Democratizing AI Inference: The Future of AI Should Take Minutes, Not Weeks


AI inference has become the dial-up internet moment of our time. That symphony of static, dings, and screeching modems is now replaced with loading spinners (the wheel of death), blinking dots, and double-digit seconds of time-to-first-token (TTFT)—while GPUs are stuck recomputing input tokens unnecessarily due to memory bandwidth bottlenecks.
The next frontier in democratizing AI isn’t open models or new GPUs—it’s memory. True accessibility means that every developer, startup, or enterprise should be able to run reasoning-intensive, context-rich systems without paying for redundant recomputation or building massive, bespoke GPU clusters. This requires an inference system where memory is scalable, persistent, and affordable enough to unlock AI.
This is the beginning of a new era: inference infrastructure that works for everyone, not just bespoke AI engineering teams.
Inference Doesn’t Need More Money, It Needs Better Design
The reality for inference today is that only a handful of organizations run truly advanced inference infrastructure. These organizations have the engineers and ability to control their stack to build finely tuned systems for their specific models and traffic patterns. Everyone else is left piecing together solutions that weren’t designed for the demands of modern AI.
Here’s what this looks like for everyone else:
1. Supply chain constraints limit what you can build
It’s not just GPUs—though those lead times still stretch months and capacity remains constrained. NAND for high-performance storage, networking components for RDMA fabrics, and even data center capacity itself are all bottlenecked. Teams are now competing with hyperscalers for the same limited supply across the entire hardware stack.
2. The inference stack is deeply complex
Running inference at scale isn’t just about GPUs—it’s about working around the memory wall the KV cache creates.
As context and concurrency grow, the model’s working set (KV cache) grows linearly, while HBM and DRAM stay fixed and scarce. Most of today’s “modern” inference stack is really an attempt to juggle that mismatch:
- Ecosystem layer: Routing, orchestration, and disaggregated prefill/decode frameworks
- Inference servers: Popular inference engines and model servers—each with its own tradeoffs and tuning requirements
- KV cache management: KV cache managers, as well as solutions like WEKA’s Augmented Memory Grid working together to persist, move, and reuse KV cache efficiently
- Data access layer: Direct-to-accelerator I/O libraries and APIs for memory-class data movement
Keeping all of this healthy means constantly tuning around memory pressure and KV eviction. Most teams don’t have—and can’t hire—the engineers needed to design, integrate, and operate this entire stack from scratch just to keep the memory wall at bay.
3. Token throughput—when memory becomes the bottleneck
Maximizing token throughput isn’t just about more FLOPS or more GPUs. It’s about the memory tier that feeds them.
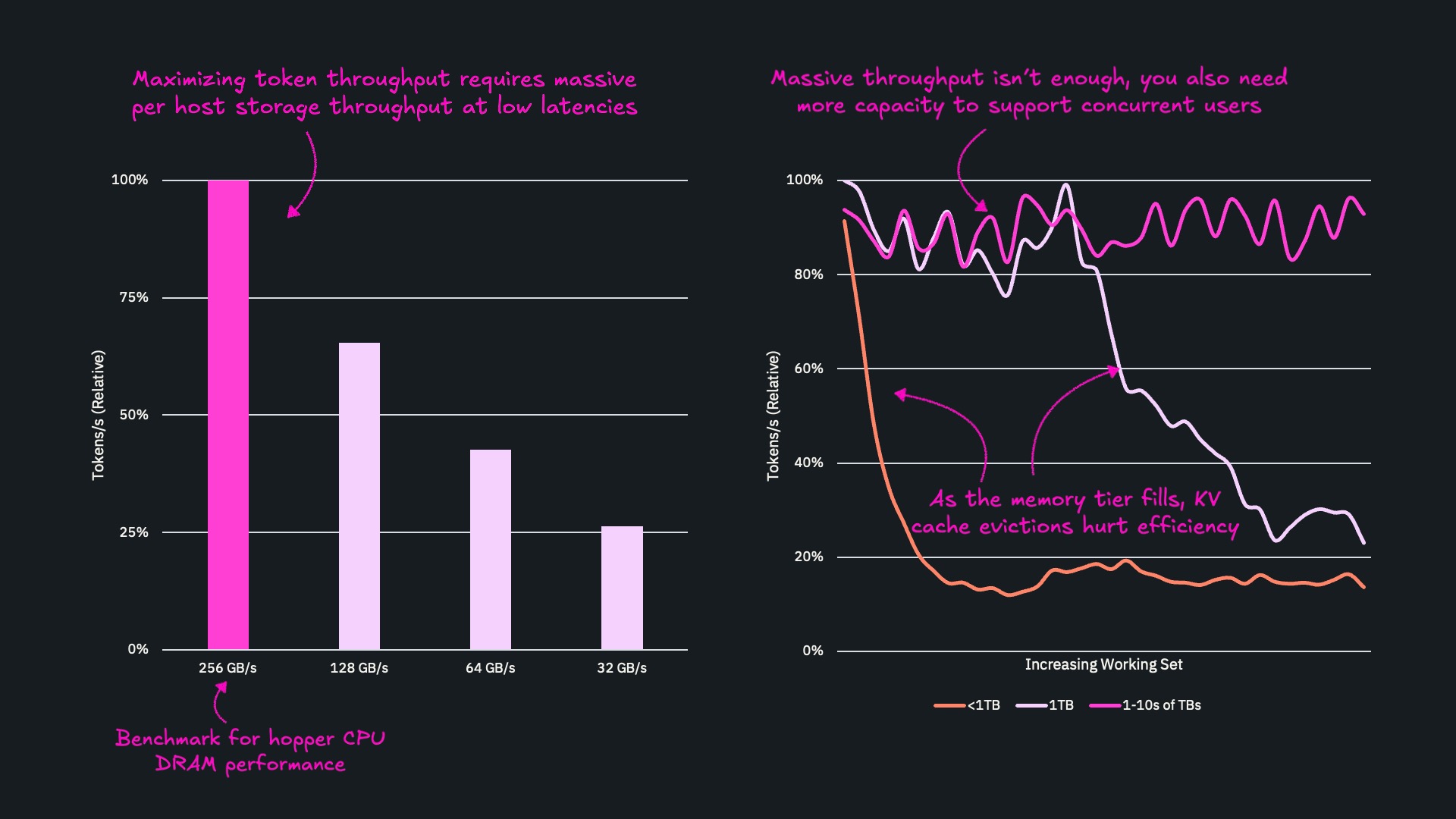
On the left, you can see what happens when your KV cache hits are perfect, but your memory tier runs at different speeds. At Hopper DRAM-class bandwidth (~256 GB/s), you can sustain 100% of your potential token throughput. As you drop to 128, 64, and 32 GB/s, relative throughput falls off sharply. Even with perfect cache hits, a slower tier starves the GPUs.
And on the right, you can see the other side of the problem: capacity. As the working set (active KV cache) grows, a small tier (think local DRAM) quickly fills up. KV cache evictions spike, hit rates collapse, and effective throughput drops toward 20%. A larger pooled DRAM tier lasts longer, but still degrades as it fills. Only when you have multi-terabyte capacity can you keep hit rates high and throughput close to 100% as more users and larger contexts come online.
WEKA is Making Significant Leaps Toward This Reality
WEKA is collapsing the barriers to advanced inference at multiple levels—from the core technology to how teams actually consume it. Augmented Memory Grid sits at the center of this, solving both KV-cache speed and capacity limits so inference can truly scale.
With Augmented Memory Grid included in NeuralMesh, turning inference from a bespoke capability only a few can run into a practical option for any serious AI team. It turns commodity NVMe into GPU-addressable memory, providing 1000x more KV cache capacity than DRAM, all—at storage prices, instead of GPU prices. Rather than requiring teams to architect complex memory hierarchies themselves, NeuralMesh packages Augmented Memory Grid into a solution that integrates with the inference frameworks you’re already using.
NeuralMesh Axon™ extends this solution and drops it directly into the GPU server. By embedding NueralMesh in the GPU, it simplifies how teams operate at scale. It provides a unified way to provision, manage, and scale training and inference workloads while improving power, cooling, and rack efficiency—making advanced AI accessible to organizations that don’t have dedicated platform teams or exotic infrastructure designs.
Open-source integrations raise the floor for everyone. WEKA has contributed open-source building blocks like LM Cache with GPUDirect Storage support, TensorRT-LLM integrations, and a dedicated NIXL plugin for NVIDIA Dynamo. These projects let builders experiment with memory-class KV cache paths and inference—even before they adopt a solid foundation—so even the core ideas behind Augmented Memory Grid are accessible to the broader ecosystem, not just WEKA customers.
Oracle Cloud Infrastructure (OCI) makes Augmented Memory Grid broadly accessible as a cloud service. With the commercial availability of WEKA Augmented Memory Grid on OCI—the only hyperscaler offering bare-metal GPUs + RDMA + NVIDIA Magnum IO GPUDirect Storage (GDS) in one integrated platform—opening the door to scalable, cost-efficient inference for everyone. OCI’s architecture is uniquely capable of running Augmented Memory Grid exactly as designed: memory-class data paths, microsecond-latency KV cache movement, and high GPU utilization—all without specialized hardware modifications.
This is democratization at every level:
- The technology removes infrastructure barriers
- The packaging removes adoption barriers
- The open-source work spreads the benefits beyond WEKA’s direct customers
- The cloud and deployment model remove operational barriers
Together, NeuralMesh, Augmented Memory Grid, Axon, our open-source projects, and OCI turn advanced inference from a bespoke engineering project into something any serious AI team can actually use—with KV-cache speed and capacity treated as first-class design goals, not afterthoughts.
Token Throughput and Augmented Memory Grid Results
Augmented Memory Grid is designed to solve both sides of the memory bottleneck at once: the speed of moving cache to the GPU and the capacity to hold it as contexts and users grow. Because it addresses both Augmented Memory Grid sustain high token throughput even as context lengths reach into the hundreds of thousands of tokens and the number of concurrent users increases—where DRAM-only designs fall off a cliff.
- It uses GPUDirect Storage and RDMA to deliver memory-class bandwidth to the GPU.
- It backs that bandwidth with NVMe-scale capacity, so the KV cache doesn’t thrash as contexts and concurrency grow.
The Results:
When you treat NVMe as a memory extension instead of a storage tier, the impact is dramatic:
- 41x faster TTFT: In WEKA’s labs, Augmented Memory Grid reduced time to first token from 23.97s → 0.58s on a 105k-token prompt.
- Up to 4.2x more tokens per second per GPU compared to a DRAM-only cache path
- 100s more users on the same GPUs: decoupling memory capacity from the GPU maintains high cache-hit rates for vastly more concurrent users on the same compute footprint than a DRAM-bound design.
Augmented Memory Grid keeps KV cache hot, prefills out of the critical path, and TTFT within user-friendly bounds—even as context windows, concurrency, and agentic behavior all scale up.
Breaking the Memory Wall for Everyone
AI progress isn’t truly constrained by funding—it’s constrained by infrastructure design.

WEKA is pushing on that design, so inference at scale is something any serious AI team can use, not just a handful of elite builders. NeuralMesh with Augmented Memory Grid delivers the same core benefit everywhere: a memory architecture that makes long-context, multi-turn, agentic workloads practical by keeping KV cache persistent, fast, and affordable.
Whether it’s embedded in GPU servers, deployed on-prem, running on OCI, or delivered through other AI clouds, NeuralMesh with Augmented Memory Grid turns KV cache from a hard limit into a lasting memory advantage.
To go deeper, check out the latest details and resources on the Augmented Memory Grid product page—and if you want to see how Augmented Memory Grid and NeuralMesh transforms inference scale, cost, and performance, register to watch this video walk through.
Popular Blogs From Betsy Chernoff



Related Assets
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
The Buyer’s Guide to AI Storage

The Buyer’s Guide to AI Storage
-
See NeuralMesh in Action

See NeuralMesh in Action