NeuralMesh Delivers 1000x GPU Memory for AI Inference on Oracle Cloud

Since introducing Augmented Memory Grid™ at GTC earlier this year, WEKA has worked closely with leading AI infrastructure partners and early adopters to understand how this memory-extension technology transforms large-scale inference. Through collaboration with Oracle Cloud Infrastructure (OCI) on joint benchmarks and real-world use cases—and deep integration across the NVIDIA AI infrastructure ecosystem—Augmented Memory Grid has evolved from a promising concept into a proven solution for AI inference at scale.
Augmented Memory Grid—Commercially Available Today on OCI
Today, WEKA is taking a big step towards democratizing inference and making it easier to consume for every builder. Augmented Memory Grid is now commercially available on NeuralMesh and OCI. This feature will make long-context, multi-turn, and agentic inference achievable with dramatically improved time-to-first-token (TTFT) and GPU efficiency. OCI’s bare-metal GPU instances, RDMA networking, and NVIDIA Magnum IO GPUDirect Storage (GDS) provide the ideal foundation to unlock Augmented Memory Grid’s full performance in the cloud.
This milestone is the result of deep technical collaboration with both NVIDIA and Oracle. Together, we’ve created a high-performance inference stack that delivers uncompromised performance for cloud-based inference. The combination of OCI’s GPU infrastructure and WEKA’s Augmented Memory Grid enables an incredibly fast and efficient environment for agentic, multi-turn, and long-context workloads—achieving up to 20x faster TTFT and significantly better GPU efficiency.
Why the Memory Wall Matters

As LLMs evolve toward agentic, multi-turn reasoning, context windows are exploding into the hundreds of thousands (or even millions) of tokens. GPU high-bandwidth memory (HBM) is blazing fast but limited in size, while DRAM bandwidth is still too slow for real-time inference at scale. Once HBM and DRAM fills, GPUs must evict KV cache entries and recompute tokens they already processed—ballooning TTFT, wasting GPU cycles, and increasing cost and power.
A persistent, high-throughput memory-cache tier is now essential. AI inference innovators are facing an inflection point: without this new tier, long-context inference remains economically unsustainable.
How Augmented Memory Grid Works
Augmented Memory Grid extends GPU memory by turning NVMe storage into a persistent token warehouse™ for AI inference. Built on NeuralMesh™, Augmented Memory Grid streams the KV -cache directly between NVMe and GPU HBM over RDMA with GPUDirect Storage. The result is a microsecond-class data path that operates like memory, bypassing CPU and DRAM bottlenecks and minimizing redundant prefill operations.
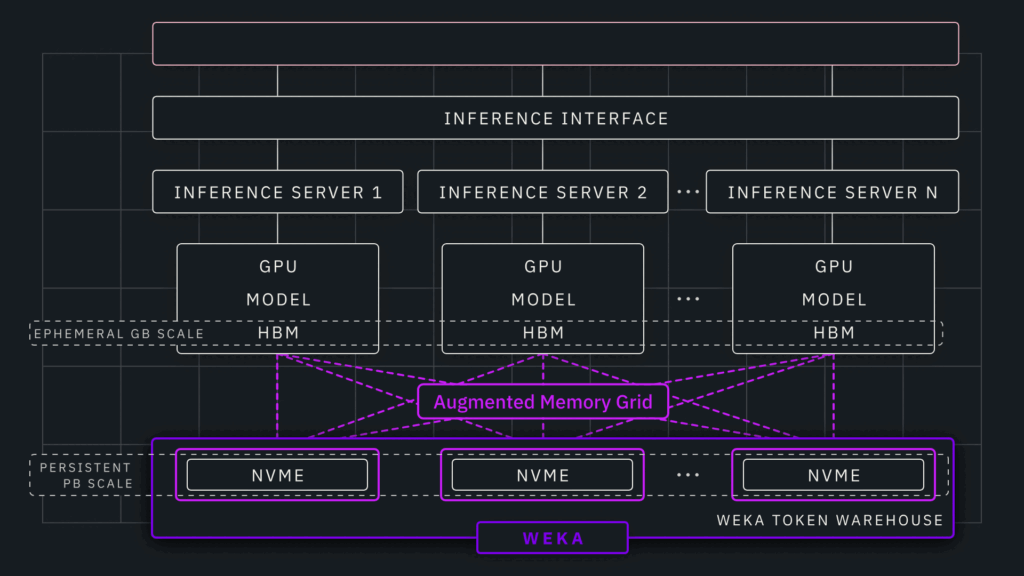
Built on an Open Ecosystem
As we continue on our mission of innovating high-performance solutions for storage and compute—we will focus on building a collaborative foundation for AI inference across the open source community and our partners for Augmented Memory Grid.
As a result, Augmented Memory Grid is tightly integrated across leading frameworks such as NVIDIA Dynamo, NIXL, TensorRT-LLM, and LM Cache. Through ongoing contributions to open -source projects, we’re enabling developers and partners to adopt persistent, memory-speed inference more easily, helping advance the entire AI ecosystem.
Results that Validate Augmented Memory Grid’s Performance
On OCI, we’ve tested and validated this solution, with results that confirm:
- 1000x more KV cache capacity than DRAM, delivered at memory speed
- 20x faster TTFT with 128,000-token context lengths compared to a prefill baseline
- 7.5 million read IOPS and 1.0 million write IOPS sustained across an eight-node GPU cluster
Running on OCI, Augmented Memory Grid empowers AI innovators to scale long-context, agentic, and multi-turn inference workloads faster, more efficiently, and more sustainably than ever before.
Get Started Today
Augmented Memory Grid is available now on Oracle Cloud Infrastructure. Visit the Augmented Memory Grid page or the OCI Marketplace to begin extending your GPU memory and transforming your inference economics today.
Popular Blogs From Betsy Chernoff



Related Assets
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
See NeuralMesh in Action

See NeuralMesh in Action