Flexibility by Design: Avoiding the Quiet Trap of AI Infrastructure Lock-In

Compute. Networking. Data. These three elements form the triangle at the heart of AI infrastructure. When everything lines up, they support rapid progress. When any side lags, you’re left with bottlenecks that limit performance and stall innovation.
An organization’s ability to be flexible depends on how these three elements interact. The challenge is to ensure they don’t work against each other as needs change. Training, inferencing, and data preparation each place unique demands on infrastructure, and the balance of compute, networking, and data shifts with every new workflow.
But too often, organizations find themselves locked in by earlier decisions that didn’t account for how quickly the AI landscape changes. Here’s how to stay out of that trap.
The Triangle That Drives Performance
Every AI workload depends on three interrelated components:
- Compute: The raw processing power to train, infer, and analyze.
- Networking: The bandwidth and low-latency connections to move data efficiently.
- Data/Storage: The foundation that keeps data accessible and fast.
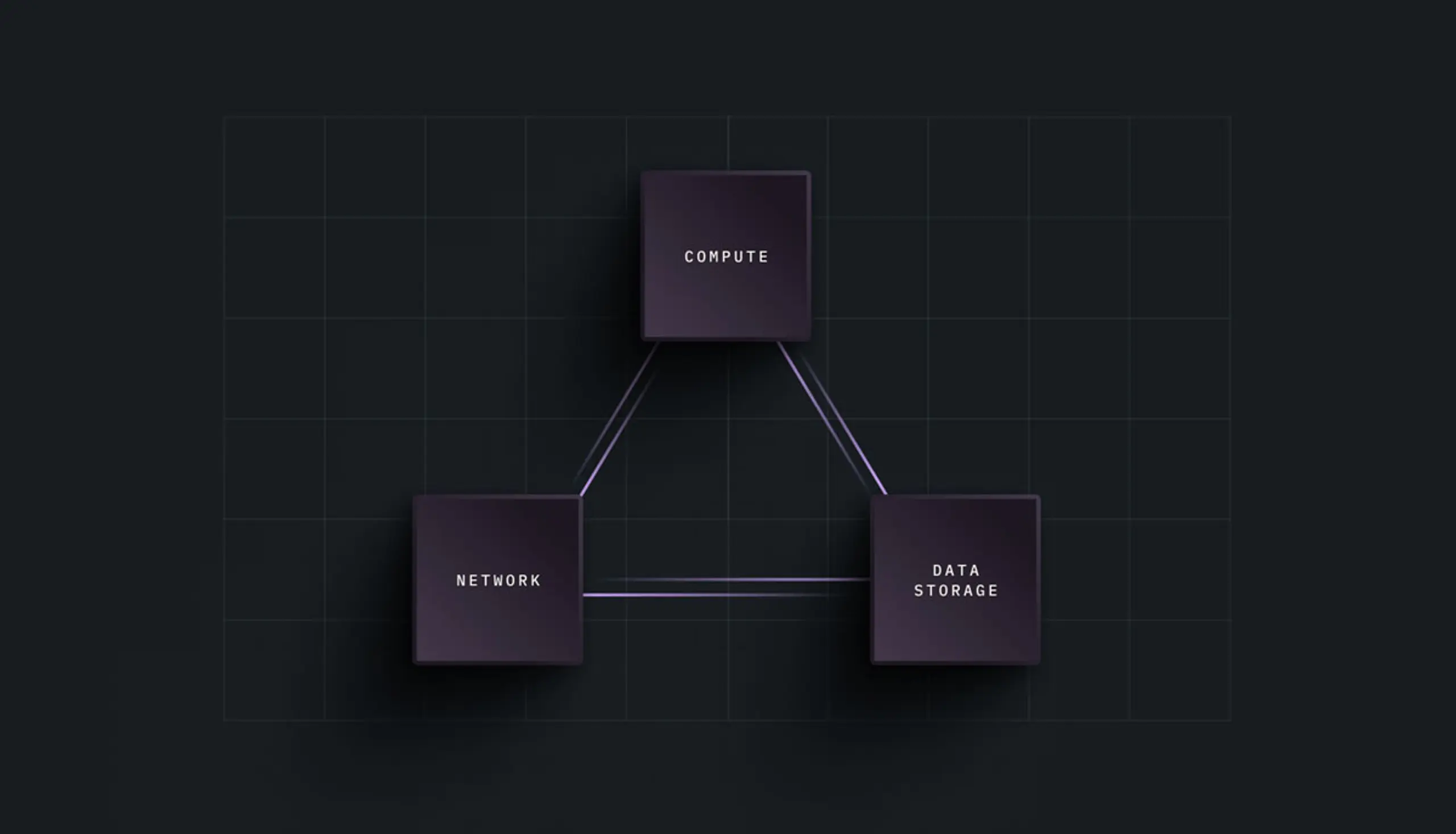
The Infrastructure Balancing Act: When compute, networking, and data stay in sync, performance follows.
In this triangle, each side is equally important, and equally capable of becoming the bottleneck that holds everything back. When any side of this triangle falters, performance suffers. For example, a powerful GPU cluster means little if your networking can’t feed it data fast enough, or if your storage can’t keep up with the pace of inferencing or training.
Building flexibility into each of these areas is what ensures your AI deployments can adapt to new workloads, new algorithms, and new market demands.
The Deployment Decisions That Shape Your Path
When it comes to choosing a technology, most organizations make decisions based on the most immediate problem—and, most of the time, speed to market drives everything. There’s pressure to get the model trained, the product out the door, the proof of concept delivered. In the rush to stand up an AI deployment, there isn’t always time to think about how each piece of the triangle fits together over the long term.
The fastest route usually involves leaning on what’s already available—using first-party cloud services, relying on preconfigured resources, grabbing the tools that promise to make things easier right now. These choices are practical, driven by immediate objectives: budget, timelines, or the need to show results. But they often come with long-term consequences. Rushing into proprietary platforms can create “infrastructure dependencies” that inflate costs and stifle innovation. In more extreme cases, like the Builder.ai collapse covered in CTO Magazine, vendor lock-in has left customers cut off from their own data and code.
But different environments offer different tradeoffs when it comes to deployment:
| Environment | Strategy | Pros | Cons |
