Unlocking Scalable Inference with WEKA Augmented Memory Grid

At NVIDIA GTC, we introduced WEKA Augmented Memory Grid—an initiative that’s set to redefine token economics. We demonstrated how Augmented Memory Grid radically reduces the time to first token (TTFT), achieving a 41x improvement based on a 128,000-token context window. Since then, models like Llama-4-Scout-17B-16E have arrived, pushing context lengths into the millions of tokens.
It seems every week brings new use cases. I am constantly being asked by our customers: How can Augmented Memory Grid help balance the costs of our inference?
In this blog, we’ll dive into the latest insights from our testing with Augmented Memory Grid deployments, highlight the performance gains we’re validating with customers, and—most importantly—break down the key factors that influence those benefits.
Augmented Memory Grid—Under the Hood
Transformer models, which support many modern LLMs, operate in two main phases:
- Prefill Phase: A compute-bound task where input tokens (prompt and context) are processed to build a memory optimization structure called the Key-Value (KV) cache.
- Decode Phase: A memory bandwidth-bound task where tokens are generated one at a time using the KV cache.
In the real world, inference systems often struggle to keep KV cache in GPU or server memory, triggering copious redundant prefills while depriving the decode phase of fast access to KV cache when needed. WEKA Augmented Memory Grid optimizes the prefill phase by employing latency-slashing techniques to persistently store the KV cache, improving efficiency by eliminating redundant prefills, while accelerating the decode phase with more available KV cache.
At its core, Augmented Memory Grid leverages a memory-class token warehouse™ enabling direct Warehouse-to-GPU data access at ~300GB/s (2400Gb) per host*. With this performance level, Augmented Memory Grid effectively augments the memory available to inference systems—unlocking massive efficiency gains.
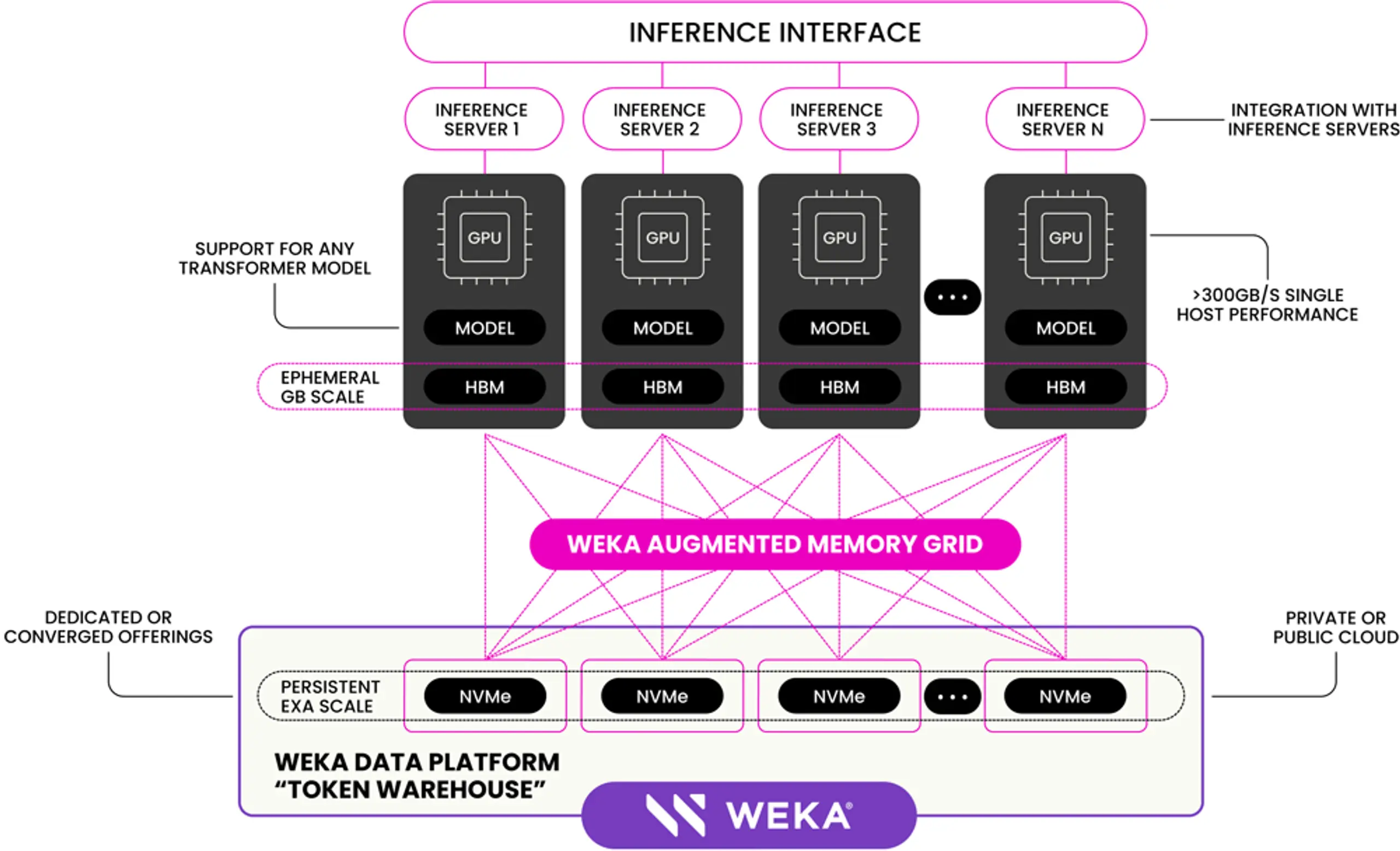
*DGX H100 to a 8-node WEKApod with 72 drives over East-West fabric in Infiniband
Four Benefits of Augmented Memory Grid
1. Dramatically higher cache hit rates
