Shatter AI Performance Barriers
Seamlessly fuse compute and storage to reduce infrastructure costs with NeuralMesh Axon.
The world’s leading AI innovators and research teams build with WEKA





The Best Storage is the Storage You Already Have
Months-long lead times, rising prices, and constrained NVMe supply shouldn’t gate your AI infrastructure. Axon unlocks the storage you already have, turning local drives into a shared high-performance
storage pool.

“By optimizing inference at scale and embedding ultra-low latency NVMe storage close to the GPUs, organizations can unlock more bandwidth and extend the available on-GPU memory for any capacity. Partner solutions like WEKA’s NeuralMesh Axon deployed with CoreWeave provide a critical foundation for accelerated inferencing while enabling next-generation AI services with exceptional performance and cost efficiency.”
Why NeuralMesh Axon?
Deploy NeuralMesh™ Axon™ directly on your GPU compute to get ultra-fast storage without adding separate infrastructure.
Accelerate Performance
Get unmatched performance and utilization for the largest AI training and inference workloads.
Drive Efficiency
Consolidate compute and storage to reduce rack space, power, and cooling. Cut costs and run leaner, smarter infrastructure at scale.
Break Memory Barriers
Leverage add‑on capabilities like WEKA Augmented Memory Grid™ to offload KV cache and remove memory constraints.
Instant Availability
Container‑native microservices deliver large-scale readiness on day one.
Reduce AI Infrastructure
Run GPUs on‑prem or in the cloud without external storage infrastructure.
Power Demanding Workloads
Deliver ultra low-latency, high-throughput storage performance for the most demanding use cases across AI, media, finance, and healthcare.
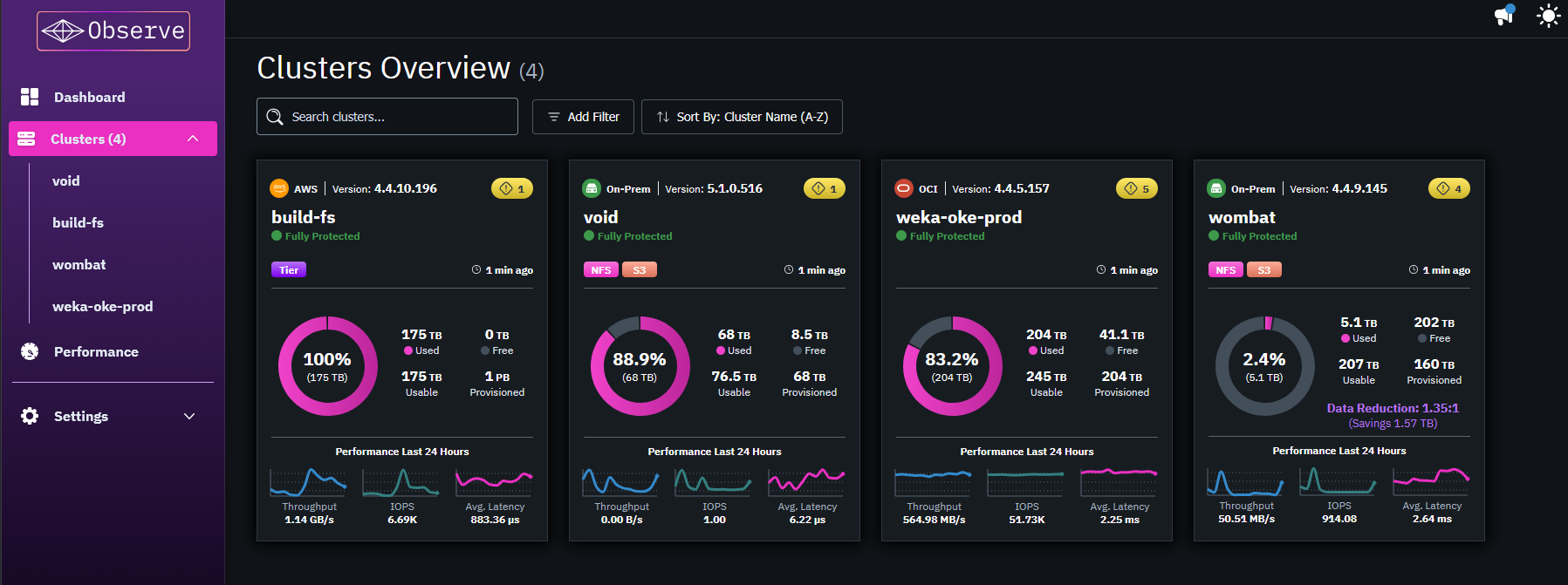
Your GPUs, Optimized
See every cluster, every environment, in one place. Real-time throughput, latency, and IOPS—synchronized across dimensions so you know exactly what your GPUs are doing and what’s standing in their way.
“Embedding WEKA’s NeuralMesh Axon into our GPU servers enabled us to maximize utilization and accelerate every step of our AI pipelines. The performance gains have been game-changing: Inference deployments that used to take five minutes can occur in 15 seconds, with 10 times faster checkpointing.”
“With WEKA’s NeuralMesh Axon seamlessly integrated into CoreWeave’s AI cloud infrastructure, we’re bringing processing power directly to data, achieving microsecond latencies that reduce I/O wait time and deliver more than 30 GB/s read, 12 GB/s write, and 1 million IOPS to an individual GPU server.”
Capability Comparison for NeuralMesh and NeuralMesh Axon
| NeuralMesh | NeuralMesh Axon | |
|---|---|---|
| Capability | ||
| Physical Footprint | No Reduction | Significant reduction (including rack space, power, cooling, and networking) |
| Recommended GPU Server Nodes | No specific minimum | Typically recommended for 128+ GPU nodes |
| Tiering Support | Supported | Not recommended |
| Single Cluster Multi-Client Configuration | Supported | Not currently supported |
| Supported Protocols for Direct Data Access | POSIX, S3, NFS, SMB | POSIX only |
| Resource Management | Flexible | Typically managed via Kubernetes or SLURM |
Articles and Resources
