Multi-Agent AI: Why Data Movement Matters More Than Just Compute and Memory


Rethinking What Powers Multi-Agent AI
The conversation around multi-agent systems has exploded over the past year. New entrants like Manus AI’s Wide Research, which spins up hundreds of general-purpose agents in parallel, highlight the push toward breadth and scale in reasoning. Open source frameworks such as LangChain’s LangGraph have given developers tools to orchestrate stateful agent workflows, while hyperscaler platforms like Microsoft’s AutoGen and Google’s Vertex AI Agent Builder are rapidly making multi-agent orchestration an enterprise-ready reality. Even foundation model vendors are leaning in, with Anthropic’s Claude Code pushing multi-agent approaches into developer workflows and structured reasoning tasks.
Most of the excitement has focused on model capabilities and compute horsepower — assuming that scaling multi-agent systems is simply a matter of adding more GPUs or extending context windows. But here’s the blind spot: multi-agent AI isn’t just compute and memory hungry, it’s data-hungry.
According to a recent NVIDIA technical blog, KV Cache bottlenecks are becoming a major drag in real-world deployments. Tests coordinated by NVIDIA (with NVIDIA Dynamo + NIXL setups) show that with NeuralMesh™ by WEKA®, NVIDIA was able to stream KV Cache across 8 H100 GPUs at near memory bandwidth, delivering huge improvements in latency and throughput. This proves definitively that none of the compute gains matter unless you can keep up with the data movement and scale. Only NeuralMesh has proven to make the investment count.
Why Multi-Agent Systems Consume So Much Data
Every additional agent multiplies the amount of information being generated, exchanged, and stored:
- Fan-out multiplies artifacts. A single query may spawn dozens of agents. Each generates prompts, retrieved context, scratchpads, and tool outputs that must be persisted and retrievable.
- Shared memory is essential. Agents don’t work in isolation — they constantly write to and read from a blackboard-style memory or vector store so others can refine or reuse outputs.
- Verification and pruning intensify I/O. Agents debate, cross-check, and vote on results. Each of these steps requires moving and comparing intermediate data across the system.
- Tool calls dominate payload size. Agents often fetch large JSON responses, logs, or HTML from APIs and databases, which dwarf the size of model-generated tokens.
The result is a data explosion: as agent count grows linearly, memory and storage I/O intensity grows exponentially. And if this data movement can’t keep up, GPUs sit idle, workflows stall, and costs soar.
Why Compute and Memory Alone Aren’t Enough
It’s tempting to think that fast GPUs and large memory pools can solve the problem, but they only handle local context. Once multiple agents must collaborate — sharing state, pulling in tool outputs, and updating collective memory — the bottleneck shifts to how quickly that data can move between processes, nodes, and storage tiers.
This is exactly where many multi-agent prototypes hit a wall: they perform impressively in small demos but collapse under production load when data movement overwhelms the system. Without a high-performance data mesh, scaling from 10 agents to 100 doesn’t deliver 10× more big insights; it delivers more idle GPUs and runaway costs.
The Hidden Hero: The Data Mesh
A data mesh is the circulatory system of a multi-agent platform. It ensures that all agents — whether running in parallel, debating results, or verifying branches — have instant, consistent access to the information they need. Specifically, it enables:
- Augmented memory for maximizing KV Cache hit rates at ~99%, given input:output token ratios of >100:1 for most multi-agent systems.
- Ultra-low latency exchanges so agents can read/write shared context without waiting.
- High-throughput data paths that match the scale of fan-out and parallel reasoning.
- Consistency guarantees so all agents operate from the latest version of “facts,” avoiding duplication or contradictions.
Just as HPC systems rely on high-speed interconnects to keep thousands of compute nodes synchronized, multi-agent AI requires a fast, reliable data mesh to synchronize the flow of prompts, scratchpads, and tool outputs across hundreds of concurrent agents.
Where NeuralMesh Fits In
NeuralMesh was designed for this exact challenge. It provides a distributed, high-performance data mesh that:
- Supports GPU compute networks (East-West, back-end), for maximum cluster bandwidth.
- Keeps GPUs fully utilized by eliminating I/O stalls.
- Delivers parallel I/O paths that make agent state and tool results instantly available across compute nodes.
- Maintains consistency across shared memory layers, so pruning, verification, and consensus can be performed at scale.
- Scales linearly as agent counts grow, ensuring that wide-agent systems like Manus AI’s Wide Research or enterprise orchestrators like AutoGen and Vertex AI Agent Builder can run economically in production.
By making the data layer as fast and scalable as the compute layer, NeuralMesh transforms multi-agent AI from a costly experiment into a viable enterprise platform.
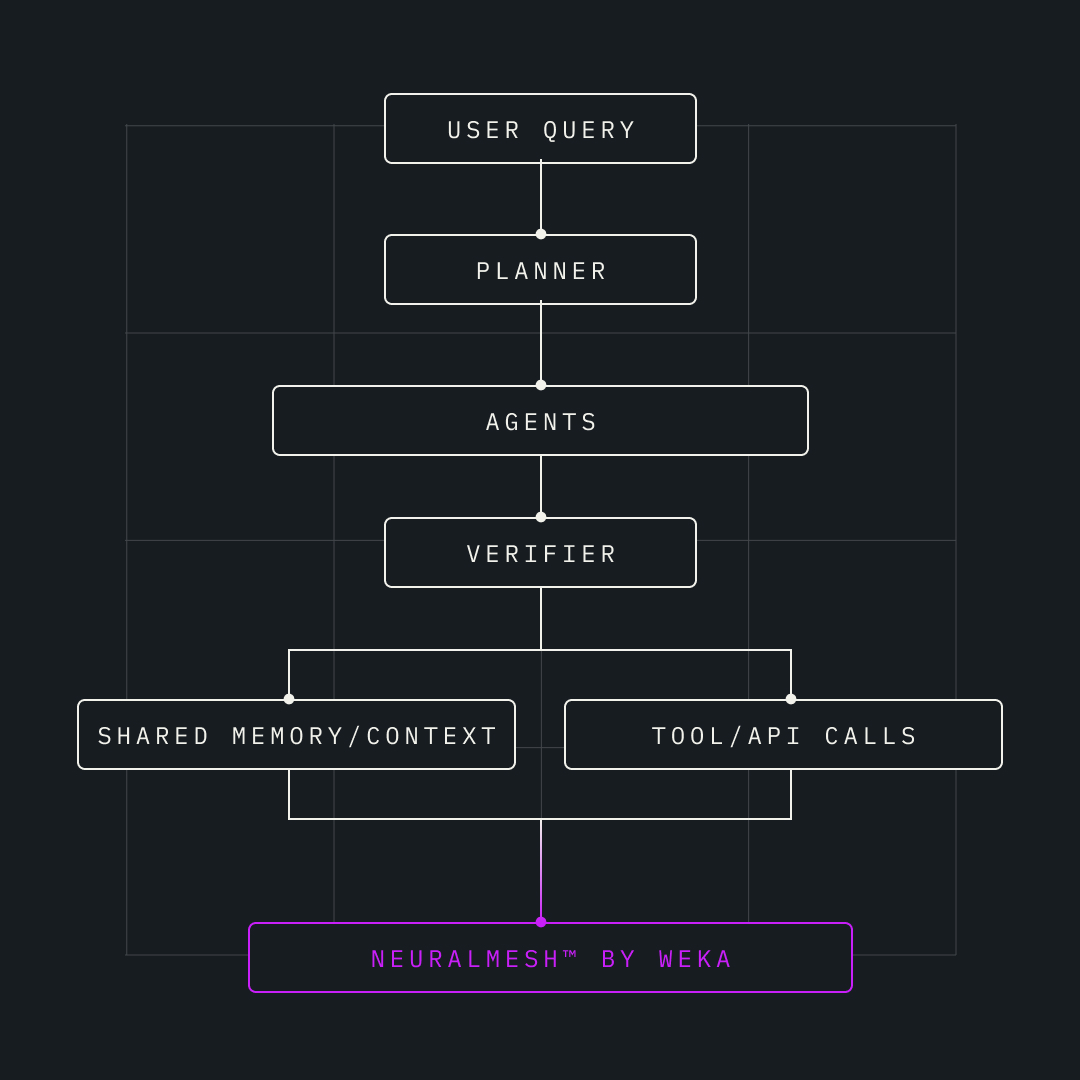
Multi-Agent System Flow with NeuralMesh.
Performance Insights from NVIDIA & WEKA
To ground the discussion, NVIDIA’s Dynamo introduces a key innovation: KV Cache offloading. Rather than holding massive attention caches entirely in GPU memory (which limits context length and concurrency), Dynamo can transfer those caches on-the-fly to larger storage tiers using their NIXL transfer library. This lets inference systems scale context windows and user concurrency without exploding cost or wasting GPU resources.
Performance tests coordinated by NVIDIA shows that NeuralMesh, using a custom NIXL + RDMA path in an 8-GPU H100 rig, streamed KV Cache “from token warehouse” at near memory speed. That means for multi-agent systems where agents are generating and reusing large context windows, NeuralMesh can keep up without huge recompute (redundant inference prefill) overheads.
Consider a simple workload:
- 10 agents each generate ~5,000 tokens of context and 10MB of tool output. That’s ~100MB of data moving across the system per round.
- Now scale to 100 agents. Compute has grown 10×, but data movement has grown 100×.
Without NeuralMesh, that 100× data growth crushes the system. With NeuralMesh, the data layer scales seamlessly, keeping throughput aligned with compute growth. This isn’t just about faster infrastructure; it’s about ensuring that scaling agents will actually yield scaling insights.
The test results coordinated by NVIDIA validate that fast data movement, low-latency offload, and cache reuse are not optional extras, but core enablers — exactly the sorts of advantages a data fabric like NeuralMesh promises.
Dive deeper into this:
- Read the original NVIDIA blog: How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo
- Read more about WEKA testing: “WEKA Accelerates AI Inference with NVIDIA Dynamo and NVIDIA NIXL”
- Get “A Visual Guide to How AI Agents Use Inference Inside an LLM” – authored by Callan Fox, Principal Product Manager at WEKA
The Takeaway
Multi-agent AI is not simply a compute/memory problem — it is a data movement problem in disguise. Every additional agent creates an exponential increase in shared context, verification cycles, and tool I/O. Without a high-performance data mesh, scaling leads to inefficiency and ballooning costs.
By providing ultra-low latency and high-throughput access to agent state and external data, NeuralMesh by WEKA ensures multi-agent systems scale smoothly, economically, and predictably. In doing so, it unlocks the real promise of agentic AI — turning parallel reasoning from an expensive prototype into an enterprise-ready capability.
To learn more, visit the NeuralMesh product page. If you would like to connect to see how NeuralMesh can help your business, contact us today.
Popular Blogs From Boni Bruno



Related Assets
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure
-
See NeuralMesh in Action

See NeuralMesh in Action
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage