WEKA Doesn’t Make the GPU, WEKA Makes the GPU 20X Faster

For the last decade, most of the focus in AI has been on GPU processing, and rightfully so, with all the advancements going on there. But GPUs have gotten so fast that data input into them has become the primary bottleneck to overall AI training performance. A fast, efficient data pipeline has become critical to accelerating Deep Neural Network (DNN) training with GPUs.
GPUS Have Become Starved for Data
Recent research by Google1, Microsoft2 and organizations around the world3 are uncovering that GPUs spend up to 70% of their AI training time waiting for data. And looking at their data pipelines, that should be no surprise. The diagram below shows the Deep Learning data pipeline typical of the references and recently described by NVIDIA4 as commonly used by them and their customers.
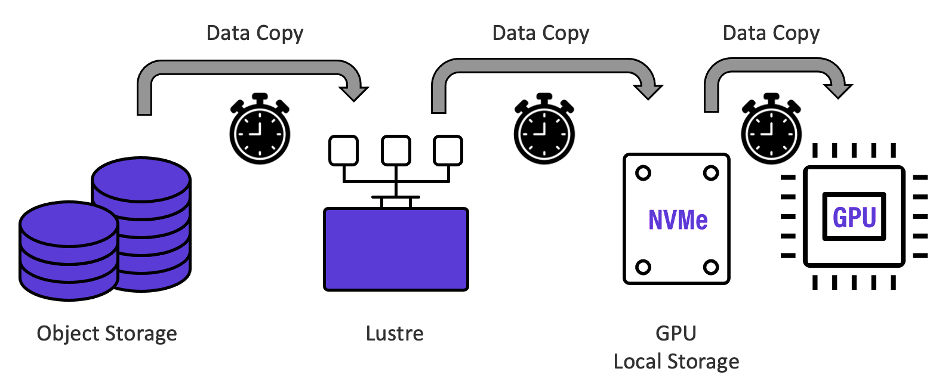
As shown in the diagram above, at the beginning of each training epoch, training data kept on high-capacity object storage is typically moved to a Lustre storage system tier and then moved again to GPU local storage which is used as scratch space for GPU calculations. Each “hop” introduces data copying time latency and management intervention, slowing each training epoch considerably. Valuable GPU processing resources are kept idle waiting for data, and vital training time is needlessly extended.
WEKA Has a Better Way: The Data Platform for AI
The primary design objective with deep learning model training, and for which the WEKA Data Platform for AI is designed for, is to constantly saturate GPUs doing the training processing by providing the highest throughput at the lowest latency from the WEKA file system where the data for learning is stored. The more data a deep learning model can learn from, the faster it can converge on a solution, and the better its accuracy will be.
WEKA collapses the typical GPU-starving “multi-hop” AI data pipeline into a single, zero-copy high performance, data platform for AI – where high-capacity object storage is “fused” with high-speed WEKA storage, sharing the same namespace, and accessed directly by the GPU with the NVIDIA GPUDirect Storage protocol, removing all bottlenecks as shown in Figure 2. below. Incorporating the WEKA Data Platform for AI into deep learning data pipelines saturates data transfer rates to NVIDIA GPU systems and eliminates wasteful data copying and transfer times between storage silos to geometrically increase the number training data sets that can be analyzed per day.
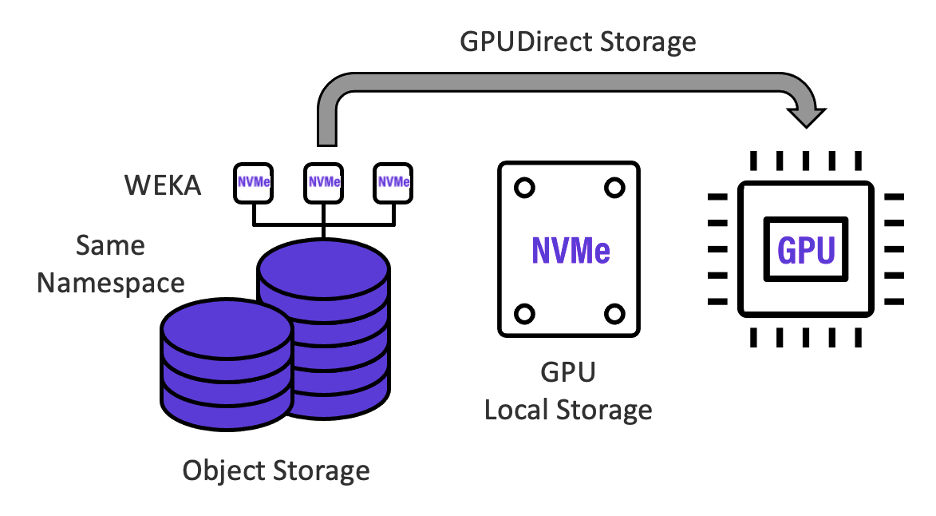
With the WEKA Zero-Copy Architecture, data is simply written once and transparently accessed by all resources in the deep learning data flow. And as shown in the figure above, The WEKA Data Platform for AI supports NVIDIA’s GPUDirect Storage protocol that bypasses the GPU server CPU & memory, enabling GPUs to communicate directly with WEKA storage, accelerating throughput to the fastest possible performance.
An Architecture Designed for the Lowest Latency Deep Learning Data Pipeline
Deep Learning AI workflows consist of intense random reads across training datasets where low latency can accelerate training and inference performance. WEKA is designed to achieve the lowest latency and highest performance possible. WEKA’s small 4K block size matches that of NVMe SSD media block sizing for optimum performance and efficiency. WEKA evenly distributes metadata processing and direct data access across all storage servers (with no back-end network), further lowering latency and increasing performance. What’s more, WEKA designed low latency performance-optimized networking: WEKA does not use standard TCP/IP services, but a purpose-built infrastructure that uses the Data Plane Development Kit (DPDK) over UDP to accelerate packet processing workloads without any context switches and zero-copy access. WEKA bypasses the standard network kernel stack eliminating the consumption of kernel resources for networking operations.
Seamless Low-Latency Namespace Expansion into Object Storage
The WEKA Data Platform’s integrated object storage provides for economical, high-capacity, and fast access to store and protect large numbers of training sets for the duration of the deep learning training process. The WEKA Data Platform for AI includes the ability to seamlessly expand its namespace to and from object storage; all data resides in a single WEKA namespace and all metadata stays on flash tier for fast, easy access and management. To reduce latency, large files are chopped down into small objects and tiny files are packed into larger objects to maximize parallel performance access and space efficiency.
A 20X Reduction in Epoch Time By Switching to the WEKA Data Platform for AI
To illustrate just how dramatic training epoch times can be reduced, one of the largest, most knowledgeable users of computer vision Deep Neural Networks recently switched from a traditional multi-copy data pipeline, where it would take them 80 hours to do each training cycle, to WEKA’s zero-copy data pipeline. They reduced their epoch time 20X to 4 hours as shown in Figure 3. below. This allowed them to do in 12 days what would take a year on their old infrastructure, drastically speeding their final product to market.

Contact your WEKA representative for more information on how WEKA can accelerate your Deep Learning AI data pipelines.
1 “tf.data: A Machine Learning Data Processing Framework”
2 “Analyzing and Mitigating Data Stalls in DNN Training”
3 “Characterization and Prediction of Deep Learning Workloads in Large-Scale GPU Datacenters”
4 “Beyond the Hype: Is There a Typical AI/ML Storage Workload?” CJ Newburn [NVIDIA]
Popular Blogs From Robert Murphy



Related Assets
-
Gorilla Guide to High Performance Data in the Cloud

Gorilla Guide to High Performance Data in the Cloud
-
Supercharging GPU Cloud for AI Workloads

Supercharging GPU Cloud for AI Workloads
-
The Impact of Storage Architecture on the AI Lifecycle

The Impact of Storage Architecture on the AI Lifecycle