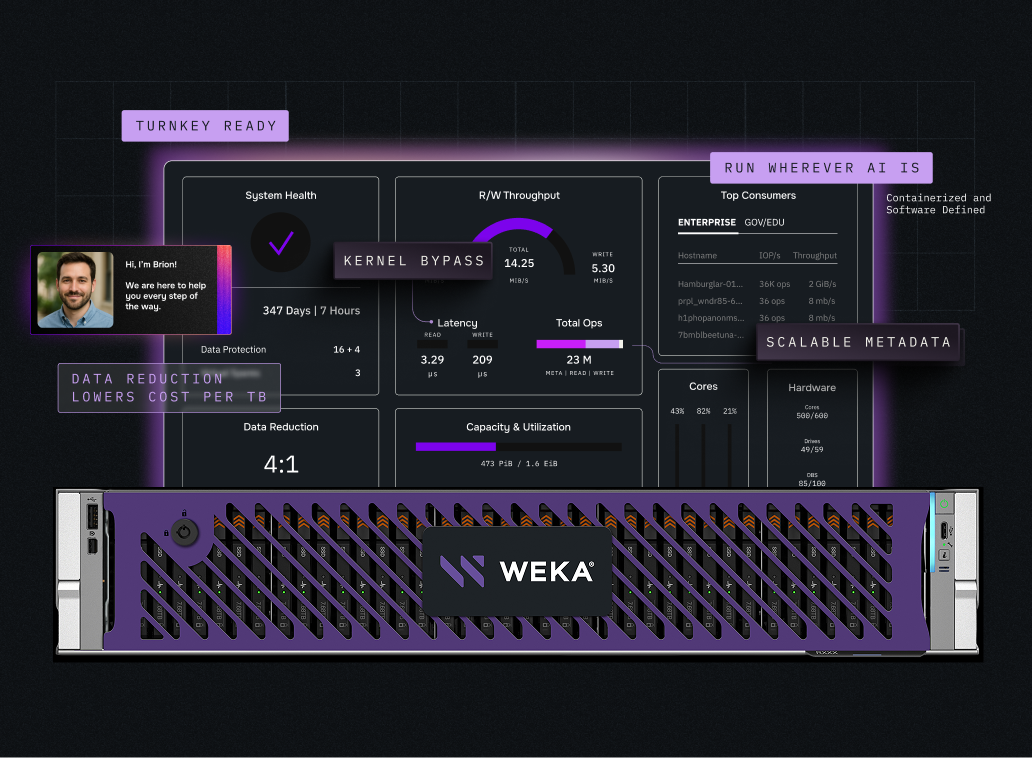
Deploy. Run. Done.
WEKApod is the easiest way to deploy and scale NeuralMesh™ with industry-leading price-performance, exceptional density, and turnkey simplicity.
Deploy AI Infrastructure in Hours, Not Weeks
Get 5x Greater Performance in the Same Rack Space*
Reduce Power Consumption 68% Per TB*

“Space and power are the new limits of innovation in data centres. WEKApod’s exceptional storage performance density allows us to deliver hyperscaler-level data throughput and efficiency within an optimised footprint—unlocking more AI capability per kilowatt and square metre. This efficiency directly improves economics and accelerates how we bring AI innovation to our customers.”
The WEKApod Family
WEKApod Prime
Price-Performance & Density
Ideal for:
Enterprises running mixed AI workloads
Research institutions
Cost-optimized infrastructure
WEKApod Nitro
Extreme Performance
Ideal for:
AI clouds & GPU-as-a-service
AI factories at scale
Foundation model development
Deploy Without Compromise
Mixed Flash Intelligence
Analyze workload characteristics in real time and automatically distribute data across TLC and eTLC flash drives with WEKApod Prime’s AlloyFlash™ technology, which eliminates cache hierarchies and data movement to maximize performance and cost efficiency.
Extreme Performance Density
Minimize your datacenter footprint and maximize efficiency with purpose-built 1U and 2U form factors that deliver optimized power and cooling architecture and pack up to 40 drives per appliance. High-density flash configurations deliver extreme performance with up to 17M IOPS, sub-millisecond latency, 800 Gbps throughput, and 55PB of initial capacity in a 42U rack.
Pre-Validated Turnkey Solutions
Deploy in hours without specialized storage expertise with advanced utility setups and industry-standard hardware that’s pre-validated for NVIDIA DGX SuperPOD™ and NVIDIA Cloud Partner (NCP) configurations, eliminating the need for complex integration work.
Dive Deeper

Next Generation WEKApod Shatters AI Storage Economics
See how WEKApod delivers 65% better price-performance and 5x better performance density in a turnkey package.

WEKApod Delivers High Performance and Manageable Costs
Eliminate AI storage tradeoffs with better price-performance, capacity density, IOPs per rack, and so much more.
Scale AI Innovation Faster With NeuralMesh
Get an inside look at the NeuralMesh ecosystem and learn how leading AI teams are eliminating latency, maximizing GPU utilization, and cutting infrastructure costs.