieval and storage of data. Just as more cores on the main CPU contribute to more storage access, so do more GPU cores.
References:
2 – http://wiki.lustre.org/File:Lustre_File_System_Overview_(DNE)_lowres_v1.png
Additional Helpful Resources
FSx for Lustre
HPC Architecture Explained
HPC Cloud
BeeGFS Parallel File System Explained
Learn About HPC Storage, HPC Storage Architecture and Use Cases
Worldwide Scale-out File-Based Storage 2019 Vendor Assessment Report
5 Reasons Why IBM Spectrum Scale is Not Suitable for AI Workloads
Isilon vs. Flashblade vs. WEKA
Gorilla Guide to The AI Revolution: For Those Who Are Solving Big Problems
NAS vs. SAN vs. DAS
Network File System (NFS) and AI Workloads
Hybrid Cloud Storage Explained
Block Storage vs. Object Storage
Recommended Resources



_lowres_v1.png){kind=link}
Related Assets
-
The Buyer’s Guide to Modern Storage

The Buyer’s Guide to Modern Storage
-
Microsoft Azure and WEKA’s Answer to Storage Bottlenecks

Microsoft Azure and WEKA’s Answer to Storage Bottlenecks
-
The Buyer’s Guide to Modern Storage for Healthcare and Life Sciences Organizations

The Buyer’s Guide to Modern Storage for Healthcare and Life Sciences Organizations