Model Loading that is Faster than Local Node NVMe with NVIDIA Run:ai

In the world of modern AI, timing is everything. When customers are waiting, fraud is evolving, or workloads are scaling in real time, even a few seconds of delay can ripple into lost revenue, poor user experiences, or missed opportunities. As AI models grow larger and more dynamic, the hidden cost of slow model loading is no longer acceptable.
WEKA is changing the game with NVIDIA technology—cutting model load times by up to 40% and turning infrastructure into a competitive advantage.
AI Doesn’t Wait—and Neither Should You
Today’s AI models aren’t just bigger—they’re more dynamic. Large language models (LLMs) are growing into the hundreds of billions of parameters, requiring tens to hundreds of gigabytes of memory. Deploying LLMs in production has exposed a critical, often overlooked bottleneck – the time it takes to load the model from storage to GPU memory. Companies are adopting strategies such as copying from a central storage repository to local node NVMe storage to accelerate the load process, however this won’t work beyond a single node and cannot scale to tens or hundreds of GPU nodes.
In addition to growing larger, today’s AI models are constantly changing and updating. In production environments, models are frequently being scaled, updated, or swapped out to meet real-time demands. For example:
- Scaling dynamically to handle demand spikes, like an AI-powered customer support assistant spinning up hundreds of instances in seconds.
- Updating models frequently to stay relevant, such as fraud detection systems adjusting to new threats in real-time.
- Swapping between workloads in multi-tenant environments, where AI platforms load different models for customers or for reasoning agents.
In all of these examples, AI models have to be re-loaded from storage, and slow model loading creates a never-ending performance bottleneck as GPU servers idle while waiting for the model to load.
This is where the NVIDIA Run:ai model streamer comes in. It was developed as an open-source solution that fundamentally changes how models are loaded. Instead of waiting for the entire model to load before starting inference, it streams model weights in parallel, directly into GPU memory as needed. The accelerated servers can start answering prompts while the model loads, which slashes GPU idle time and speeds up AI readiness.
Extensive performance benchmark tests show that the NVIDIA Run:ai model streamer cuts model loading times by up to 6x compared to traditional methods. It also optimizes memory management and data movement, making it ideal for large-scale inferencing.
But here’s the catch: model streaming is only as fast as the slowest element in your infrastructure. If the data storage platform can’t keep up, you’re still left with a performance bottleneck. As noted, many companies resort to storing data on the GPU local node NVMe, but this is highly inefficient at scale. This is where WEKA steps in. WEKA eliminates model loading bottlenecks by delivering a massively parallel, AI-optimized storage architecture that outperforms even local node NVMe SSDs, ensuring seamless data throughput to keep pace with the NVIDIA Run:ai Model Streamer.
AI-Native Inferencing Without Bottlenecks: NVIDIA Run:ai + WEKA
This collaboration is more than just component-level optimizations—it’s about building a truly AI-native infrastructure. Model streamer solves a key inferencing problem, and WEKA ensures that storage that scales beyond a single GPU server never becomes the bottleneck.
By pairing model streamer with WEKA’s high-performance data storage platform, enterprises can achieve:
- Higher GPU utilization by eliminating idle GPU wait times
- Faster response times for real-time AI inference workloads
- Simplified environment eliminating the need to copy data to local NVMe to overcome slow storage responsiveness
