Agents at Scale: Escaping Upside-Down Tokenomics with up to 4.2x Efficiency


TL;DR: In production tests on CoreWeave, WEKA’s Augmented Memory Grid™ running on NeuralMesh™ Axon® successfully demonstrated that inference performance hinges on sustaining KV cache hits and avoiding token recomputation. Once DRAM’s cache capacity ceiling was surpassed, Augmented Memory Grid maintained KV cache hit rates, reduced TTFT by up to 6x and delivered up to 4.2x more tokens per GPU—all without additional hardware.
This is measured from long-context testing results. Full testing details will be published later this month in a white paper. Once live, we will update this blog with the link to read it.
Why The Economics of Inference are Upside Down
On the surface, the economics of AI look like they’re improving. Models are being optimized, GPUs are getting faster, and the cost of generating a single output token has fallen dramatically compared to even just a year ago. Developers can now spin up incredibly capable models at a fraction of yesterday’s price.
But there’s a catch.
As AI moves from single-shot prompts to agentic workflows—including coding copilots, research assistants, and multi-turn conversations—the economics flip. Context windows are regularly stretched to a maximum of 1M tokens. Even as the cost per token decreases, the number of tokens required to deliver a solution skyrockets. While today’s focus is often on reducing the cost of input and output tokens, these agentic flows introduce an additional requirement: caching at massive scale. Because these flows quickly exceed GPU memory, sustaining performance and economics requires a much larger token warehouse to keep KV cache data persistent and accessible.
Take coding copilots as an example: a quick autocomplete might burn a few thousand tokens. But a true coding agent—able to navigate an entire repo, recall prior turns, and reason across multiple files—quickly demands hundreds of thousands of tokens across chained calls. The unit cost drops, but the system cost explodes.
The real bottleneck isn’t compute—it’s memory. GPU HBM is extremely fast but limited in capacity. DRAM provides more space, but still falls short for agentic AI at scale with persistence. And while it’s possible to add more system memory, the only way to do so is by adding more GPUs—an expensive and inefficient way to scale. Once HBM and DRAM limits are exceeded, the KV cache entries are evicted, hit rates collapse, and GPUs waste cycles on recomputation. Time-to-first-token (TTFT) balloons, throughput falls, and system efficiency collapses.
Working Together to Solve the Toughest Inference Challenges
To solve this, WEKA set out to validate Augmented Memory Grid a software-defined, petabyte-scale memory solution that augments HBM and DRAM for KV Cache offload in a production-grade environment on CoreWeave.
Augmented Memory Grid extends a GPU’s memory for KV cache into WEKA’s token warehouse™, sustaining memory speeds at 1000× larger scale. Paired with NeuralMesh Axon which places WEKA directly on GPU servers, the solution removes the need for separate storage hardware—and the added power and cooling it would require.
This design provides a straightforward approach to extending GPU memory for KV cache without requiring additional infrastructure. The result? Sustained high cache hit rates across multi-turn agentic workloads, significantly reduced recomputations, and GPUs that stay focused on generating tokens instead of wasting cycles.
From Lab to Production: Real Outcomes for Agents at Scale
WEKA’s Augmented Memory Grid was validated in CoreWeave’s production cloud environment on eight servers, each outfitted with eight NVIDIA H100 GPUs—for a total of 64 GPUs. Testing covered a broad range of scenarios designed to mirror real-world agentic AI workloads.
For this blog, we’ve selected two of the most telling scenarios (and subsequent tests) for large cache: scaling once workloads exceed DRAM capacity and sustaining performance with large caches. To limit the test duration, DRAM was limited to 250 GiB, reflecting realistic per-node memory constraints without altering relative performance behavior. These results highlight what Augmented Memory Grid makes possible in real deployments:
- More sessions per GPU. Up to 4.2x higher output per GPU and per kW in multi-user, multi-turn workloads.
- Efficiency gains. Up to 6x better latency once DRAM limits are exceeded.
- Sustainability. Removing extra prefills easily saves more than tens of kilowatts per agent session, every few minutes.
- Predictable performance. In large cache tests, the Augmented Memory Grid maintained TTFT between 1-2 seconds, compared to 3-10 seconds once the DRAM’s limit was breached.
- Lower cost to serve. Deliver millions more tokens per second across large fleets without adding hardware.
Rather than incremental optimizations, this represents a new design point for inference economics: agentic AI can scale without system costs spiraling out of control.
Chart 1: Moving Past the DRAM Ceiling
When working sets grew beyond the DRAM’s capacity, its performance degraded sharply—TTFT spiked to 22.5 seconds and throughput dropped to 55.9 tokens/sec as cache entries were evicted. Under the same conditions, the Augmented Memory Grid delivered TTFT in 4.3 seconds and achieved a throughput of 153.1 tokens/sec.
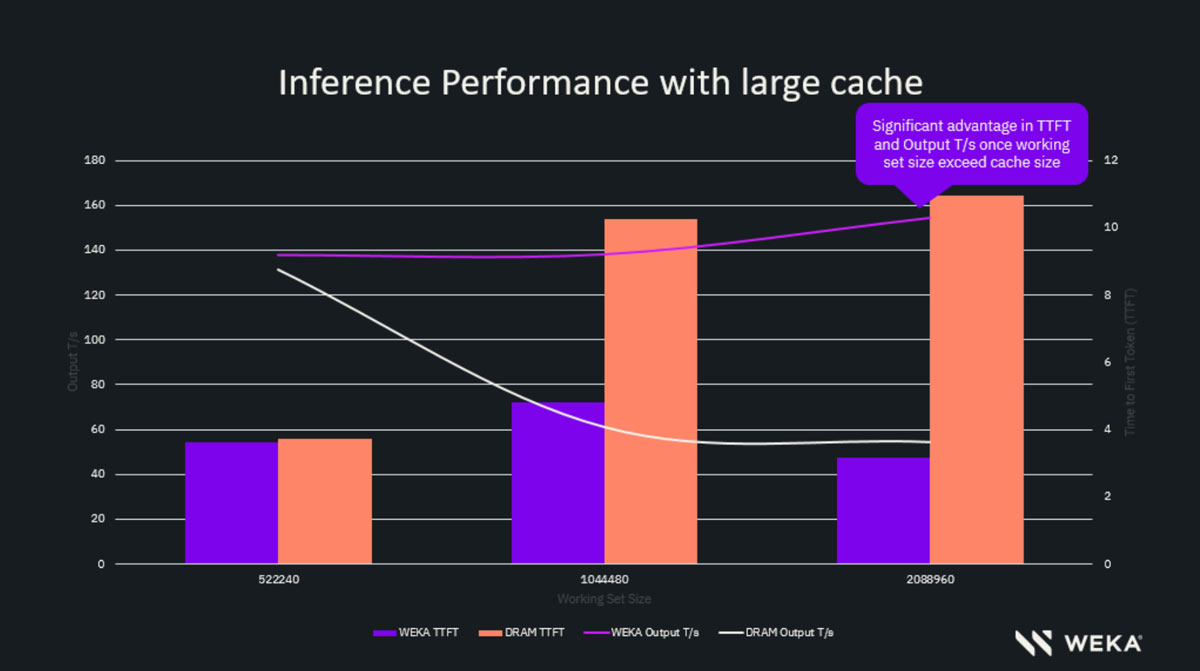
DRAM and AMG comparison with Llama-3.1-70B at 64000 context with 0%-25% users pre-warmed
Why it matters: Augmented Memory Grid achieved up to ~2.7x higher throughput and ~5x faster TTFT. This performance advantage increased significantly once working sets surpassed DRAM capacity, sustaining cache efficiency where DRAM performance deteriorated.
Chart 2: Sustaining Performance Across Multi-turn Large Cache Hit Rates
As the number of prewarmed users increased—driving up the overall cache hit rate—DRAM performance degraded sharply. TTFT spiked to 10.9 seconds, and throughput fell to 54.5 tokens/second as cache entries were evicted and recomputation increased. Under the same conditions, Augmented Memory Grid sustained TTFT at 1.8 seconds and maintained throughput at 231 tokens/second, delivering consistent performance even under high concurrency.
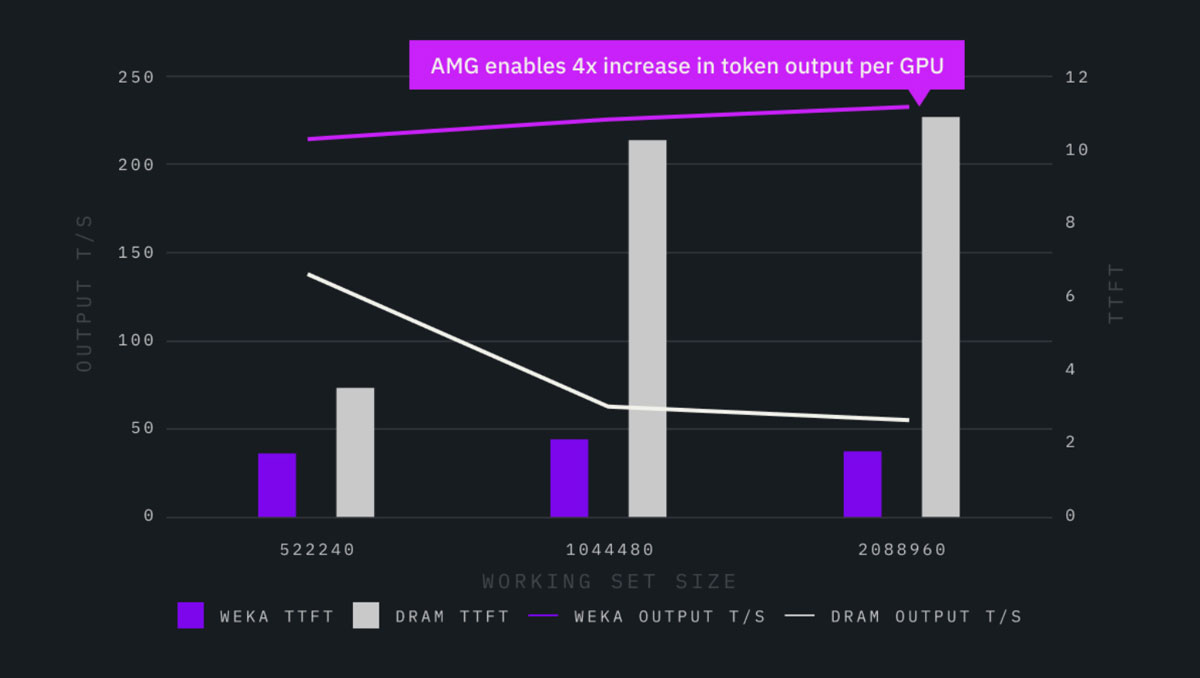
DRAM and AMG comparison with Llama-3.1-70B at 64000 context with 75% users pre-warmed
Why it matters: As concurrency and multi-turn activity increase, real-world cache pressure rises and DRAM performance degrades. Augmented Memory Grid sustains efficiency under these conditions, delivering up to 4.2x higher token output per GPU once cache limits are exceeded and up to 6x faster TTFT. By maintaining this higher throughput compared to DRAM, it enables more concurrent sessions, predictable latency, and a significantly lower cost per token.
Breaking the Memory Wall
CoreWeave, ranked #1 on the GPU Cloud Rating System from SemiAnalysis, has established itself as a leader in the AI Cloud space. Together, we’ve proven that solving inference throughput is about more than compute—it’s about eliminating costly token recomputation. By combining accelerated computing GPUs, a high-performance storage solution, and elastic cloud infrastructure, we’ve unlocked sustained cache hit rates, faster TTFT, and 4.2x more output per GPU, flipping the economics of agentic AI.
To learn more about how we’re accelerating inference at scale with Augmented Memory Grid, check out this blog, WEKA Accelerates AI Inference with NVIDIA Dynamo and NVIDIA NIXL or read our white paper, How WEKA’s Augmented Memory Grid Unlocks the Business Value of Agentic AI.
If you are interested in connecting with our team to learn how Augmented Memory Grid can help you, contact us today.
Popular Blogs From Betsy Chernoff



Related Assets
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference
-
The NAND Flash Shortage Survival Guide

The NAND Flash Shortage Survival Guide
-
See NeuralMesh in Action

See NeuralMesh in Action