From Project to Product: Aligning Technical and Business Goals in AI Deployment


TL;DR Early AI wins come fast—but once you scale, everything changes. Problems you didn’t know you had start showing up in force: bottlenecks, fragility, operational pain. I’ve seen this pattern with customers over and over. What was “good enough” early on breaks under the weight of real-world production. This post is about what happens next—how flexibility in your infrastructure gives you room to adapt, optimize, and keep moving when the pressure’s on.
AI deployments don’t stay in the lab for long. What starts as a technical experiment can quickly turn into something more—a product that has to deliver real value in a dynamic environment. The moment an AI application moves from the lab into production, the technical choices you make have real consequences for cost, performance, and your ability to adapt. As MIT Sloan Management Review points out, many AI initiatives fall apart not because the models are flawed, but because they hit infrastructure limits or business misalignment on the way to production.
These decisions are never purely technical. While technical focus on performance metrics—throughput, latency, resource utilization—the business teams are measuring ROI, time to market, and competitive positioning. In production, your infrastructure has to meet both sets of requirements at once.
The challenge is that these consequences aren’t always visible at the start. In the rush to launch, teams tend to prioritize speed over sustainability. Hardware configurations, data architectures, and workflow designs are optimized for what’s in front of you, not necessarily what’s coming next.
Flexibility in deployment is what makes that alignment possible. It’s what lets you meet performance targets and adapt as business needs evolve, without rewriting everything from scratch.
The Real Test Comes After Deployment
Once an AI model goes into production, the margin for error tightens. What worked in the lab can start to show strain: infrastructure that seemed adequate for prototypes may not scale when faced with production traffic and customer-facing demands.
On the technical side, the problems become immediate:
- Latency and throughput: Model performance in the lab doesn’t always translate to real-world conditions. Slow inference or data bottlenecks can stall user experiences and downstream workflows.
- Workload variability: Different workloads—training, inferencing, analytics—compete for the same resources. Without flexibility, the system ends up overbuilt for some tasks and underpowered for others.
- Scaling pain: Adding more GPUs or compute resources isn’t always straightforward, especially when rigid designs lock you into a single environment.
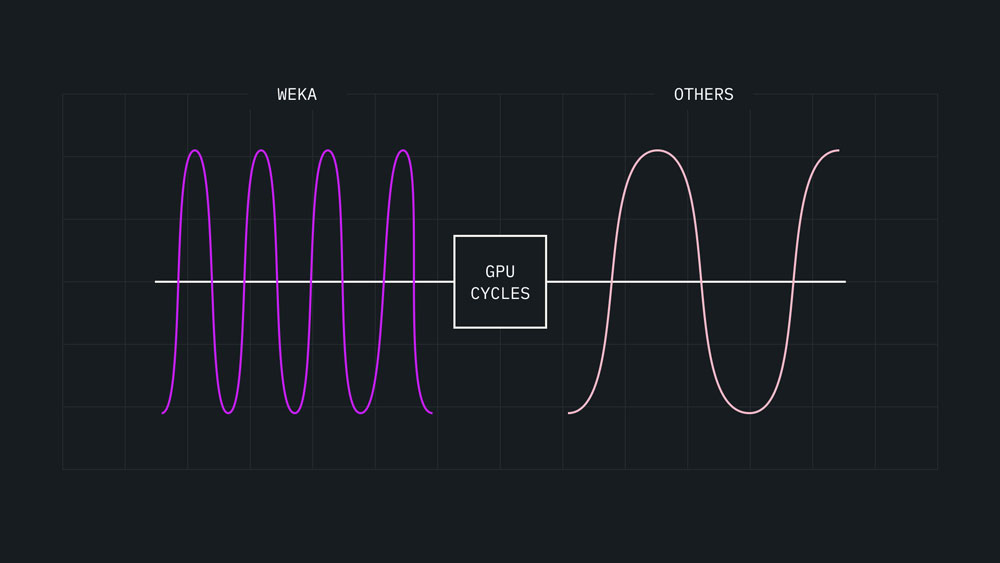
By eliminating data bottlenecks, your GPUs operate at peak utilization, significantly increasing the amount of GPU cycles a workload can consume in a single moment and optimizing your return on investment. Spoiler: NeuralMesh™ by WEKA® is designed to do this!
Business inefficiencies may take longer to surface, but the stakes are just as high:
- Unit economics: Every microsecond of latency and every GPU-hour hits the bottom line.
- Time to value: Flexibility becomes a competitive advantage. If you can’t pivot to new features or evolving AI methods, someone else will.
- Customer experience: Production failures aren’t just technical issues; they’re business risks that can erode trust and revenue.
These aren’t abstract concerns, they’re the operational realities that determine AI success or failure. The growing focus on production-grade AI—and the performance demands that come with it—as leaders push for faster, more scalable returns. The performance of AI workflows are constrained by three forces: cost, latency, and accuracy. Historically, improving one means sacrificing another, but infrastructure efficiencies – like reducing your memory dependency while ensuring accuracy – can break this cycle.
The question isn’t just whether the infrastructure can keep up. It’s whether it can adapt to what’s next.
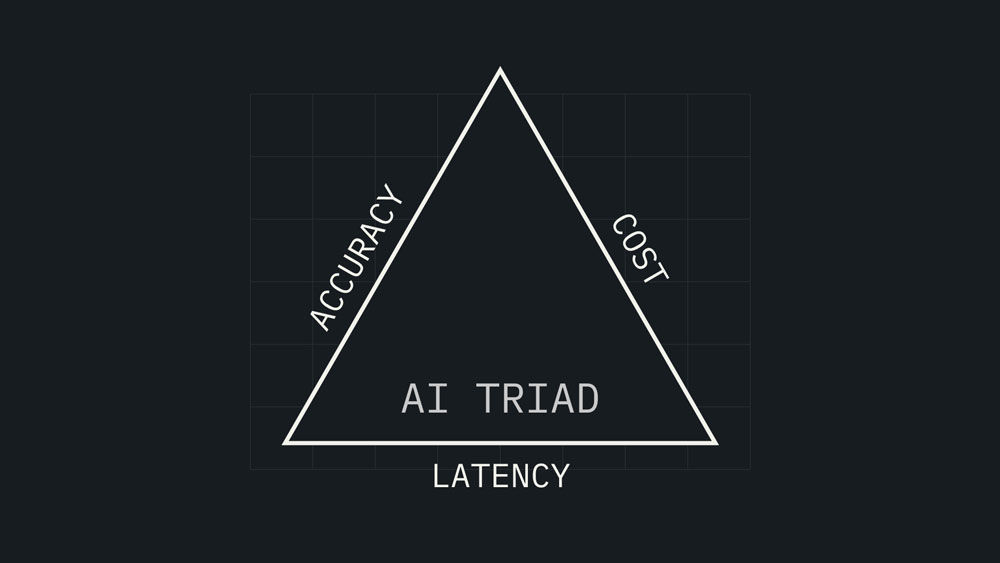
In this triangle, each side is equally important, and equally capable of becoming the bottleneck that holds everything back. When any side of this triangle falters, performance suffers.
Why Flexibility Makes the Difference
As discussed in a previous post, inflexible infrastructure doesn’t leave much room for the unexpected. But in production, the unexpected is constant: models evolve, customer demands shift, and the data you’re working with today may not look like the data you’ll be working with tomorrow.

What works beautifully in the lab often breaks under the weight of real-world scale. Flexibility in infrastructure is what keeps early wins from turning into production headaches.
Flexibility at the deployment layer turns these challenges into opportunities. Instead of starting over every time a new workload comes along, you can adjust what you have. It’s about having knobs to tune:
- Reallocating resources: Use the same hardware differently for training, inferencing, or analytics—without downtime or rework.
- Moving between environments: Shift workloads from on-prem to cloud or between cloud providers, depending on performance, cost, and business needs.
- Tuning performance: Identify and fix bottlenecks—whether in compute, networking, or storage—without compromising overall system stability.
This isn’t just a technical exercise. It’s what makes it possible to keep up with new AI methods without adding cost or complexity. Flexibility bridges the gap between what the business needs today and what the technical team can deliver tomorrow.
An Adaptable Foundation, from Lab to Market
Bringing flexibility into production isn’t a one-time fix—it’s an ongoing strategy that shapes how you build, deploy, and iterate. But there are clear starting points:
- Design for modularity: Treat compute, networking, and storage as interchangeable parts that can be reconfigured as workloads shift. Avoid vendor-specific hardware or proprietary frameworks that lock you in.
- Invest in software-defined infrastructure: Platforms that abstract away hardware dependencies make it easier to repurpose resources, shift workloads, and integrate new technologies.
- Benchmark in real-world conditions: Testing performance in controlled environments is only half the story. Production traffic exposes new bottlenecks—find them early and build in solutions that can adapt as usage grows.
- Plan for portability: Whether you’re running on-prem, in the cloud, or using GPU-as-a-service providers, your infrastructure should be able to move with your workloads—no re-architecture required.
- Prioritize continuous improvement: Flexibility is as much about culture as it is about code. Create an environment where technical and business teams can adjust quickly to new demands and measure the impact of those adjustments in real time.
This kind of infrastructure design isn’t just good hygiene—it’s becoming essential. Containerized infrastructure plays a critical role in building scalable, efficient, and portable AI systems that can evolve as demands change.
Designing for Confidence: How WARRP Makes Flexibility Operable
There’s a reason companies are turning to firms like Accenture to help navigate production-scale AI. The pressure is real. Once a model moves beyond experimentation and into user-facing environments, everything gets harder: higher stakes, more moving parts, and less room for error. It’s not just about getting the architecture right—it’s about having someone to help you interpret the complexity and stand behind the outcome.
That’s exactly the role WARRP is designed to play.
The WEKA AI RAG Reference Platform (WARRP) isn’t a one-off solution or a rigid product. It’s a modular, production-grade RAG platform that reflects everything we’ve learned about flexible design at scale.. Every customer stack is different, so WARRP is built to support variation—not fight it. We’ve engineered, tested, and vetted it across a range of real-world configurations, not to dictate a standard, but to make flexibility safe, reliable, and fast.
At the foundation of WARRP is NeuralMesh™ by WEKA®—the accelerated storage layer that lets you unify and optimize infrastructure across on-prem and cloud. But just as important is the architectural philosophy WARRP embodies:
- Modularity at every layer
- Integration with the full AI stack
- Freedom to mix, match, and evolve

From models to orchestration to outcomes, composable infrastructure only works when the full stack is modular. NeuralMesh provides the foundation that keeps everything connected and adaptable.
This approach mirrors the shift we’re seeing across the industry. In 2024, composable infrastructure was already a multi-billion dollar segment, and it’s projected to quadruple by 2029 as AI, automation, and digital transformation increasingly demand modular, flexible systems. You get to benefit from best practices that have already been proven in production, while keeping the space to integrate your internal tools, models, and orchestration layers on your own terms. You’re not boxed into a rigid stack—and you’re not left to figure it all out alone.
In a world where AI production is filled with high-stakes decisions, WARRP gives you the confidence that one part of your stack is already engineered to adapt.
Flexibility as the Path Forward
When an AI project becomes a product, the stakes get real. The only way to stay ahead is to design—and redesign—for flexibility. Make it part of how you think about infrastructure from the start. And if you’re already in production, look for the gaps where flexibility can help you adapt faster, scale smarter, and deliver real value as your AI workloads evolve.
Because in the end, flexibility isn’t just about performance. It’s about staying ready for whatever comes next.
Wherever you are in your AI journey, WEKA can help you move faster, smarter, and with less friction. Learn how NeuralMesh delivers the flexibility, performance, and control your workloads demand.
Popular Blogs From Office of the CTO



Related Assets
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure
-
See NeuralMesh in Action

See NeuralMesh in Action