Proven Performance: 40% Faster Than Local NVMe for LLM Inferencing
To demonstrate that the solution delivers on the performance promise, WEKA put the combined solution to the test with the Meta-Llama-3-8B model (15GB, 8 billion parameters) under 16 concurrent model loading threads, evaluating the impact of WEKA’s high-performance storage architecture.
Additionally, performance of the WEKA Data Platform was compared to abaseline setup running on the local node NVMe setup, which is often considered the gold standard for low-latency AI workloads.
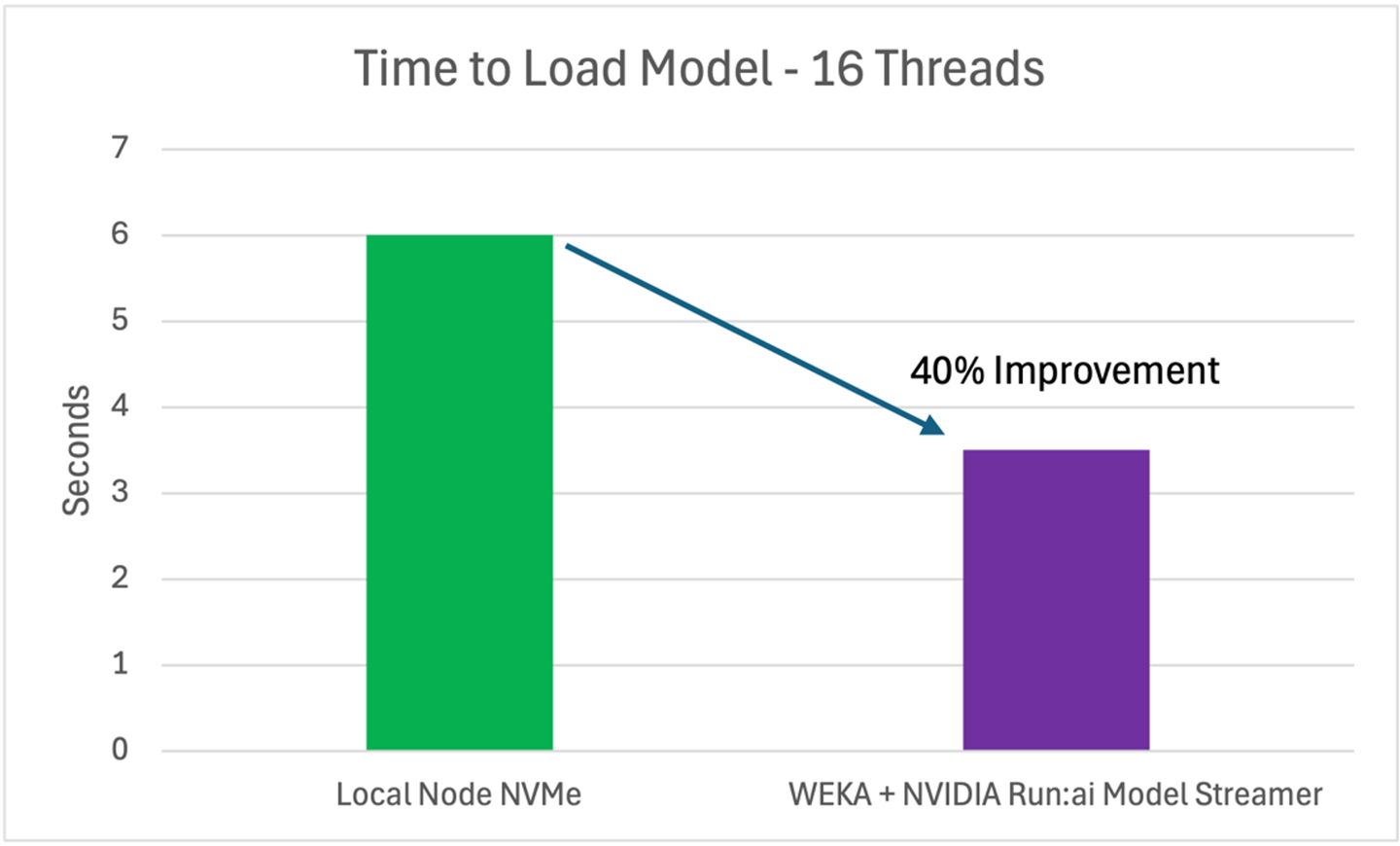
With WEKA + model streamer, the model loaded in just 3.5 seconds, about 40% faster than local NVMe storage, demonstrating the advantage of a high-performance AI-native storage platform.
What’s Driving This Performance Gain?
While model streamer accelerates inference readiness, true efficiency depends on how fast storage can deliver model weights. WEKA outperforms the limited bandwidth of local NVMe SSDs by optimizing three key areas:
- Massively Parallel Model Streaming for Multi-GPU Scaling: By distributing the model over hundreds of nodes and/or thousands of NVMe SSDs, WEKA outperforms Local NVMe SSDs. Additionally, unlike local NVMe which relies on host-side orchestration, WEKA dynamically distributes I/O across inference jobs preventing congestion and ensuring consistent performance
- Optimized I/O Throughput for AI Model Streaming: AI inference workloads demand sustained high-throughput, low-latency access. Local node NVMe will experience performance degradation under high concurrency due to I/O congestion. In contrast, WEKA optimizes I/O patterns to ensure seamless data flow and stable, low-latency access even at scale.
- AI-Native Metadata Handling for Large Model Inferencing: Handling millions of metadata requests is a key challenge in AI model streaming.WEKA’s AI-ready architecture accelerates metadata-intensive operations, ensuring instant retrieval of model weights, checkpoints, and embeddings.
When Every Second Counts, Infrastructure Becomes Strategy
In the fast-paced world of AI, speed isn’t just a luxury—it’s a necessity. Cutting model load time by 40% can have a transformative impact on real-world applications and customer engagement.
- During peak traffic events like product launches or holiday sales, AI-powered chatbots need to spin up hundreds of instances in seconds to handle the surge. If each instance takes 6 seconds to load, the delay in response times can lead to frustrated customers and lost revenue.
- In the financial sector, fraud detection systems must adapt to new threats in real-time. A 6-second delay in loading an updated model could mean the difference between catching a fraudulent transaction and letting it slip through.
In these scenarios, reducing load time by seconds isn’t just an improvement—it’s a critical advantage that keeps businesses agile, customers satisfied, and systems secure.
Streamline Your AI Future with NVIDIA Run:ai + WEKA
AI success hinges on more than just model size —it demands an infrastructure that can keep pace with real-time demands. By combining model streamer with the WEKA Data Platform, you eliminate the storage bottlenecks that even local NVMe can’t solve at scale.
Whether you’re scaling LLMs across fleets of GPUs, adapting models in real-time, or serving multi-tenant environments, this solution delivers faster load times, higher accelerated computing utilization, and a radically more efficient AI pipeline.
Stop wasting time—and GPUs—waiting on slow storage. Build an AI-native foundation that moves as fast as your business needs to.
Popular Blogs From Shimon Ben David



Related Assets
-
The NAND Flash Shortage Survival Guide

The NAND Flash Shortage Survival Guide
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure
-
See NeuralMesh in Action

See NeuralMesh in Action