With our token warehouse, we can provide memory-class performance and the capacity density of NVMe. This means that the inference system can keep much more KV cache without needing to evict for radical improvements in tokenomics.
As an example, with Llama-3.3-70B at FP16, the cache for each token is 326KB. Using constant prefill rates (the rate at which the KV cache is generated) of vLLM with 8xH100 at a moderate 16,000 context length, 1 TB of DRAM allows for ~8 minutes of cache storage before eviction kicks in and cache hit rates plummet.
2. Huge reductions in TTFT
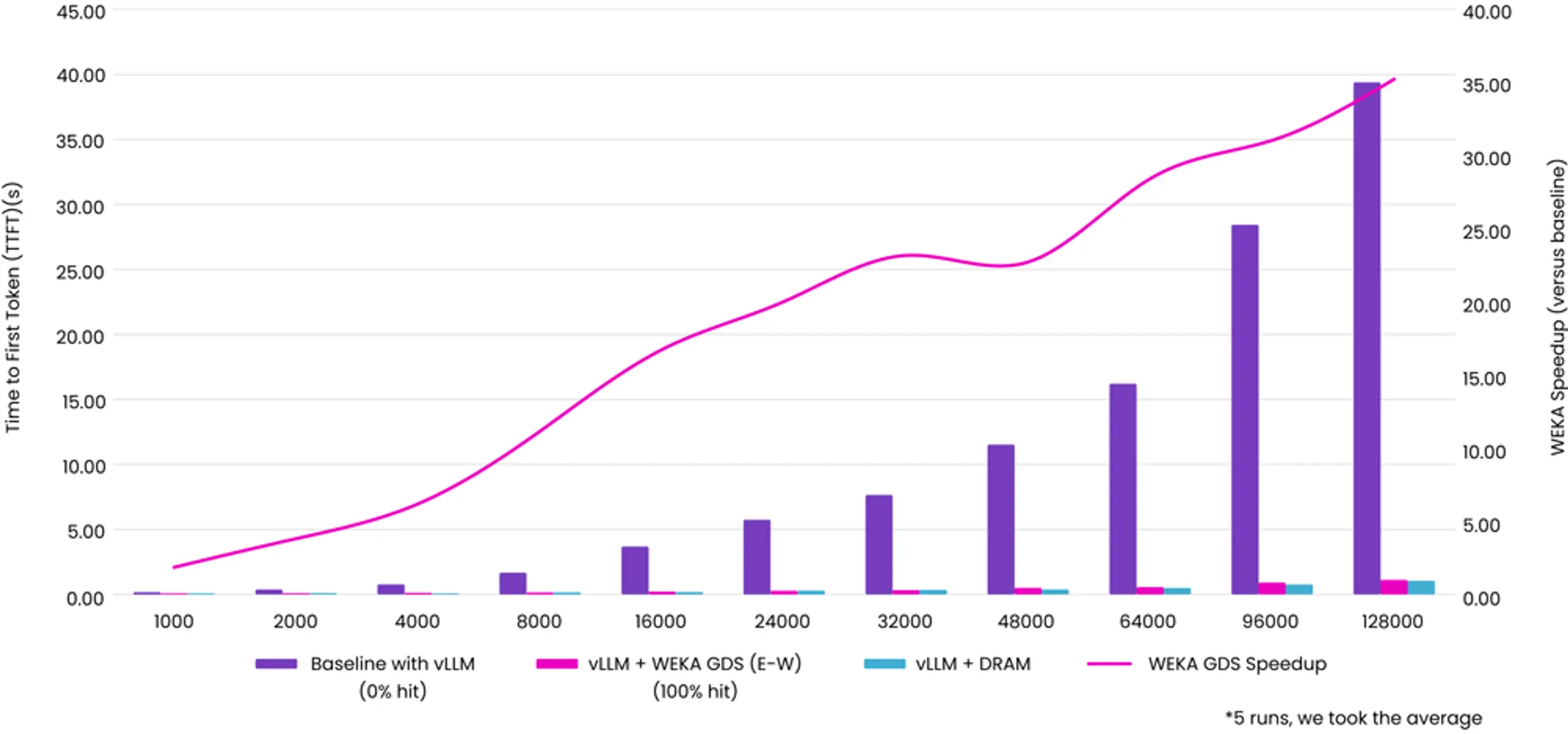
In order for the best TTFT, the inference system needs to first have the KV cache available - but it then needs to be able to access it much faster than recomputing the KV cache.
Accessing KV cache from our memory-class token warehouse is comparable to local system memory (DRAM) speeds, meaning there is no performance penalty when compared to local DRAM. This is in contrast to storage-based approaches where transfer rates can be measured in 10s rather than 100s of GB/s and in milliseconds rather than microseconds.
