What is AI Storage?

AI Storage is a high-performance data architecture designed to handle the massive parallelism and low-latency requirements of AI workloads, such as model training and inference.
AI workload demands – from Generative AI to Agentic AI – put pressure on enterprise data infrastructures that weren’t designed for AI in the first place. As a result, analysts report that up to 60% of AI projects are failing due to having the wrong infrastructure.
In this article, we break down what organizations need to know about storage in the AI era.
Enterprise Requirements Are Shifting
Traditional enterprise storage was engineered for an era of predictable, sequential workloads, however, this type of storage falls critically short when faced with the intensive I/O patterns of AI.
Enterprises need AI storage that faces growing data challenges head on to accelerate production momentum and business outcomes
- Agentic Scale: Modern AI agents issue an order of magnitude more queries than human users, stressing legacy databases
- Latency at Scale: Systems that struggle to maintain consistently low latency for both training and inference compromise deployments
- GPU Starvation: As newer accelerators hit the data center, the gap between compute speed and storage throughput has widened to a breaking point.
- Metadata Bottlenecks: Managing lots of small files has become a sticking point for AI success
- Economic Impact: With storage prices spiking and global DRAM supply consumed largely by AI data centers, enterprises can no longer afford the inefficiency of poorly architected storage.
- The Memory Wall: Inference performance degrades unpredictably under load, as data, memory, and context are managed inconsistently across the stack
- Operational Complexity: Needing to stitch together your stack with traditional storage can make every effort wildly complex.
Performance Gap: How AI Storage Differs from Traditional Architectures
Compare the critical differences in I/O handling, metadata scale, and GPU support that separate legacy storage from purpose-built AI storage solutions.
How AI storage differs from legacy storage
| Storage Requirement | Traditional Enterprise Storage | Purpose-Built AI Storage (NeuralMesh) |
|---|---|---|
| I/O Pattern Optimization | Highly sequential; large-block read/write. | Random small-block parallel reads and large-block checkpoint writes. |
| GPU Utilization | Subject to GPU Starvation; storage throughput cannot match accelerator speed. | Sustained 100% GPU saturation; keeps expensive compute busy. |
| Inference Context & Memory | The Memory Wall; Context handled inconsistently across the stack. | Persistent Token Warehouse™ via Augmented Memory Grid; extends GPU memory 1000x. |
| Metadata Management | Centralized metadata “Master Node” bottlenecks; struggles with billions of small files. | Linear scale-out with Virtual Metadata Servers for sub-millisecond lookup latency. |
| Architecture | Legacy hardware-bound silos; complex “stitched together” stacks. | Unified, software-defined architecture; designed for simplicity at scale. |
| Security & Governance | Governance managed by separate, high-latency applications. | Inline Security & Classification; governance is a core feature of the storage layer. |
How AI Storage Meets Enterprises at the Intersection of Acceleration and Outcomes
To make sure enterprises can move their AI initiatives from pilot to production, AI Storage must meet extreme demands that traditional storage systems were never built for.
1. Sustained GPU Utilization
The infrastructure must be able to keep GPUs busy with data at all times, both in training and inference.
2. Ultra-Low Latency
AI Storage must deliver consistently low latency even under massive concurrent load
3. Persistent Inference Context
Inference context has become critical, and proper AI Storage treats context as a new kind of data that needs its own optimized handling.
ProTip: NeuralMesh with Augmented Memory Grid is optimized to yield a 6x faster Time-to-First-Token (TTFT) for long-context queries, as the model doesn’t have to re-pay the prefill tax of recomputing old data.
4. Dual-Purpose Engine for Training and Inference
Pivoting between the training and inference requires prioritizing random small-block reads over sequential large-block writes in real-time
5. Massive Scale-Out Metadata
Massive spikes and sustained pressure are no match for virtual metadata servers that scale linearly.
6. Agentic Ecosystem Integration
Native support for protocols like MCP ensures that agents can safely query underlying data without stitching together dozens of disparate databases.
7. Integrated Governance & Inline Security
The data layer must offer inline classification and performance-based QoS, ensuring that shared AI environments remain predictable and secure under load.
8. Resilience Under Stress
AI requires recovery and erasure coding that operates in the background without impacting the performance of active workloads.
