Stop Waiting on Storage. Start Running AI.
Your storage vendor’s lead time is now part of your project timeline. WEKApod Prime ships in weeks.
We Have Supply. You Have Demand. Let’s talk.
Deploy. Run. Done.
3 – 4 Weeks
From order to production AI in one-fourth the time.
55 PB Per Rack
Fewer racks, less cabling, lower cooling load.
65% Better Price-Performance
The performance your GPUs need. At a price that doesn’t require a board meeting.

“The exceptional storage performance in WEKApod delivers hyperscaler-level throughput within an optimised footprint.”
Navigate the Shortage with These Resources

Five Strategies for Navigating the Shortage
Understand how to maximize GPU utilization, eliminate infrastructure waste, and extend memory – no new procurement required.

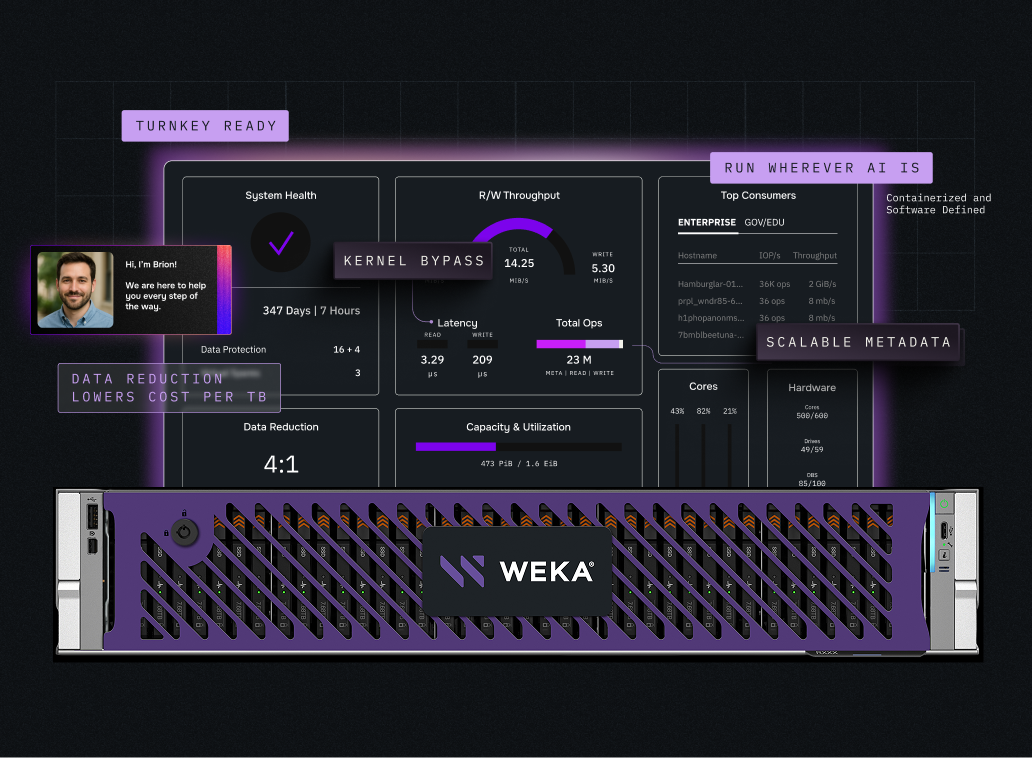
WEKApod Delivers High Performance and Manageable Costs
Eliminate AI storage tradeoffs with better price-performance, capacity density, IOPs per rack, and so much more.
Practical Strategies for Navigating the Memory Shortage
GPU costs are rising. Memory is constrained. Model sizes aren’t shrinking.
Join Steve McDowell, Senior Analyst & Founder at NAND Research and Val Bercovici, Chief AI Officer at WEKA as they break down what the memory shortage actually means for your AI infrastructure—and what you can do about it right now.