|---|---|---|---|
| On-Premises Data Centers | Complete control over compute, networking, and storage | This can be ideal for organizations with the scale and resources to build for the future | Demands a larger capital (and time) commitment up front |
| Cloud Providers | Convenience and speed to deployment | Perfect for smaller teams or those who need to move fast | Moving fast comes at the cost of flexibility and vendor lock-in over time |
| GPU-as-a-Service and Neo Clouds | Tailored environments optimized for AI workloads | This gives teams access to cutting-edge AI resources without the overhead of managing them directly | Similar to above, the tradeoff is less control |
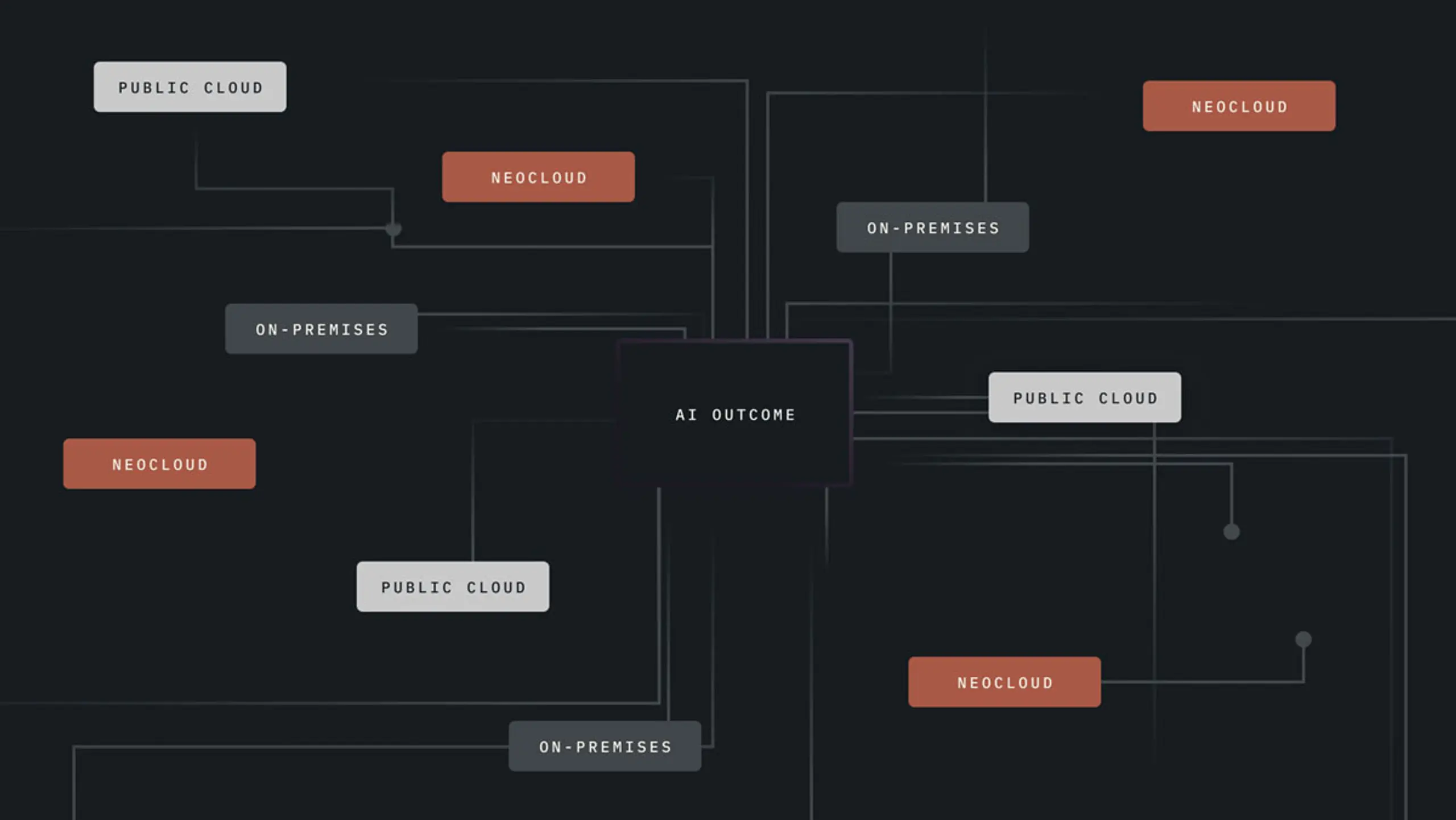
One Application, Many Footprints: AI workloads don’t stay in one place—to power AI outcomes, you need to have the flexibility to run workloads where they will perform best. If there isn’t flexibility, innovation slows.
These early choices shape the path you’re on, often in ways you can’t see until later. Infrastructure that isn’t designed for flexibility can end up defining how your workloads perform.
It’s a quiet form of lock-in: decisions that made sense in the rush to launch become barriers when you need to pivot or scale.
Why Early Hardware/Software Choices Matter
It’s tempting to think that early decisions on hardware, software, and data are minor. After all, the workloads keep running, and the project moves forward. But these choices—what hardware you use, how you connect it, and where your data lives—create an architecture that’s hard to change later:
- Compute constraints: Decisions about which GPUs or CPUs you use can limit your ability to run certain models or scale to new demands.
- Networking bottlenecks: The wrong network design might not seem like a problem until you start pushing real-time inference or large-scale training, and suddenly you’re stuck.
- Data lock-in: Moving data between environments is never trivial. Choosing a single-vendor stack often means your data workflows are tied to that provider’s ecosystem.
Over time, these technical decisions become organizational ones. They shape the conversations you have about cost, performance, and what’s possible next quarter—or next year—and determine how easily you can respond when a new AI method demands more bandwidth or your business model changes overnight. According to ITPro, 95% of UK IT leaders say they’ve faced unexpected consequences from early cloud decisions—many now reversing course toward hybrid strategies to regain control.
The quiet truth of AI infrastructure is that the hardware, networking, and storage decisions you make today become the foundation you’ll live with tomorrow.
Building Flexibility: Hardware and Application Layers
Flexibility is a design choice. At the hardware layer, that means building with modularity in mind. The triangle—compute, networking, and data—has to work in harmony, no matter the workload.
For those starting from scratch, this can be baked in from the beginning. Modular design, cloud-agnostic workflows, and software-defined systems all help avoid the trap of hardware lock-in. It’s the path of organizations who see flexibility as part of the initial build, not something to tack on later. Many enterprises now see hybrid and multi-cloud strategies as essential for supporting AI at scale—not just for performance, but for compliance and business continuity.
But most organizations aren’t starting fresh. They’ve made pragmatic decisions along the way—driven by timelines, procurement cycles, or the realities of scaling in production. That’s where the architectural design becomes the lever. It’s where flexibility can be reclaimed.
That’s the core philosophy behind NeuralMesh™ by WEKA®. As a software-defined storage system, it is the same solution used in on-prem environments, public clouds, and GPU-as-a-service platforms.
Under the hood, NeuralMesh is built on a containerized microservices architecture that allows it to evolve in step with modern workloads. And it has—continuously. By building on microservices and software-defined principles, WEKA helps customers avoid rigid infrastructure decisions and align with the kind of modular, portable design practices that industry leaders—including advocates of open-source architectures—are calling essential for long-term resilience.
NeuralMesh is truly software-defined—any cloud, any data center. We are the only storage provider that can do it. Ask us about it!
This is what makes NeuralMesh so valuable in fields like life sciences, where the infrastructure is inherently hybrid. Cryo-EM, genomics, pharma R&D—these organizations need cloud when the workload calls for it and on-prem when data gravity or cost says otherwise. NeuralMesh makes that movement seamless. No reinvention. No new RFPs. Just continuity across environments for your infrastructure team and your users.
Flexibility at the infrastructure layer means you’re not locked into where you are—or forced to start over when things change. It means your infrastructure moves with your business, not against it.
The Bottom Line: Flexibility Isn’t a Feature, It’s a Foundation
AI doesn’t stand still. New models, new demands, and new ways of working emerge every quarter. Infrastructure that once seemed perfectly tuned can suddenly feel like a constraint. The only way to stay ready is to design for flexibility.
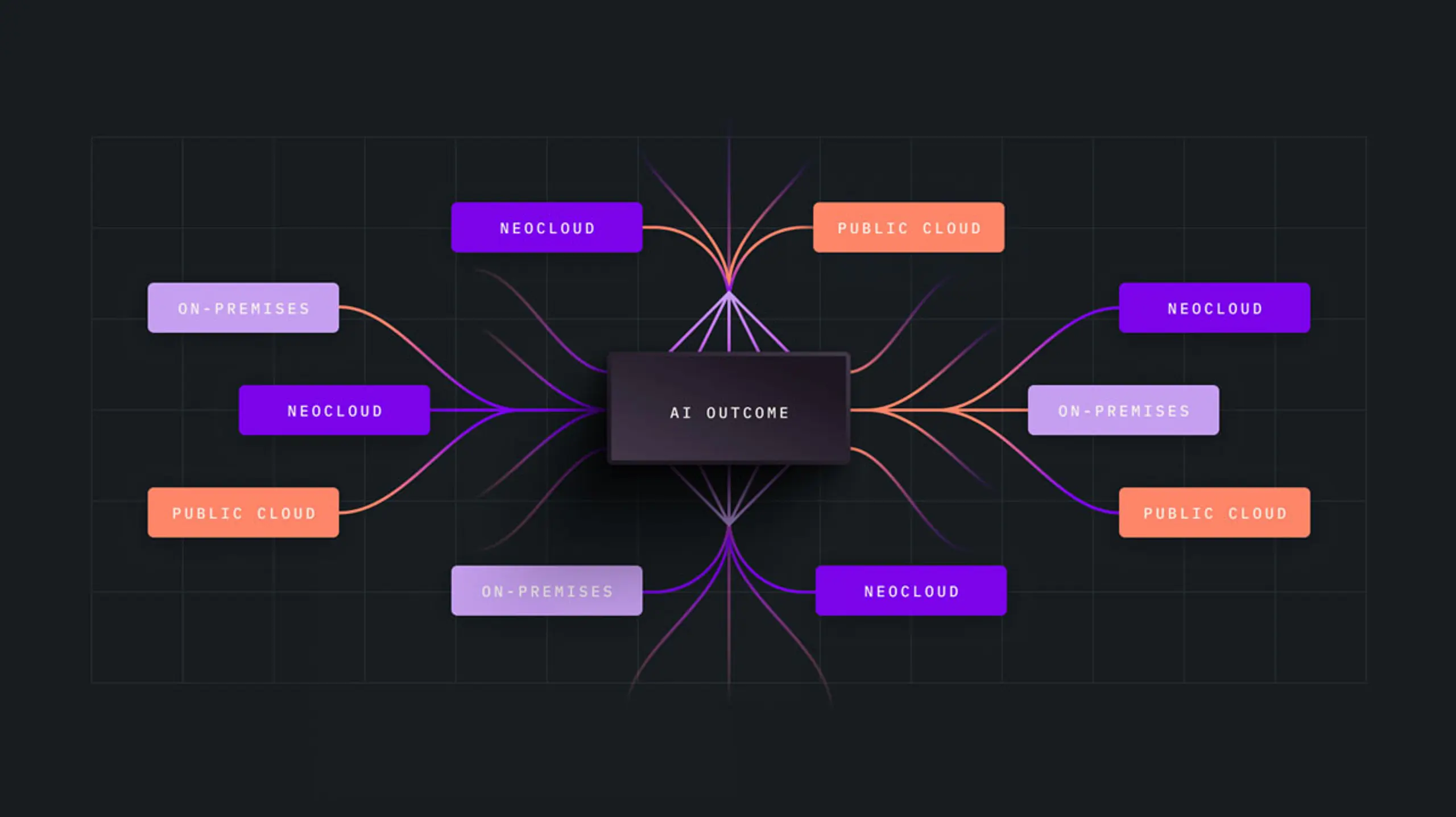
Bringing It All Together: NeuralMesh connects everything—on-prem, cloud, and neo cloud—into one high-performance data fabric.
Whether you’re starting from scratch or adapting what you already have, the challenge is the same: keep the balance of compute, networking, and data in your control, not your vendor’s. Use the tools that let you move fast, but don’t give up the ability to move in a new direction when the next wave of AI hits.
That’s the real measure of flexibility. Not just performance today, but the freedom to keep pushing forward tomorrow.
Wherever you are in your AI journey—designing from scratch or optimizing what’s already in place—WEKA can help you move faster, smarter, and with less friction. Learn how NeuralMesh delivers the flexibility, performance, and control your workloads demand.
What's Next



Scale Production AI Faster with NeuralMesh
Your models aren't slow. Your data is. Fix AI bottlenecks with high-throughput infrastructure.