The Importance of Persistent Memory
Memory is now a fundamental tenant of the AI storage paradigm, and WEKA has been leading the charge to integrate storage and memory.
Demanding inference workloads, growing context windows, and pressure on GPU high bandwidth memory all pointing to a storage crisis that only software-defined memory could solve.
In the Agentic era, the line between where data lives and where the agent thinks has to disappear.
That’s why WEKA launched Augmented Memory Grid: a solution that makes it possible to extend GPU memory into a persistent Token Warehouse™ with 1000x more GPU memory capacity. The world of AI Storage has not been the same since.
This unified storage and memory solution can radically increase token throughput and make your inference pipelines the stuff of legends.
“We are excited to leverage WEKA’s Augmented Memory Grid capability to reduce the time involved in prompt caching and improve the flexibility of leveraging this cache across multiple nodes—reducing latency and benefitting the more than 500,000 AI developers building on Together AI.”
Ce Zhang, Chief Technology Officer, Together AI
Your AI Initiatives Are Only As Agile As Your Storage.
Don’t let the wrong storage limit your AI domination. WEKA knows that your AI initiatives need storage specifically designed to accelerate and optimize your AI data pipelines.
Whether you need ultra-low latency for model training, exceptional GPU utilization to ensure profitability, or software-defined memory that can scale with your inference demands, WEKA AI Storage is architectured for outcomes.
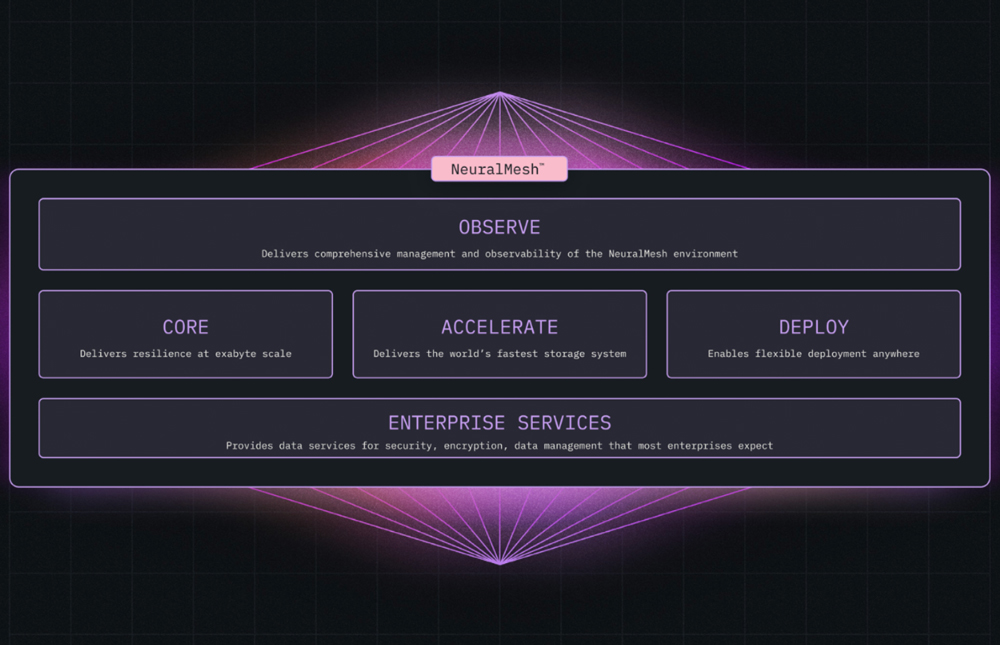
NeuralMesh Was Built for Enterprise AI
NeuralMesh’s incredible AI acceleration is the result of multiple, cutting-edge innovations working in harmony. From distributed metadata management and virtual metadata servers to kernel bypass and 4K granularity in data writing, every aspect of this AI Storage architecture is designed to eliminate bottlenecks and deliver performance that is simply unmatched by traditional systems.
- I/O profile: Optimized for Small-Block Parallel Reads and Large-Block Checkpoint Writes.
- Virtual Metadata Servers: Support billions of files with sub-millisecond lookup latency.
- Context Memory: Treat storage as an extension of the GPU’s local memory to manage the massive KV Cache required for long-context windows
- Integration: Standardized via MCP for easy connection to agentic workflows.