Here are some numbers based on Llama-405B quantized at Int4 (largest model we could fit on a single 8-way H100 test host). These numbers are based on vLLM with WEKA Augmented Memory Grid including all inference system overheads:
3. Simplified operations
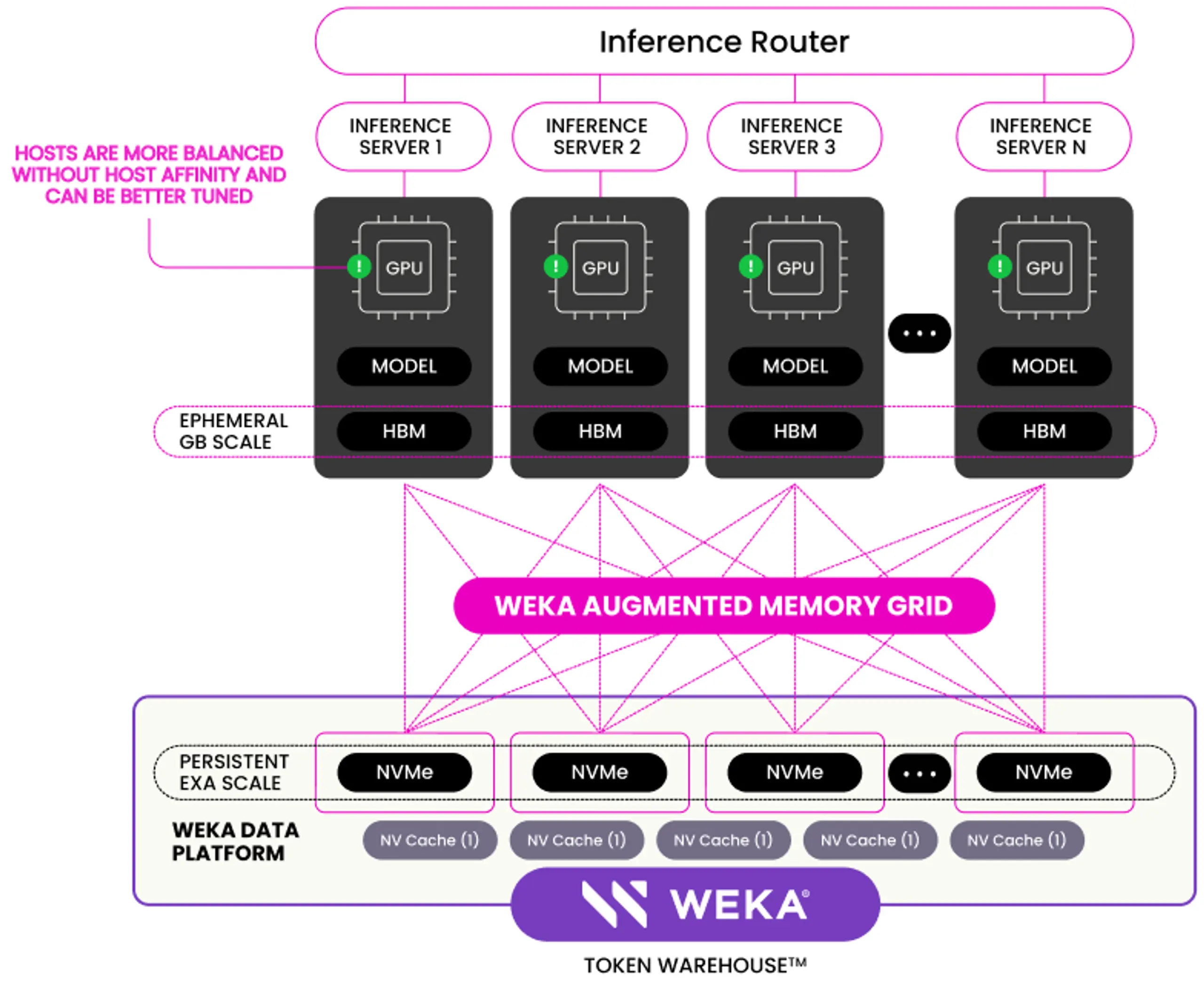
Inference is where AI meets the real world—and it's where performance, cost, and scalability collide. There are many ways to distribute inference workloads, but not all are created equal.
The simplest approach is round-robin routing: send each request to the next available GPU. It’s easy to manage and highly elastic, because nodes can come and go without drama. But this simplicity ignores cache locality. For models that rely on KV caching (like LLMs), that means poor hit rates, redundant computation, and higher latency.
More advanced strategies, like those emerging with NVIDIA’s Dynamo, aim to route sessions back to the GPU host where their cache is already loaded. This improves performance by avoiding recomputation, but introduces new challenges: session stickiness, hotspot hosts, and reduced elasticity.
WEKA’s Augmented Memory Grid offers a different path. By decoupling KV cache from local GPU memory and storing it in a high-performance token warehouse, any host can serve any session—with cache hits intact. That means better load balancing, simpler scaling, and higher throughput at lower cost.
4. More value from your infrastructure
When these benefits combine, the result is radically improved token economics.
Put simply, a higher cache hit rate means the inference system spends less time on prefill to generate the KV cache and more time on actual token generation—leading to higher aggregate output tokens, an increased output tokens per session, and reduced time to first token (TTFT).
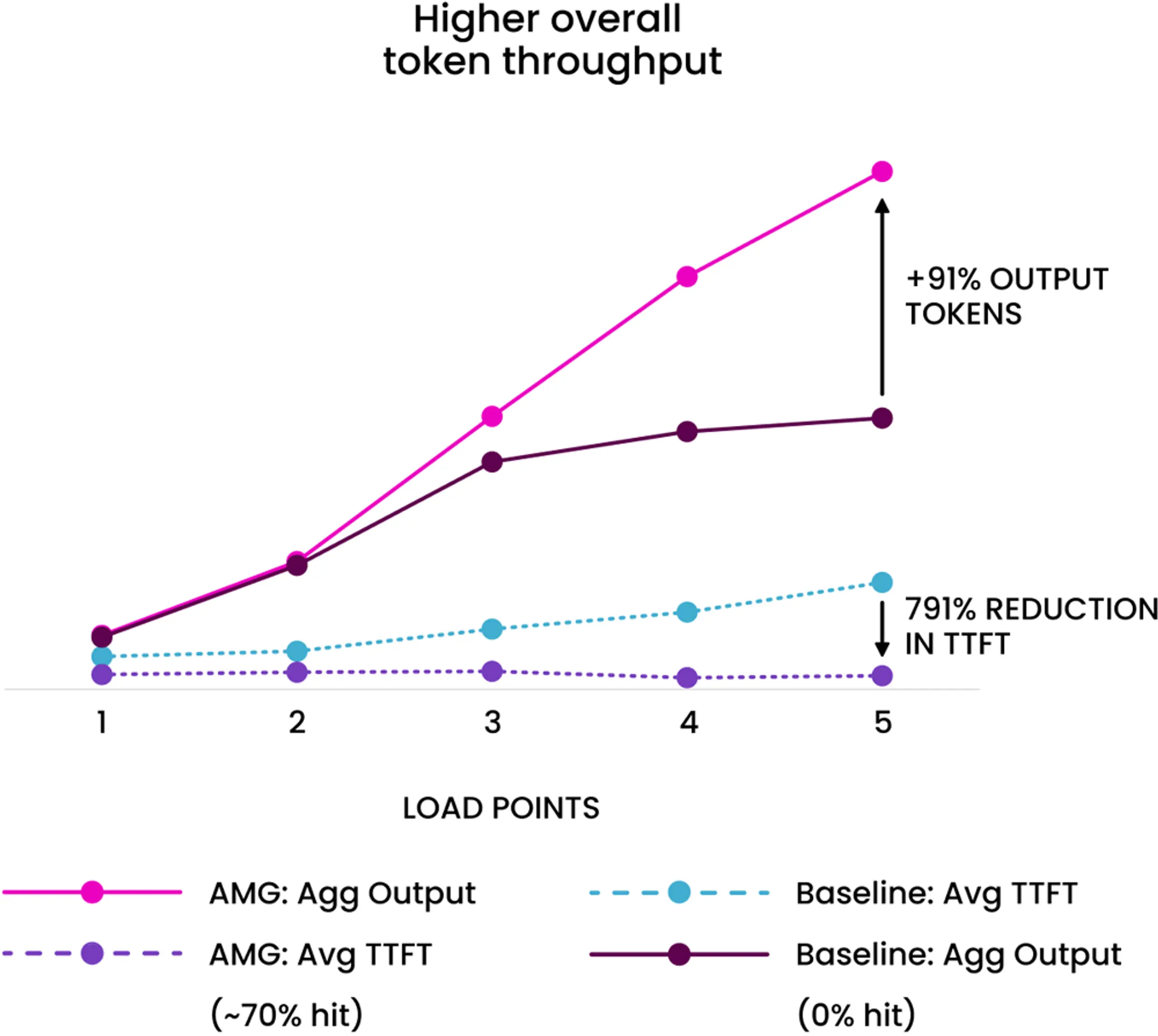
While we will expand heavily on this in a follow-on blog, here is a sneak peak into some of the benefits we are validating. For this test, we are using DGX 8-way H100’s systems with a 8-host WEKApod with 72 NVMe drives. We simulated a cache hit rate of ~68% and an average context length of a moderate 16,000 using Llama-3.1 405B quantized at Int4 (biggest model that allowed for maximum KV Cache size). The tests start with a lower query per second, and it ramps up over time.
You can see in the simple graph below that at the lower load points the TTFT is always lower (only moderately given the more moderate context length). But over time as load ramps up the GPUs cannot keep up with the load of prefill and decode (again this is aggregated prefill and decode setup), and ultimately overall system output suffers. Whereas with Augmented Memory Grid we are able to continuously ramp load, and with larger context windows the benefits only get more pronounced.
Deploying WEKA’s Memory-Class Token Warehouse
WEKA's Augmented Memory Grid supports two deployment models for the token warehouse:
- Dedicated — In this approach, storage-optimized servers (or cloud instances) with NVMe drives are used exclusively to host the token warehouse, providing high-capacity and high-performance storage independent of the GPU hosts.
- Converged — Here, WEKA runs directly on the GPU hosts, leveraging their local NVMe storage to serve the token warehouse. This integrated model delivers excellent performance within the existing physical footprint and power consumption.
We have validated converged token warehouses in existing NVIDIA Cloud Partner's (NCP) environments, as well as in Oracle Cloud Infrastructure on BM.GPU.H100.8 shapes.
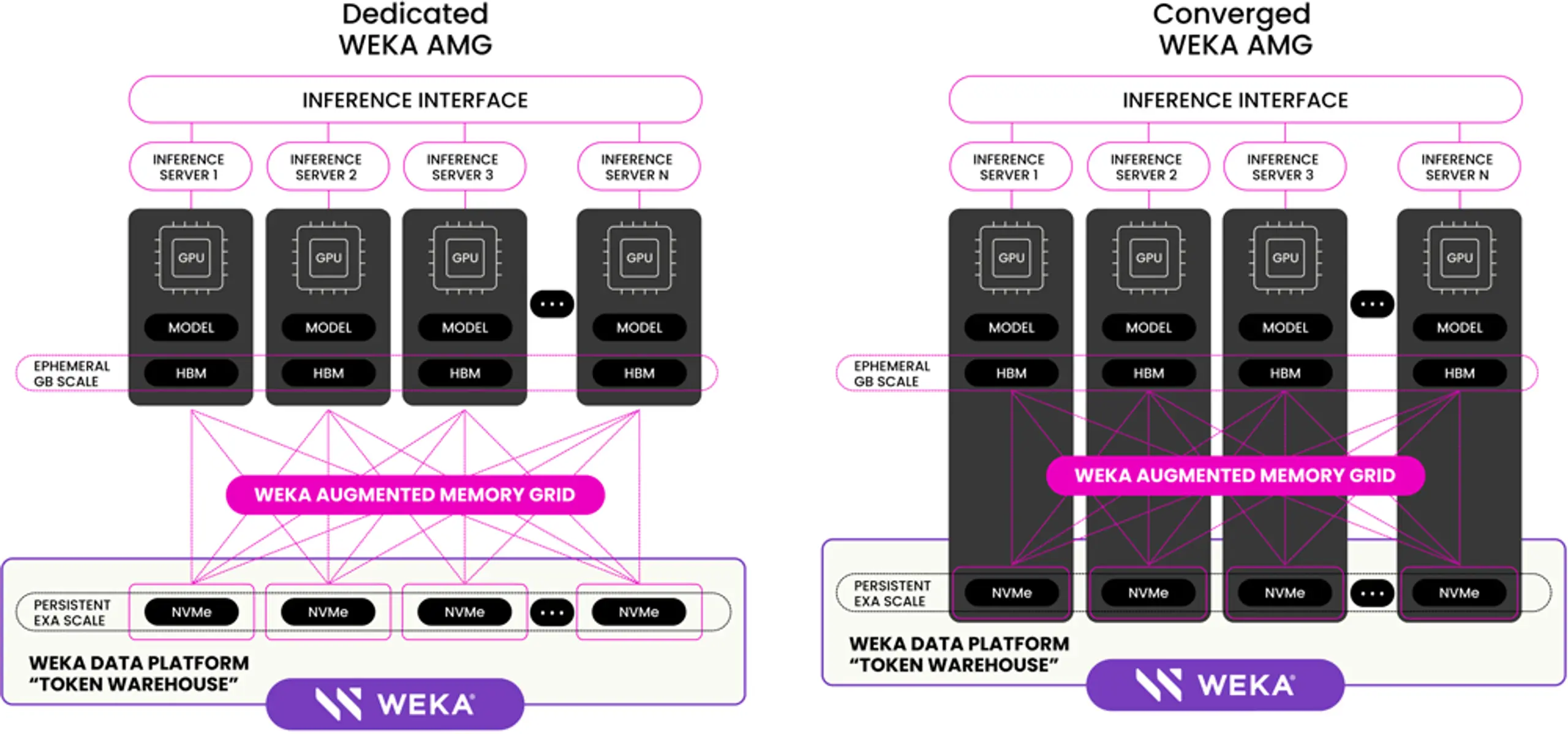
How WEKA adapts to your inference system
Our architecture is designed to extract the maximum possible performance from the underlying hardware, especially the network.
Take a standard NVIDIA-based HGX H100 system as an example. These systems typically include two distinct network paths:
- North-South traffic, which is traditionally used for storage access, with around 400Gb of bandwidth
- East-West traffic, the high-bandwidth compute fabric, delivering up to 3200Gb of bandwidth
Most storage-based systems are designed to operate over the north-south path. That’s enough for many traditional I/O patterns—but we’re not just moving files; we’re operating as a memory-class token warehouse, tightly coupled to inference runtimes. This requires more than just bandwidth—it demands low-latency, high-throughput integration with the compute layer.
That’s why we leverage the east-west network wherever possible. By operating over the same high-speed fabric used for GPU-to-GPU communication, we’re able to move data in and out of GPU memory directly, bypassing the CPU and OS stack entirely. This drastically reduces overhead and improves both latency and throughput.
Even more critically, we optimize for PCI locality, pinning reads and writes to the NICs directly connected to the GPUs. This ensures we’re not just using the available bandwidth—we’re using it efficiently, matching network topology to memory access patterns for peak performance.
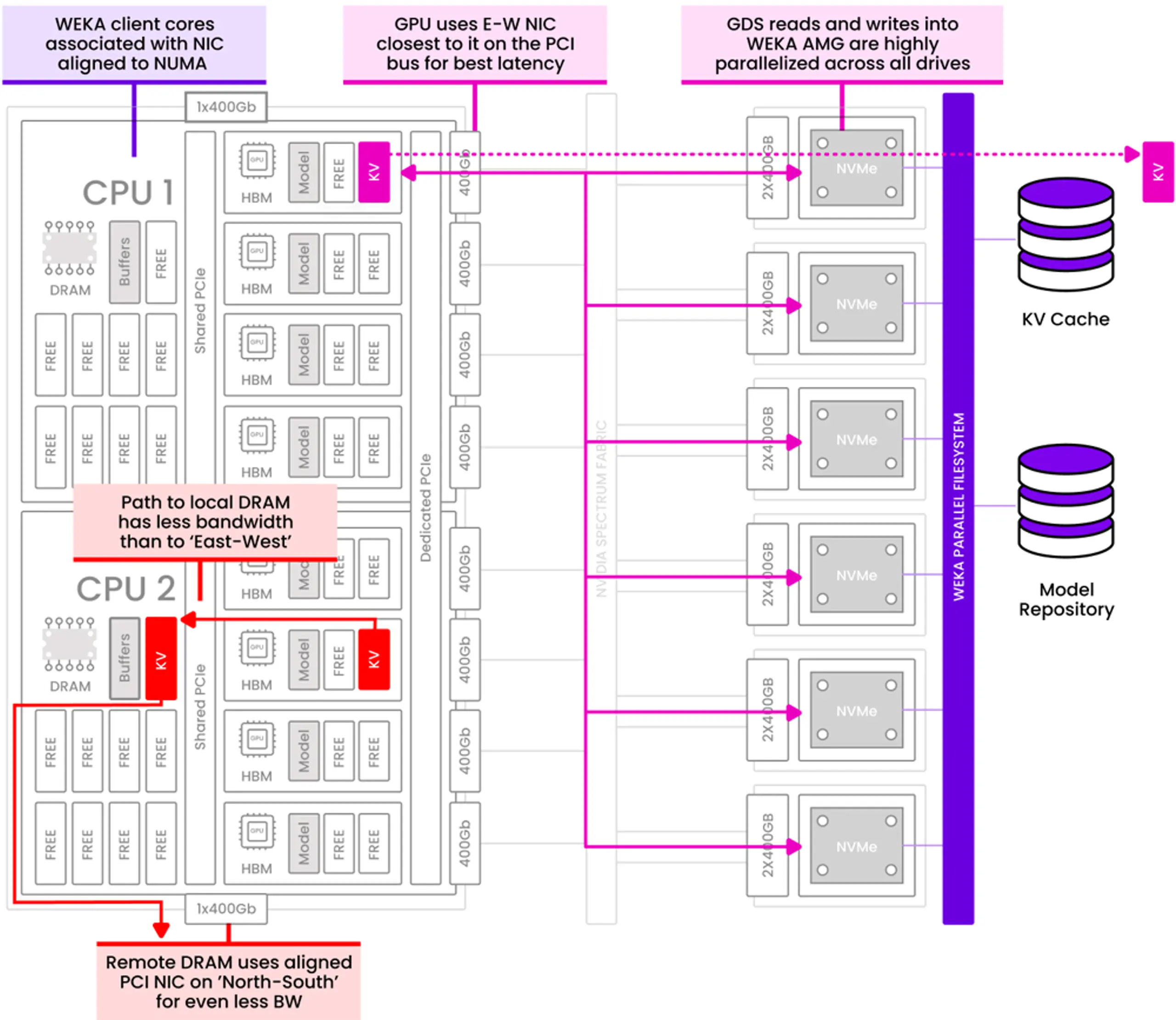
In short, whether you're running isolated inference clusters or a shared AI supercomputing environment, our system adapts to the network architecture and unlocks the full performance envelope of your GPUs.
Final thoughts
As context windows grow and models get smarter, inference workloads will only become more demanding. WEKA Augmented Memory Grid delivers the speed, capacity, and operational flexibility needed to stay ahead.
Whether you're running massive multi-turn conversations or real-time applications with tight latency constraints, Augmented Memory Grid can drastically reduce TTFT, increase overall output tokens, and simplify operations.
In the next blog I will double click on the key aspects of an equation to calculate the benefits we can give, and also give you some real world examples from our labs and customers.
Stay tuned as we continue to evolve Augmented Memory Grid and share even more results from our lab and our customers. If you are interested in your own Proof of Value (PoV) or want to give feedback please reach out to your account team or me directly or set up a meeting with us now.
What's Next



Scale Production AI Faster with NeuralMesh
Your models aren't slow. Your data is. Fix AI bottlenecks with high-throughput infrastructure.