The Challenge of IO for Generative AI: Part 4

IO Patterns in Different Types of AI Workflows
In the first 3 parts of this series, we’ve looked at the history of HPC and AI and siloing of storage, how consolidating data pipelines onto one data platform solved siloing issues but generated other problems, and then how sections of a GenAI pipeline can be impacted by hidden IO in the form of metadata. Now in part 4, we look at several WEKA customer use cases, analyzing what IO is happening and coming to some conclusions. WEKA is helping many of the world’s leading GenAI companies accelerate their GenAI workloads, and these use cases vary across several industries and AI/GenAI types. The data and graphs shown are directly from WEKA Home telemetry. WEKA Home is a cloud-based phone-home support and analysis tool where customers can manage their WEKA environments.
First up is a Natural Language Processing (NLP) use case. This GenAI customer is building AI models to support voice-to-text and voice-to-action capabilities.
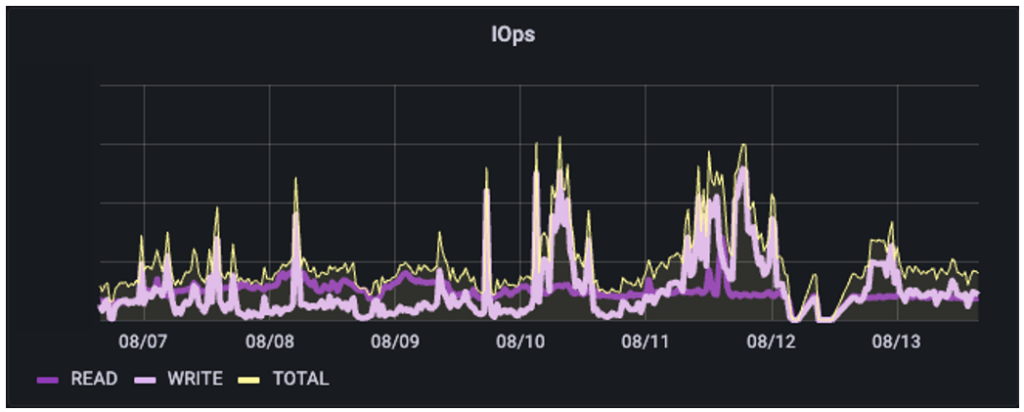
In this environment, we see that this is a fully blended mixed IO pipeline consisting of relatively consistent numbers of reads with spikes of IO on writes. This information can be mapped to how heavily loaded the WEKA backend servers are.
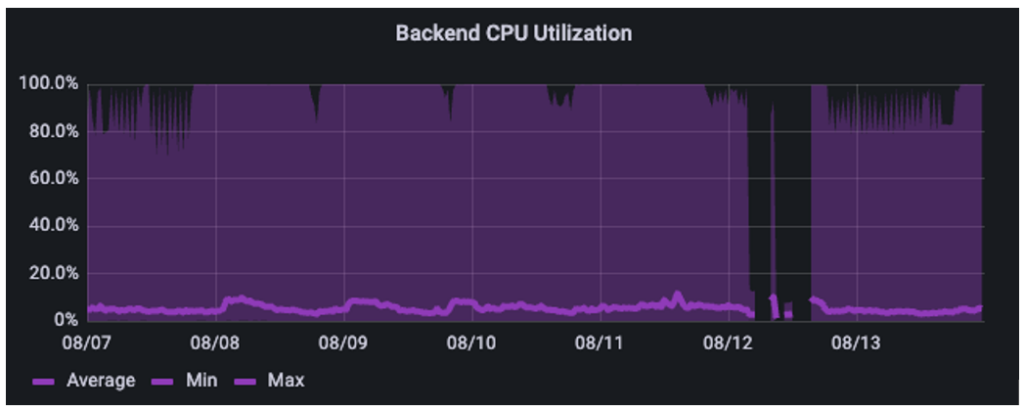
The deep purple and light purple indicate maximum utilization and average utilization. This shows the intensely bursty nature of this customer’s AI pipeline. If we only looked at averages, we would think the system is underutilized at ~5%. The reality is that it spikes up and down in intense bursts every few minutes, resulting in spikes that take it to 80-100% utilization on a regular basis.
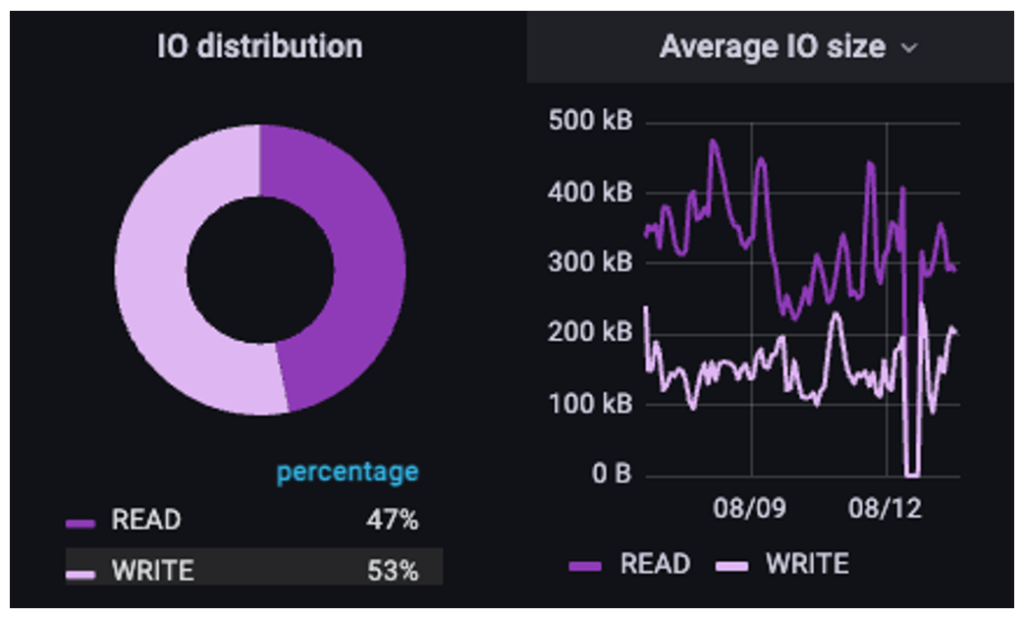
For this NLP pipeline, the read/write ratio is 47/53, but of note are the IO sizes: large IOs are read in, but smaller IOs are written out. In this case, the customer has taken small samples that are generally sub-100k in size, concatenated them together into a larger file, and is reading against the file as if it were a stream. But why all the small writes? This is a common theme in not just GenAI and AI workloads but in many HPC workloads as well: checkpointing.
Checkpointing
When running long training or operational jobs, checkpointing is the method of making sure that you have a “save point” in case a failure happens. The failure could be anything from hardware, where a server running a job has a hardware failure, to having an error in a GenAI workflow where a feature is being embedded in a layer but doesn’t complete. The checkpoint allows you to recover the state of the job, but can also be used to stop the model training, evaluate and then restart without having to go to the beginning. Checkpointing involves writing job or memory state out to storage. This can either be in large multi-gigabyte sets in the case of a memory dump, or in smaller incremental steps in the case of AI embedding/training checkpoints. In either case, latency is a key metric that matters because the longer it takes to do the writes, the longer the job has to wait to continue its normal training.
The smaller write IO in this use case is most likely layer checkpointing happening within the NLP workflow. This wide variance of data again challenges the data platform to tolerate multi-dimensional performance in this workflow.
Next, let’s look at an AI/ML model development environment. In this use case, the customer is building a combination of NLP and ML functions for text-text and text-action capabilities. This data pipeline is more segregated and has less overlap as they’re not at full-scale yet. We see here that they have blended IO with a 48% read/52% write ratio. Additionally, the IO sizes for reads tend to be larger than for writes.