- Security: Inline Classification—governance is a feature of the storage, not a separate app.
- Scalability: Linear Scale-Out (Capacity + Performance) with no “Master Node” bottlenecks.
Get the AI Storage Buyer’s Guide
Still not sure if your pipelines need the world’s only AI Storage solution built from the ground up with your AI requirements in mind? We made an AI Storage Buyer’s Guide just for you.
Frequently Asked Questions About AI Storage
What is the difference between traditional storage and AI storage?
Traditional storage was designed for sequential read/write workloads — databases, file archival, backups — where data access is predictable and latency tolerances are relatively wide. AI storage is fundamentally different. AI workloads demand extreme parallelism, simultaneous high-throughput reads across thousands of GPUs, and sub-millisecond latency at petabyte scale.
The mismatch is costly. When AI pipelines hit traditional storage, GPUs stall waiting for data — turning expensive compute into expensive idle time. AI-optimized storage architectures are built to match the pace of accelerated compute, delivering the throughput, concurrency, and scalability that AI training, fine-tuning, and inference actually require.
How does storage affect GPU performance?
GPUs can only process data as fast as storage can deliver it. When storage throughput falls short, GPUs sit idle — a phenomenon known as GPU starvation. In large-scale AI training, this means your most expensive infrastructure is spending a significant percentage of its time waiting, not working.
Storage-induced bottlenecks compound across the AI pipeline: slow checkpoint saves interrupt training runs, insufficient I/O bandwidth limits how many GPUs can work in parallel, and poor metadata performance creates queuing delays that ripple across entire jobs. AI-optimized storage eliminates these constraints by delivering consistent, high-throughput I/O that keeps GPUs fed — at any scale.
What is the Token Warehouse in AI storage?
The Token Warehouse is a persistent storage layer for KV cache data generated during AI inference. In standard inference pipelines, KV cache — the computed context that allows a model to “remember” earlier parts of a conversation or prompt — lives exclusively in GPU high-bandwidth memory (HBM). When that memory fills up, the context is evicted, and the model must recompute it from scratch the next time it’s needed. This recomputation is called the prefill tax, and it’s a significant source of latency and GPU waste.
The Token Warehouse offloads KV cache to a high-performance storage tier, effectively extending GPU memory by orders of magnitude. Models can retrieve context rather than recompute it — reducing Time-to-First-Token, increasing tokens-per-GPU throughput, and making long-context and multi-session AI workloads economically viable at scale.
What is KV cache, and why does it matter for AI inference performance?
KV cache (key-value cache) is the stored computational state that allows large language models to process long prompts efficiently. When a model reads an input — whether a document, a conversation history, or a system prompt — it generates key and value vectors for each token. Caching these vectors means the model doesn’t have to reprocess prior tokens on subsequent steps, dramatically accelerating inference.
The problem is capacity. KV cache is extremely memory-intensive, and GPU high-bandwidth memory (HBM) is finite. As context windows grow and agentic AI workloads chain together longer sequences of interactions, KV cache demand routinely exceeds available GPU memory. When that happens, cached context is evicted and must be recomputed — adding latency and consuming GPU cycles that could be serving new requests. High-performance AI storage that can hold and rapidly serve KV cache data is increasingly essential infrastructure for production inference at scale.
What storage infrastructure do agentic AI workloads require?
Agentic AI workloads — where AI systems autonomously plan, reason, retrieve information, and execute multi-step tasks — place unique and demanding requirements on storage infrastructure. Unlike batch inference or offline training, agentic pipelines are dynamic: agents query live data, maintain long-running context across sessions, spawn parallel sub-tasks, and generate outputs that feed back into the system in real time.
This creates several infrastructure challenges simultaneously: low-latency access to large, constantly updated datasets; high-concurrency I/O as multiple agents query the same underlying data; persistent context storage across requests and sessions; and the ability to scale without degrading performance. Agentic AI requires storage that isn’t just fast — it needs to be intelligent, flexible, and deeply integrated with the AI data pipeline from training through inference.
Related Assets
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
The Buyer’s Guide to Modern Storage for Media & Entertainment

The Buyer’s Guide to Modern Storage for Media & Entertainment
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure