AI Workflows in Financial Services: How Storage Makes or Breaks Your Models


TL;DR
In high-performance financial services modeling, data latency isn’t just technical debt, it’s lost revenue opportunities. NeuralMesh™ flips the script and helps FinTech organizations increase profitability.
- AI adoption in FinServ is accelerating, but storage infrastructure is holding groups back from profitability
- The silent performance killer, idle GPUs lead to fewer simulations and slower backtesting
- NeuralMesh fixes the gap between compute and storage, so quantitative research runs faster and models perform better
Leverage AI Workflows to Run More Quantitative Research Jobs & Make More Money
We hear lots of questions about the impact of data storage and access when it comes to modern AI and HPC optimized financial services workflows.
How is AI used in financial services environments? What are the major challenges that plague quantitative trading and high-frequency trading organizations? How can you get the most out of your expensive compute (GPU and CPU) resources?
One question that more advanced teams are starting to investigate is: How does storage infrastructure impact overall outcomes?
In this short piece, we explain how FinServ organizations can leverage NeuralMesh, WEKA’s high-performance data storage environment, to not only speed up and improve training models, but also cut the costs associated with your outdated, legacy storage infrastructure.
The Growing List of AI Uses in Financial Services
AI is used for many different functions in financial services, including testing more advanced quantitative financial trading models, performing large-scale scenario analysis and backtesting, detecting fraudulent activity, and developing intuitive risk modeling operations.
To address these market opportunities, financial services firms rely on massive datasets. HPC models can handle many of these workloads, but many organizations are turning to machine learning/AI to scale operations further.
Across the industry (and much of our customer base), we’re seeing AI adoption accelerating at breakneck speeds:
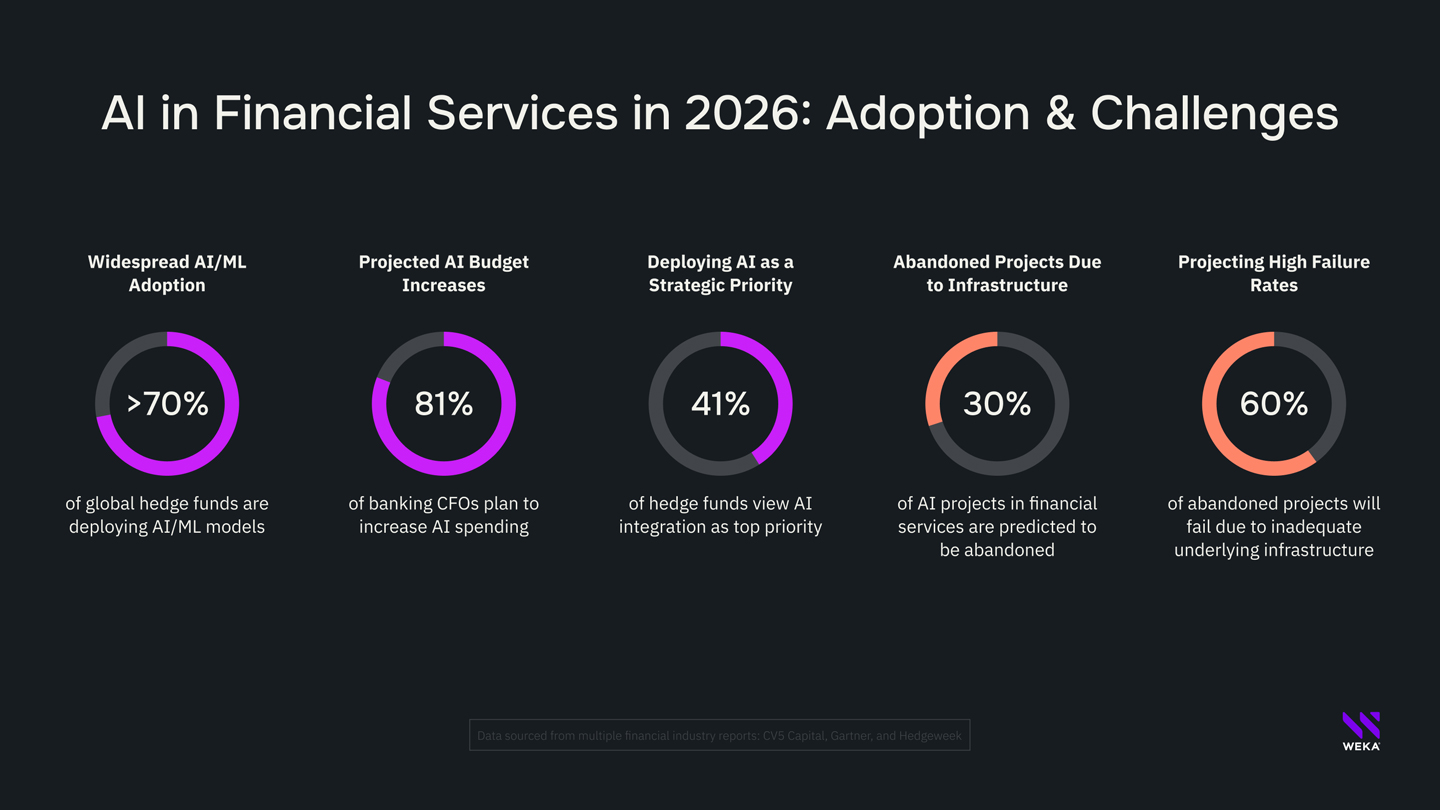
- In the quantitative trading arms race, over 70% of global hedge funds now deploy machine learning models across their investment processes, per CV5 Capital
- At the same time, to accelerate financial growth, 81% of banking CFOs are projecting an increased spend on AI uses in 2026, per Gartner
- And of all the priorities in 2026, 41% of 100 surveyed hedge fund managers rank AI integration as number one on the list, per Hedgeweek
But that doesn’t mean there aren’t challenges.
- Gartner also predicted that at least 30% of AI projects will be abandoned due to inadequate storage infrastructure
- And of those projects, roughly 60% will be abandoned as a result of poor data access and quality that can be correlated with legacy storage solutions
Financial institutions must solve their foundational data and infrastructure issues before they can successfully capitalize on the AI gold rush.
So, what does this mean? AI is not just coming, it’s here. However, many financial organizations are not truly ready to efficiently and effectively deploy AI/ML solutions without first addressing the infrastructure issues that persist across the industry.
The real answer to these challenging scenarios is a high-performance, low-latency storage platform, like NeuralMesh by WEKA.
How Can Quantitative Researchers Create More Profitable Business Outcomes with High-Performance Storage
When big money is on the line, firms need the right infrastructure stack to break down data storage bottlenecks and maximize compute performance. Bottlenecks stem from a very straightforward process:
- Data scientists and quantitative traders build complex models to identify the best trading strategies
- These models need to compute massive amounts of historical market data, which requires powerful GPUs and CPUs
- Legacy storage cannot feed data to the compute layer fast enough, resulting in GPUs sitting idle while they wait for data to arrive
- This networking inefficiency means research jobs take longer to finish and Fintech organizations lose money
Ultimately, when every single organization has the same access to data, the best models become the most profitable. So for quantitative researchers managing millions and billions of dollars, data latency is no longer technical debt. It is lost profitability. NeuralMesh allows organizations to get the most out of their compute and networking resources which leads to increased profitability.
NeuralMesh is Built for Modern Financial Institutions
NeuralMesh breaks down the storage bottleneck by bringing compute and storage into the same space, ensuring GPUs and CPUs receive data consistently.
And the numbers back this claim up. Teams using NeuralMesh experience massive performance gains, with many experiencing greater than 10x increases in performance compared to local-drive solid-state drives.
This 10x increase helps financial services professionals achieve several specific goals:
- Run research jobs much faster
- Keep expensive GPUs fully utilized
- Identify profitable trading strategies sooner
- Gain a clear advantage over competing firms
At the end of the day, CFOs care about profitability. Heads of infrastructure care about simplicity. Quants and researchers care about scale and speed. NeuralMesh delivers a storage infrastructure to make all of these desires a reality.
To see how NeuralMesh brings storage forward to complement and optimize modern compute and networking capabilities, schedule a meeting with our team or watch this demo video to see NeuralMesh in action.
Related Assets
-
See NeuralMesh in Action

See NeuralMesh in Action
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure
-
The NAND Flash Shortage Survival Guide

The NAND Flash Shortage Survival Guide