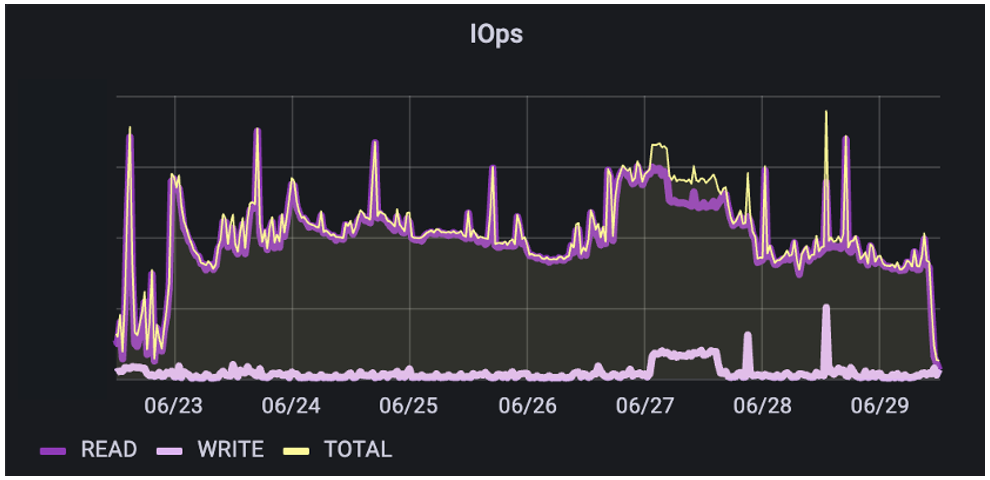
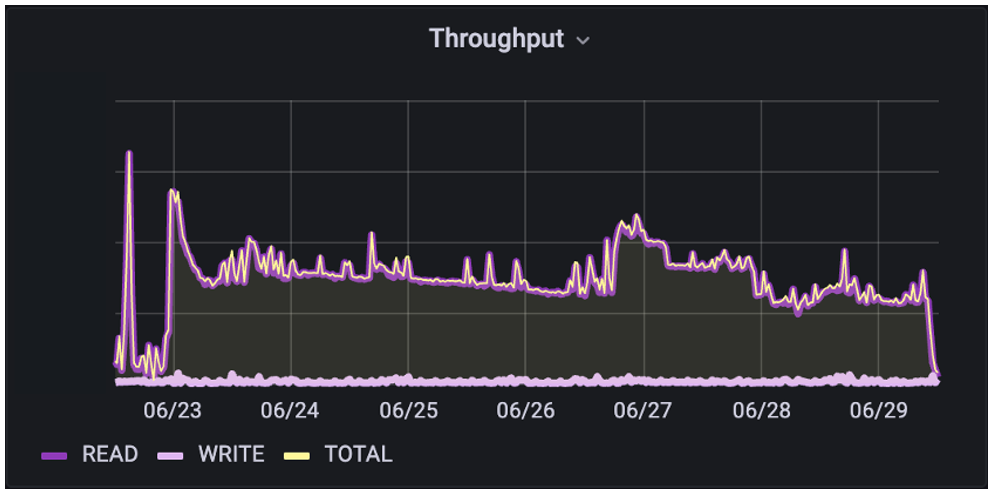
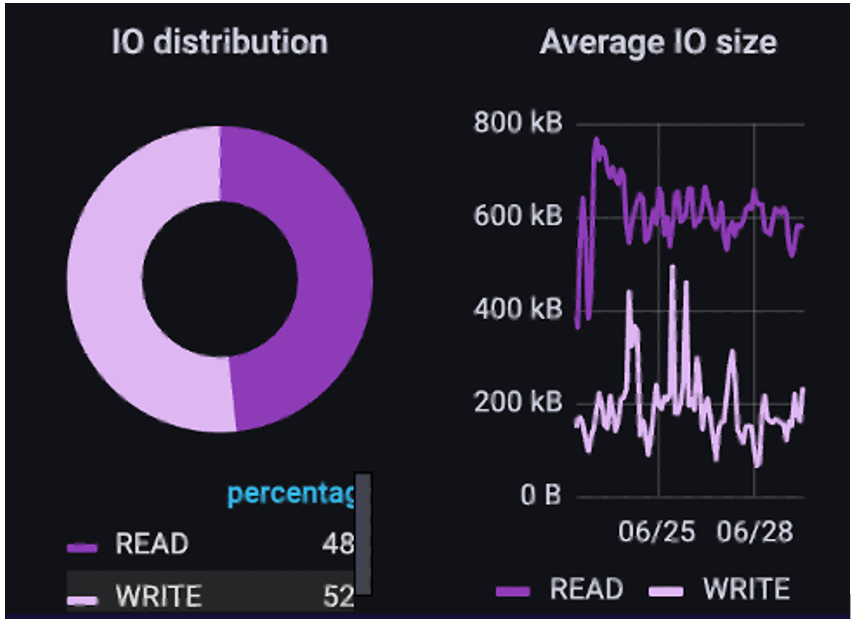
The big takeaway here is the effect that all the pre-processing has had on the IO patterns. Because the ingest data had a significant amount of pre-processing done to normalize the data before being built into H5 files, the IO range on reads is much narrower and more predictable. This is the tradeoff between doing lots of upfront pre-processing work to make the training IO easier, or doing less work and making training IO much more variable and difficult to handle.
Finally, if we look at an example of image recognition training where automated image pre-processing has been done, (note this is different than the metadata example in Part 3; the customer has not informed us as to whether this is TensorFlow or PyTorch, etc., based) we see that the customer is doing a classic isolated environment just for the read in the training of images. This is unusual, but at their current operational scale, they have made the decision to isolate training from all other workflow processes other than a daily batch transfer of the images to the storage cluster for training.
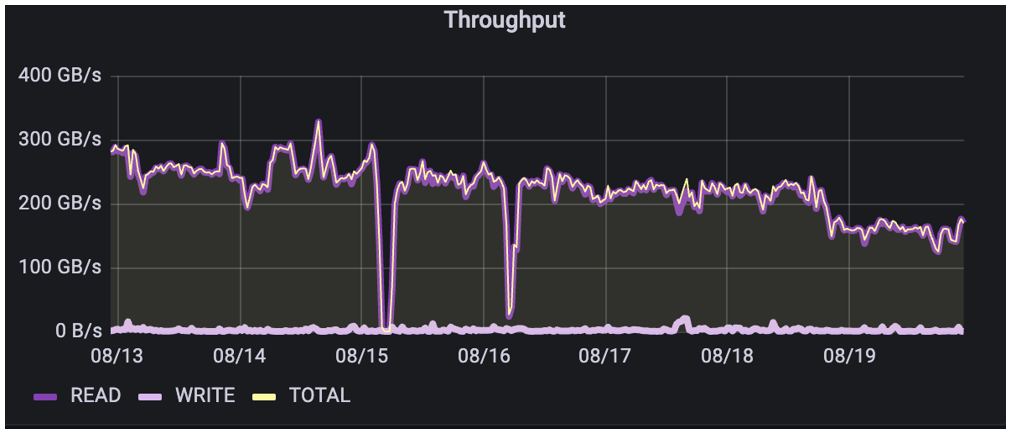
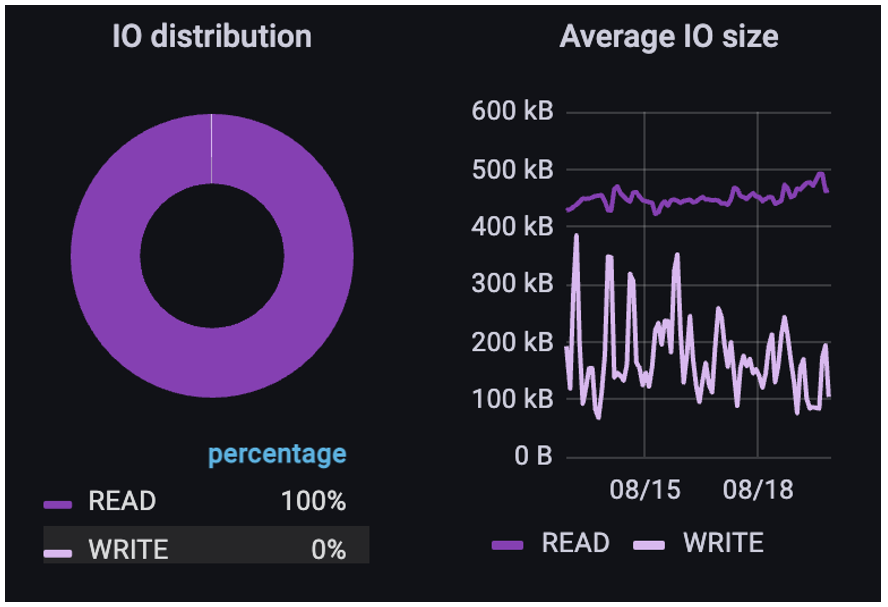
As expected, overall throughput is dominated by very consistently sized reads. However, the writes vary widely. Most of these writes were metadata updates to files, writebacks of process data and checkpointing. As we’ve noted before, the measured data accounts for actual data transfer; while all of the metadata ops for these writes don’t show up as data transfer, they can have a significant impact on the performance of training a model.
Conclusions
Data patterns for IO in GenAI and AI environments are not easy to handle due to high variability, especially at scale. The “IO blender” effect of overlapping data pipelines compounds this significantly. The IO that needs to be handled is typically bursty in nature, has wildly varying read/write IO sizes, and when tied together with the metadata problem, has to be as low latency as possible. Low latency is a leading indicator of overall performance in a system as it impacts every operation. The lower the overall latency, the faster the AI processes can move onto the next iteration/epoch/retune/enrichment/embedding cycle in the model workflow.
These IO profiles point to the need for a data platform that is capable of handling the multi-dimensional performance requirements of various GenAI and AI environments. Many data platforms struggle with achieving this performance for several reasons such as:
- Trying to create low latency transports by layering RDMA with older file protocols like NFS. While it works, it still cannot achieve the ultra-low latencies that newer technologies such as DPDK with NVMeoF-like transports can achieve.
- Filesystem latency. If the filesystem itself is not designed for massive parallelization of both metadata and data operations, then it winds up serializing access, resulting in delays in responding to IO requests from clients.
- Tuning for individual workload profiles. Many platforms have made design choices resulting in optimizing for singular performance profiles. This results in having to copy data within the platform to specifically tuned sections, which creates data stalls.
- Inability to scale against the Lots Of Small Files (LOSF) problem. With foundational models and other large learning models ingesting millions and sometimes billions of files of training data, many platforms struggle with handling this unstructured data. The workaround is to concatenate the data into a smaller number of large files, but this creates other access problems and can increase latency.
Thanks for reading through this 4-part series. Data and IO patterns are complex beasts to understand, and hopefully this brought some clarity to what they look like and the challenges inherent to handling them in GenAI and AI environments.
Want to know more? Check out the IO Profiles for Generative AI Pipelines Technical Brief that takes a deeper dive on this subject and how WEKA can help with these IO challenges.
Joel Kaufman is a Senior Technical Marketing Manager at WEKA and can be reached at joel@weka.io and @thejoelk on X/Twitter.
Popular Blogs From Joel Kaufman



Related Assets
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle