Coding Agents Go Mainstream

There’s a crucial shift in coding assistants: they aren’t just a side feature anymore. They’ve become the centerpiece of next-gen software development and the AI stack. Case in point: OpenAI’s $3 billion move to acquire Windsurf (an AI-powered coding agent) came the same day Cursor closed a new round of funding at a $9 billion valuation. These intelligent assistants go far beyond basic autocomplete; they navigate entire codebases, refactor across hundreds of files, and engage developers in rich, iterative conversations.
Yet the very capability that makes these assistants revolutionary—the ability to deliver executable, high-quality responses—demands that the agent provider prefix complex system prompts that can easily exceed 10,000 tokens, invoked tens of thousands of times. Such extensive context windows rapidly saturate GPU memory, throttling performance, stalling innovation, raising frustrating rate limits, and driving up infrastructure costs.
WEKA Augmented Memory Grid solves this problem by delivering petabytes of persistent storage for KV Cache, eliminating GPU memory bottlenecks, accelerating innovation, and dramatically reducing inference costs. Today’s AI models, and the coding agents that take advantage of them, need a KV Cache solution that provides a lighting-fast “token warehouse” at near-speed of DRAM, with the simplicity and scale of NVMe—which is where WEKA’s Augmented Memory Grid shines. Augmented Memory Grid and the memory-class speed it provides are table-stakes for responsive, accurate coding agents. WEKA’s Augmented Memory Grid ensures that the high volume of agentic system prompts and KV cache prefills are only processed by the GPU once. After that, they instantly reload at memory speed, thousands or even millions of times as the agent continues to work.
The Memory Wall: Why Traditional KV Cache Breaks Down for Coding Agents
Traditional KV-cache solutions store tokens directly in GPU high-bandwidth memory (HBM)—which is fast, but limited in capacity and very expensive.
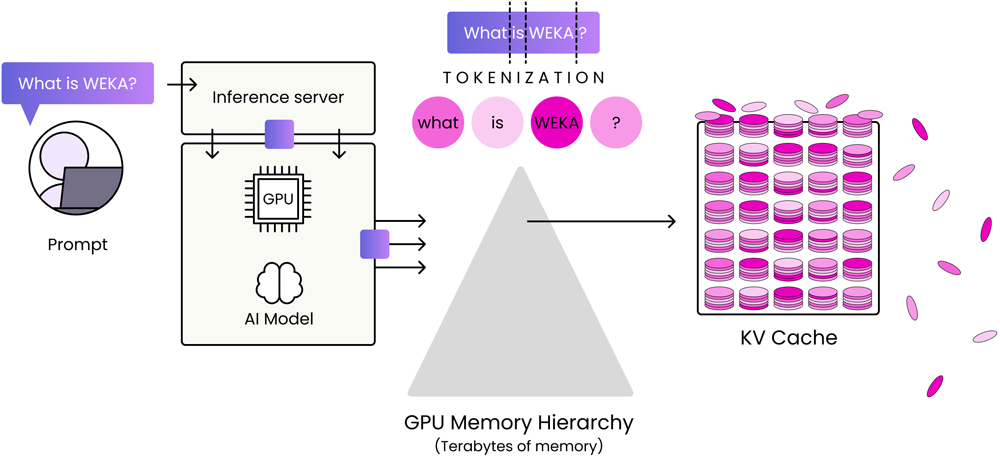
It doesn’t take much for AI coding assistants to overwhelm GPU HBM—and it often comes down to one of these common behaviors:
- IDE plug-ins and real-time autocomplete—driving complex content windows and requiring millisecond latencies to deliver results in the end application
- Speculative decode—requiring ultra-low latency and heavy re-use of the KV cache for the instant responses necessary to drive the top-K predicted code generation that meaningfully assists a developer in their day-to-day tasks
- Single-prompt multi-file edits—requiring tens of thousands of prompts to stay “live” for diff previews
- Voice mode & long conversations—increasing context windows (and tokens) because of the length and “wordiness” of a spoken prompt
- Web-source citations (e.g., Stack Overflow)—increasing prompt length and caching footprint due to external websites
Without a persistent, high-performance “token warehouse,” AI coding agents suffer low rate limits, slow response times, rising infrastructure costs, and declining accuracy.
Augmented Memory Grid: A token warehouse at Memory-Class Speed
WEKA’s Augmented Memory Grid delivers petabytes of persistent, memory-speed cache to inference pipelines. At its core, Augmented Memory Grid turns the WEKA Data Platform into a token warehouse that’s purpose-built for inference.
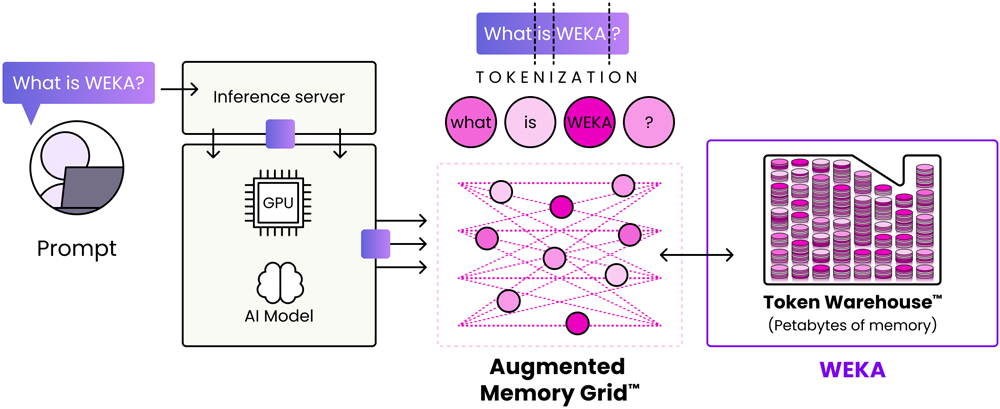
What does this mean in practice?
| Benefit | Why it matters for KV Cache-heavy workloads |
|---|---|
| Dramatically higher cache-hit rates | Llama-3-70B (FP16) stores ~326 KB per token in KV cache. With a 16K context length, 1 TB of on-board DRAM is exhausted in ~8 minutes, forcing aggressive eviction and diminished hit rates. Augmented Memory Grid’s warehouse grows that cache from terabytes to petabytes, so that hot KV blocks stay resident orders of magnitude longer. |
| Huge reductions in TTFT | With the cache resident in Augmented Memory Grid, GPUs fetch keys/values at DRAM-like speeds instead of recomputing. In WEKA labs, a 105K-token prompt saw 41× faster time-to-first-token (23.97 s → 0.58 s)—a benefit that scales directly with context length. |
| Petabytes of memory | By streaming KV-cache blocks directly from WEKA’s token warehouse to the GPU at roughly 300 GB/s*, Augmented Memory Grid effectively augments GPU memory with petabytes of additional cache, dramatically extending available memory capacity at near-HBM speeds. |
| Simplified operations | Because KV cache lives off-box yet at memory speed, you no longer have to pin user sessions to specific hosts. GPU slots can be reassigned on demand, making fleet scheduling far simpler and inherently optimizing GPU utilization throughput at scale. |
| More value from your infrastructure | When less time is burned on prefill, GPUs spend more cycles on actual token generation. WEKA measured up to 91% additional tokens generated at the cluster level for 16,000 tokens. |
*Based on DGX H100 connected to an 8-node WEKApod with 72 drives over East-West fabric in InfiniBand mode.
Augmented Memory Grid delivers a dramatically smoother coding experience, with autocomplete suggestions and inline hints appearing instantly and without perceptible lag. Entire features can be rolled out in a single shot—generating, modifying, or removing dozens of files simultaneously, all viewable in one unified diff before committing. Even richer interactions, such as speaking prompts aloud or including web-sourced content like Stack Overflow snippets, are effortless, as Augmented Memory Grid seamlessly handles larger prompts without taxing GPU memory.
Unlocking the Next Era of AI Coding Assistants
As autonomous coding agents increasingly become essential to software development, solving the memory bottlenecks that throttle their effectiveness isn’t optional—it’s critical. WEKA’s Augmented Memory Grid solves this exact challenge, eliminating GPU memory constraints, delivering dramatically faster inference performance with fewer rate limits, while slashing costs.
With Augmented Memory Grid, organizations achieve responsive, scalable, and cost-effective coding assistants that redefine productivity, turning ambitious AI visions into an immediate, executable reality.
Popular Blogs From Val Bercovici



Related Assets
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle