Fixing the Unit Economics of AI Is Really a Memory Problem


If you’re as passionate about AI as I am, you’ll know that building truly transformational AI systems doesn’t just require an understanding of the technology, but also the unit economics that underlie it. Unfortunately, this has become increasingly difficult in today’s AI economy. (Just look at what some OpenClaw users are doing to address their token spend.)
The reason for this has to do with subsidized pricing. We are currently living through an era of artificially low AI prices. In their effort to capture market share, AI startups and inference providers alike are covering the true costs of their services. But this can’t last forever. As the VC money funding these subsidies dries up, the actual costs of using AI will emerge. Surge pricing for tokens will be a 2026 wake-up call for many AI users. As for companies building AI-powered products and workflows, it could become a disaster.
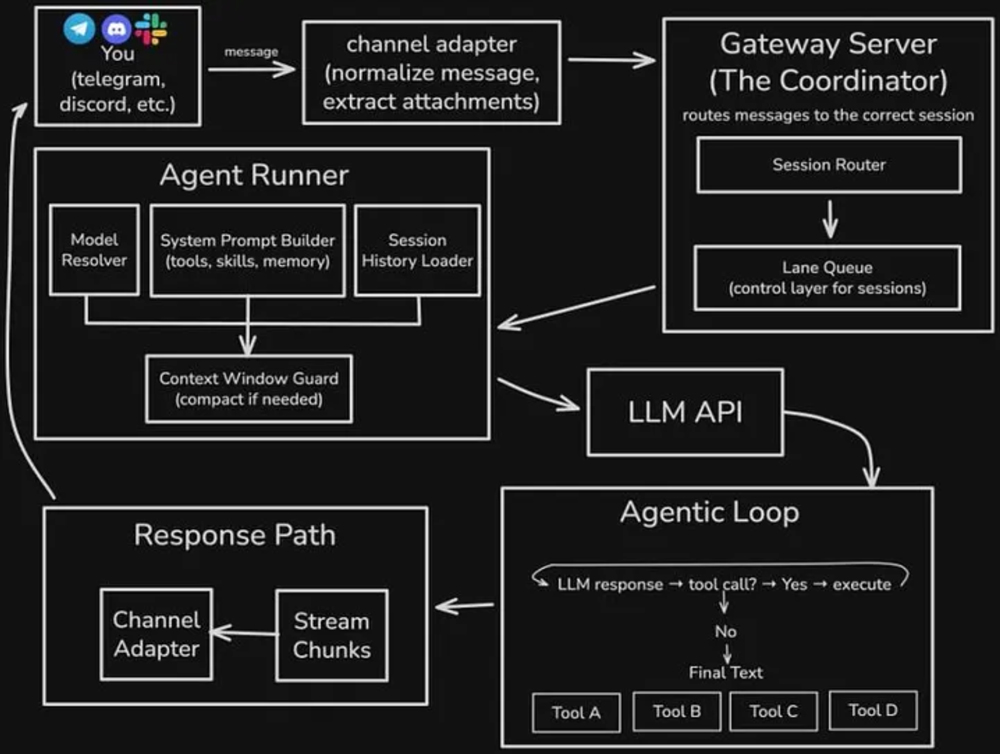
Source: “everyone talks about Clawdbot, but here’s how it works” by @Hesamation on X
In order to make their token spend manageable, many AI users are turning to Open Source solutions like OpenClaw to stack different free and paid models on top of each other. A novel solution, although its long-term sustainability is more questionable.
In a recent conversation with Greg Macatee, Senior Analyst at S&P Global, I explained what it will take to fix these unit economics (and the rate limits that often come along with them). Here’s the breakdown.
What Subsidized Token Pricing Looks Like Today
By any account, the cost of using AI today is remarkable. You can get thousands of tokens from the leading AI providers for just pennies. The largest even offer free tiers with generous terms. This has helped drive the surge of interest we now see in AI today. It has also made AI increasingly expensive to operate.
How large is the gap between retail prices and actual costs? Consider ChatGPT. While true market costs can be difficult to uncover, some estimates calculate that a single query on its o3 model used to cost more than $1,000. With OpenAI’s business plan priced at just $25 per month, it’s clear that they are heavily subsidizing the vast majority of their costs, even as new GPT 5.x models improve efficiency.
One way they are managing this gap is through rate limiting. This is the practice of capping the number of requests a user can make so that resources (like GPU memory) are evenly distributed. Otherwise, those few users who are willing to pay $20,000+ a month would consume all the tokens before anyone else.
The result of these two factors – subsidization and rate limiting – can be seen in the explosion of pricing structures and tiers. As AI companies try to maximize both users and profit, while dealing with the inherent constraints of memory, pricing has become even more complex. Just take a look at Anthropic’s model pricing and associated encyclopedia on optimizing costs. What was once a simple page just a few months ago has grown into multiple pages with over 50 different usage tiers, plus feature-specific pricing and more. That’s where we are now.
How Memory Limitations Lead to Throttling
Hidden costs. Complex pricing structures. How did we get here? It can all be traced back to a single bottleneck in AI systems: the memory wall. Understanding why requires a basic understanding of how AI models work.
The process of generating outputs based on input prompts is what we call inference. This can be generally divided into two phases: prefill and decode. During the prefill phase, the model processes the input and converts it into tokens. While this process is compute intensive, it is well within the capabilities of modern GPUs. The real issue is when it comes to storing these tokens.
At first, tokens are moved to the GPU’s high-bandwidth memory (HBM). This is called Key Value (KV) cache. But HBM is limited (for example, a NVIDIA H100 GPU has only 80 GB of HBM), a constraint that can particularly be felt when it comes to popular large models with multi-tenant or multi-part inputs. Soon, previous KV caches must be moved to higher capacity but slower memory tiers, such as DRAM. This will remove the context an agent needs to begin the decode phase, requiring more time and compute power as redundant prefill phases begin again and again, often every 5 minutes per user or agent swarm on production systems.
This is why AI companies are limiting how much memory a user or business can access. In order to maximize token throughput, sustain low-latency speeds, and maintain capacity, each user can only be allocated a certain amount of memory.
How WEKA’s Augmented Memory Grid Removes Memory Limitations
Solving the memory issue is essential for not only improving the user experience and eliminating rate limits, but also for introducing real market pricing sustainably into AI. And all this is the promise of our Augmented Memory Grid™.
Built to enable large-scale production inference, our Augmented Memory Grid effectively extends your KV cache 1000x or more beyond DRAM. It does this by bypassing DRAM completely and instead transferring KV cache tokens into a token warehouse™ stored across the GPU’s NVMe flash arrays. Whenever a user needs them, these tokens can then be quickly accessed for decoding, making it possible to eliminate redundant prefill computations altogether and improve GPU efficiency.
The result are context windows that no longer last just minutes or hours – but days or even weeks. When this happens, AI app developers no longer need to manually optimize the amount of memory capacity and bandwidth that they will logically need, enabling AI inference providers to remove throttling completely and make their unit pricing more accurately reflect the real world.
But users are the real winners here. With no more latency after an agent spins up, just think about how that affects voice agents and other real-time use-cases. The possibilities are limitless.
Improved Memory Means an Improved AI Industry
We are just at the beginning of the AI revolution. Claude Code virality in 2025 gave way to OpenClaw as we open 2026. Who knows what Q2 will bring? Unlocking even more new outcomes from this transformational technology will require the industry to confront its fundamental pricing issues so that businesses have the freedom and flexibility to build the tools and products they want. In order to do this, we need to rethink how we use memory.
Get an even fuller picture of these thoughts and more in our wide-ranging webinar: Breaking Down the Memory Wall in AI Infrastructure.
Popular Blogs From Val Bercovici



Related Assets
-
See NeuralMesh in Action

See NeuralMesh in Action
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
The Buyer’s Guide to AI Storage

The Buyer’s Guide to AI Storage