Demystifying the BlueField-4 & Inference Context Memory Storage Announcement


Why This Announcement Matters
What ICMS signals: NVIDIA is formalizing Context Memory as a first-class platform requirement for the agentic era—where long-lived KV cache becomes a shared resource, not a server-local artifact.
What WEKA delivers: Augmented Memory Grid lets customers extend KV cache beyond GPU HBM today, optimize placement and movement over existing high-bandwidth fabrics, and scale incrementally toward pooled and ICMS-native architectures—maximizing GPU utilization and lowering cost per token along the way.
Since the BlueField-4 and the Inference Context Memory Storage platform (ICMS) announcement, the direction for AI infrastructure has come into focus. ICMS validates a reality many teams are already living, inference is becoming a memory-and-data-movement problem as context windows grow, concurrency rises, and agentic workflows keep state alive.
The Challenge NVIDIA and WEKA are Solving
Agentic AI is shifting workloads from one-shot prompts to iterative, long-context loops. At the center of this change are the memory tiers that are required to effectively store session state ( the KV cache). The ideal memory tier needs to address speed and capacity.
DRAM is the most common memory tier, it’s fast, but often not large enough to retain growing working sets at high concurrency. When context can’t be fetched quickly or kept resident, GPUs stall or trigger repeated prefills, reducing throughput and increasing latency.
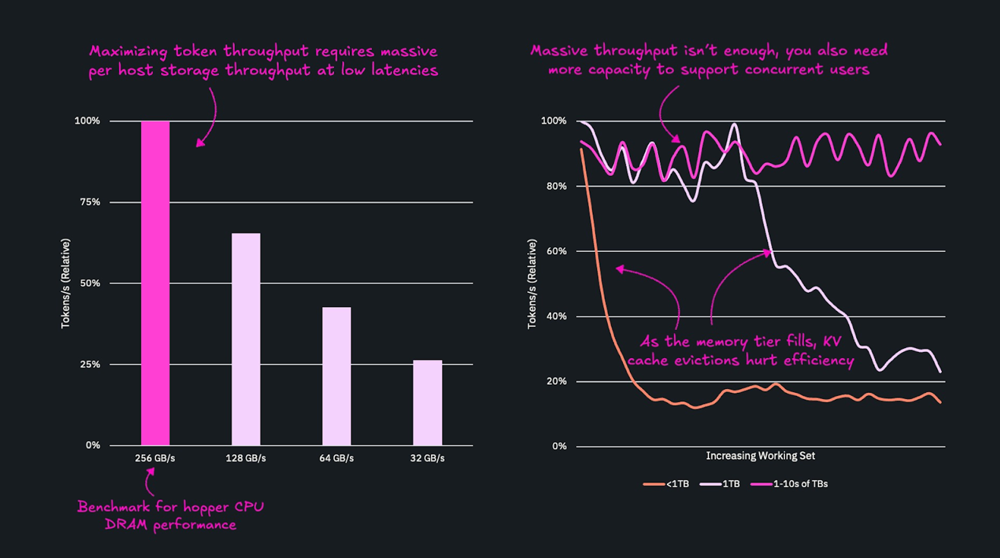
The graph below makes this explicit: the left side shows how token throughput scales with memory speed, while the right shows the maximum achievable throughput at different capacity levels. Even with high bandwidth, throughput plateaus if capacity limits cache efficiency. To sustain peak token production, you need both sufficient speed and sufficient capacity.
NVIDIA Creates a Category Platform with ICMS
NVIDIA’s technical blog on ICMS expands on how NVIDIA Dynamo (specifically NVIDIA Dynamo KVBM) thinks about KV cache placement across memory tiers:
- G1: GPU HBM
- G2: System RAM
- G3: Local SSDs
- G4: Shared storage
NVIDIA explicitly calls out the same core challenge we’ve been highlighting:
G1 is optimized for access speed while G3 and G4 are optimized for durability. As context grows, KV cache quickly exhausts local storage capacity (G1–G3), while pushing it down to enterprise storage (G4) introduces unacceptable overheads and drives up cost and power consumption.
Traditional enterprise storage architectures weren’t designed for high-performance inference context or KV cache reuse at scale. ICMS is a clear signal that NVIDIA sees the same shift happening.
Context Memory at Scale
Inference has crossed a threshold where KV cache must be treated as a shared, first-class resource. ICMS is the platform that makes this possible with a high-performance fabric plus software services that distribute, reuse, and stage context across the data center.
ICMS formalizes the category. What remains is execution—delivering Context Memory Networks that work not just in reference architectures, but in production, at scale.
NVIDIA’s Approach to Solving KV Cache
NVIDIA’s proposed solution is BlueField®-4, a next-generation DPU (or SmartNIC): effectively a mini-server with 64 cores and 800 Gb/s of networking. Paired with a JBOF (Just a Bunch of Flash) containing 32 E3.S/L NVMe drives, this enables up to 8 PB in a single 2U chassis, depending on SSD capacity.
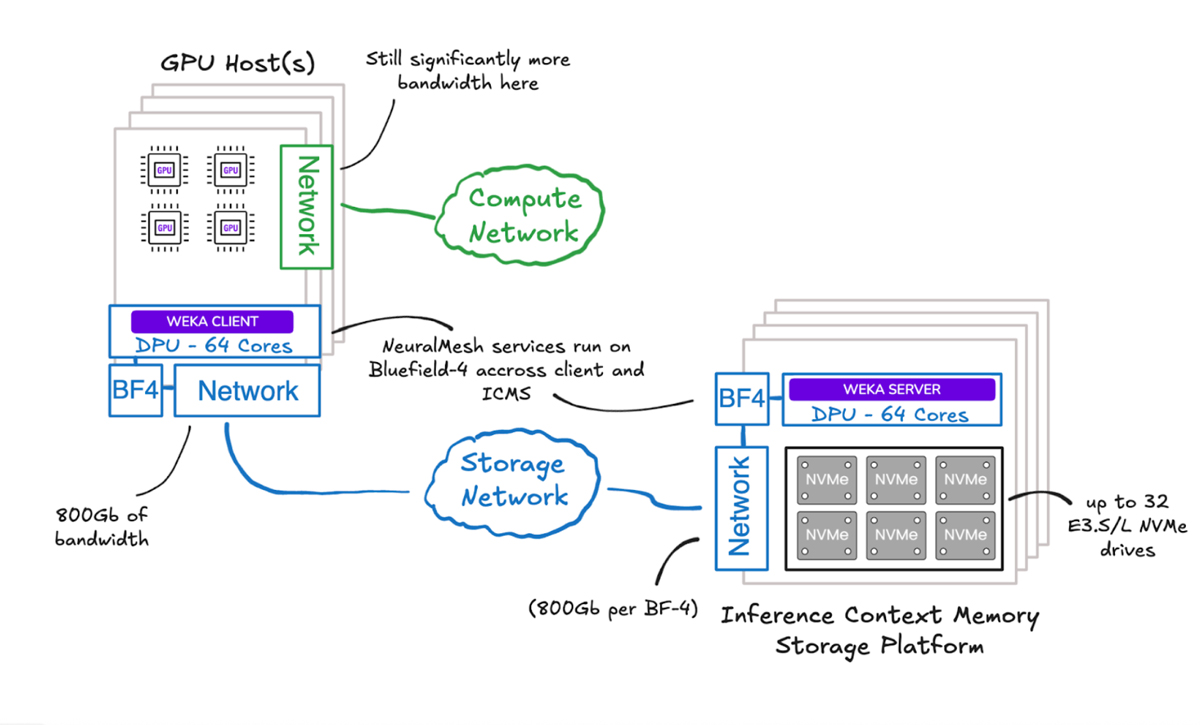
At a high level, NVIDIA’s reference architecture introduces an additional tier for inference context—pooling large-scale flash capacity behind NVIDIA BlueField-4® to support staging, reuse, and movement of KV cache beyond what fits inside the server. The key takeaway is not topology—it’s that NVIDIA is explicitly building toward shared context memory as a platform capability for the agentic era.
Augmented Memory Grid: Production Context Memory—Available Today
NVIDIA’s ICMS announcement reinforces the direction the industry is moving: KV cache is becoming shared infrastructure, and scalable, high-performance context memory is now essential for modern inference. We view this as a strong validation of the work already underway to help enterprises and cloud providers evolve toward that future.
ICMS defines the destination: a purpose-built context memory layer that extends the inference memory hierarchy and enables shared KV cache at platform scale. Getting there, however, requires practical adoption paths that work with today’s systems and economics.
With Augmented Memory Grid on NeuralMesh, WEKA enables customers to start where they are and move forward incrementally. Today, customers can extend KV cache beyond GPU HBM using familiar interfaces and standard GPU servers, delivering immediate relief from memory pressure with minimal disruption. As deployments scale, the same software-defined layer supports optimized, higher-bandwidth architectures that unlock fleet-scale efficiency and improved performance per dollar—running on infrastructure available today. We go into more detail on this concept, in this blog.
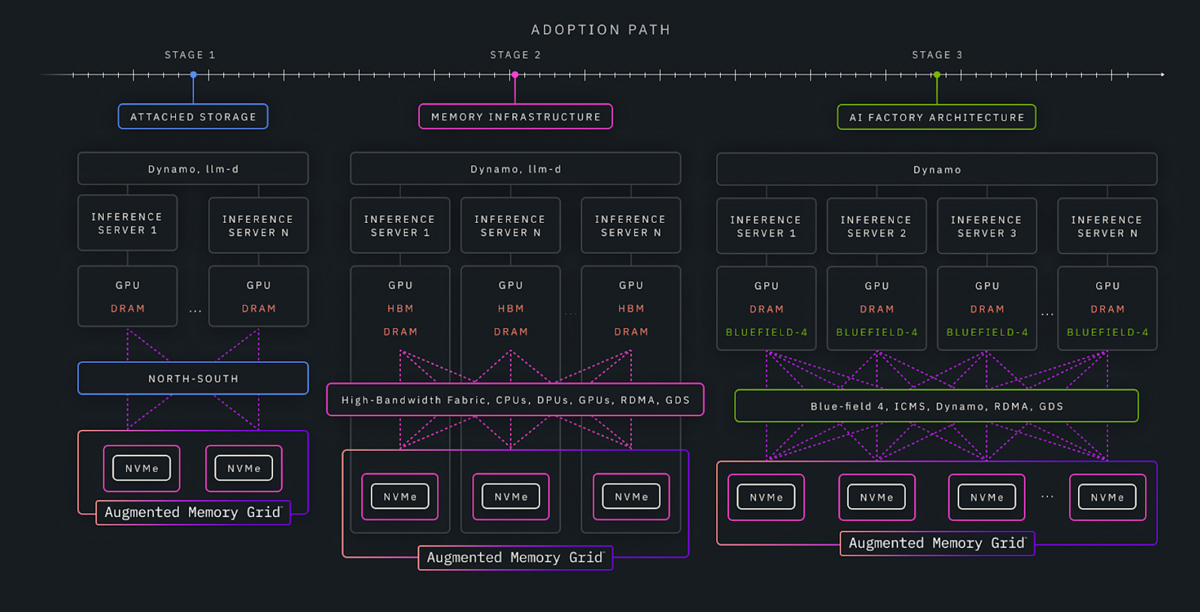
Together, ICMS, NVIDIA BlueField-4®, and WEKA provide complementary building blocks for designing and evolving shared KV-cache architectures. ICMS defines the future of shared context memory; WEKA makes it operational—now and along the path to that future.
Where We are with Augmented Memory Grid
WEKA’s goal isn’t to create a parallel universe of inference architecture—it’s to meet customers where they are, inside the platforms and ecosystems they already standardize on. That’s why we’re continuing to collaborate with NVIDIA on the practical building blocks that make inference more accessible for enterprise teams: validated integration paths, deployment patterns that fit real operational constraints, and approaches that expand KV-cache capacity without turning infrastructure into a science project.
In other words: democratizing inference isn’t just about peak performance—it’s about making these architectures adoptable by the teams who have to deploy them, secure them, run them, and scale them.
The most important point is that this isn’t theoretical. Augmented Memory Grid is designed to deliver production-grade context capacity and reuse today, improving throughput, tail latency, and GPU utilization in the environments enterprises are already running.
The Bigger Picture
WEKA’s value with NeuralMesh is fundamentally about running anywhere and extracting maximum performance from whatever components are available—x86, DPUs, GPUs, and whatever comes next. We are not tied to a specific hardware appliance or topology.
Our goal is simple: push what makes the most sense for customers. If BlueField-4 is cheaper, faster, and more efficient than x86 for a given deployment, we’ll push that. If existing infrastructure delivers better economics and performance today, we’ll push that instead.
Our flexibility is the real differentiator for us. And with NVIDIA that means we can support you across your inference stack—as you adopt ICMS, NVIDIA BlueField-4®, and everywhere in between.
Agentic AI will be won by teams that can scale context efficiently—without sacrificing latency, reliability, or cost per token. ICMS is NVIDIA acknowledging that reality. WEKA is enabling it in production now.
Learn more about how WEKA works with NVIDIA to help customers solve some of the toughest challenges in AI today here.
Popular Blogs From Callan Fox


Related Assets
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
The NAND Flash Shortage Survival Guide

The NAND Flash Shortage Survival Guide