NeuralMesh Axon Reinvents AI Infrastructure Economics for the Largest Workloads


Data has become the critical bottleneck for AI workloads, often constraining compute resources and limiting the full potential of GPU clusters. Traditional storage architectures weren’t designed to meet the real-time demands of AI, causing expensive GPU resources to remain underutilized for training and memory constrained for inference. In WEKA’s recent announcement of NeuralMesh™, we addressed these bottlenecks with a powerful new software-defined storage system featuring a dynamic mesh architecture that provides an intelligent, adaptive foundation.
Yet, even the most advanced AI environments—those running thousands of GPU nodes with extreme performance requirements—can still experience inefficiencies. Organizations building massive GPU clusters often invest tens of millions of dollars only to find their expensive compute stacks idling half the time due to legacy storage systems that can’t keep pace. Conventional infrastructure struggles with the power, cooling, and physical footprint demands, and memory limitations associated with massive-scale AI deployments, further intensifying costs and reducing overall resource utilization. Although storage might seem minor in the overall infrastructure budget, inefficiencies in it can substantially amplify costs, create underutilized GPU resources, and slow innovation cycles.
Introducing NeuralMesh Axon: Breakthrough Performance, Unmatched Efficiency
With NeuralMesh™ Axon™, WEKA set out to extend the transformative capabilities of NeuralMesh to the very largest workloads, meeting the peak performance requirements of even the most demanding AI environments. NeuralMesh Axon transforms exascale AI infrastructure by embedding a high-performance storage fabric directly inside GPU servers and harnessing local NVMe, spare CPU cores, and existing network infrastructure. This unified, software-defined compute and storage layer significantly improves GPU utilization for training workloads, enhancing the overall economics of the infrastructure stack—particularly compute resources—while delivering superior storage throughput and I/O performance. Complementary capabilities such as Augmented Memory Grid further amplify performance for inference by addressing latency and memory barriers, delivering near-memory speeds for KV cache loads at massive scale. It consistently achieves microsecond latency for both local and remote workloads, outperforming traditional local protocols like NFS.
Traditional storage solutions that rely on replication-heavy methods present significant challenges, particularly in large-scale AI deployments. These legacy architectures often require multiple full copies of data across servers, which results in substantial capacity overhead while suffering steep performance drops when a node fails. This approach can lead to severe inefficiencies, including performance instability and inefficient resource allocation.
WEKA’s NeuralMesh Axon addresses these challenges by employing a unique erasure coding design. It can tolerate up to four simultaneous node losses, sustain full throughput during rebuilds, and gives organizations the ability to predefine resource allocation across the existing NVMe drives, CPU cores, and networking resources—transforming isolated disks into a memory-like storage pool for even the largest AI workloads. This method ensures consistent performance, minimizes wasted storage capacity, and maintains high utilization.
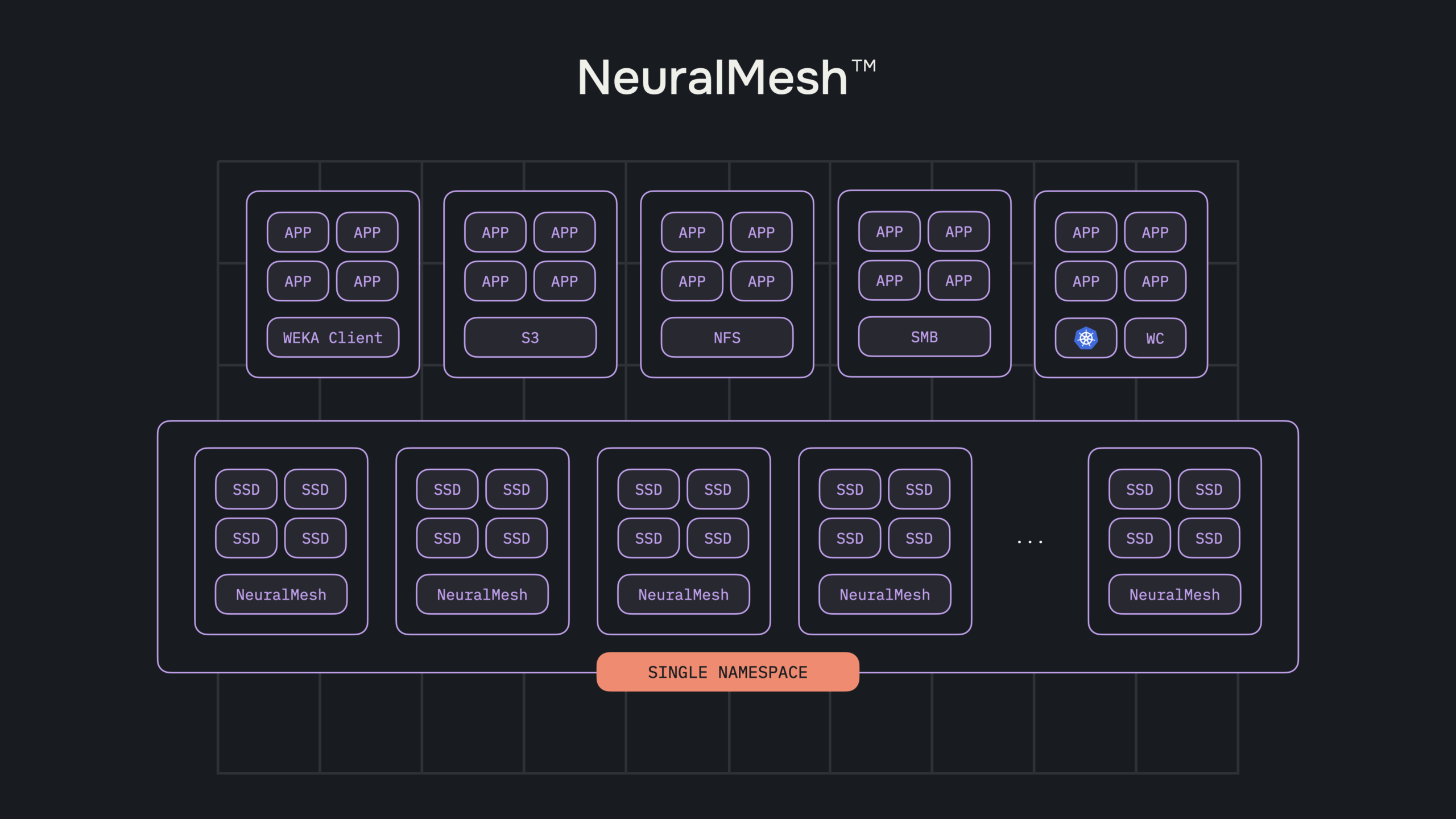

Solving Key Infrastructure Challenges
NeuralMesh Axon turns those architectural advances into real-world impact for training and inference. For their training workloads, it pushes AI workloads 3x beyond typical utilization rates so organizations can run more models on less hardware. NeuralMesh Axon also alleviates memory-bound inference constraints, especially when complimented with Augmented Memory Grid, expanding GPU memory from terabytes to petabytes, eliminating the costly practice of GPU over-provisioning and enabling larger, more efficient context windows for inference workloads. Moreover, NeuralMesh Axon simplifies operational complexity through its embedded, software-defined infrastructure, eliminating external storage systems and drastically reducing operational requirements.
These benefits are seen with the largest AI deployments, including:
- Massive GPU Acceleration and Efficiency Gains: Achieve over 90% GPU utilization—triple the industry average—resulting in reduced infrastructure costs, space, power, and cooling requirements.
- Expanded Memory with Accelerated Token Throughput: Seamlessly extends GPU memory for larger context windows and 20x faster time to first token (TTFT), enhancing token processing efficiency and enabling dynamic just-in-time training and inference.
- Immediate Scale for Massive AI Workflows: Immediate storage and compute infrastructure at the largest scale, while maintaining consistent performance across on-prem, hybrid, and cloud environments
- Focus on Building AI, Not Infrastructure: Streamlined operations across on-premises, hybrid, and cloud environments reduce complexity, eliminating the need for external storage systems and accelerating deployment timelines.
- Versatile High-Performance Storage for AI and Beyond: Delivers ultra-low latency and exceptional throughput to support diverse workloads in industries beyond AI, such as HPC, Media & Entertainment, Finance, and Healthcare.
Customer-Proven Results and Strategic Partnerships
The performance gains have been transformative for customers like Cohere, enabling inference deployments that previously took five minutes to complete in just 15 seconds and achieving checkpointing speeds ten times faster. These improvements have accelerated Cohere’s ability to iterate quickly and bring groundbreaking AI models, like North, to market faster than ever before. This translates directly into higher GPU utilization, reduced costs per token, increased throughput, and significantly accelerated time-to-market for advanced LLMs, LRMs, and agentic AI services.
These results are further strengthened by strategic infrastructure partnerships. CoreWeave has embedded NeuralMesh Axon directly into its cloud platform, achieving microsecond latencies and outstanding I/O performance, exceeding 30 GB/s reads and 12 GB/s writes per GPU server. This high-performance environment enables customers like Cohere to maximize GPU efficiency and scale rapidly.
NVIDIA further highlights the value of closely integrating storage with GPU infrastructure. By embedding ultra-low latency NVMe storage alongside GPUs, solutions like WEKA’s NeuralMesh Axon significantly increase bandwidth and effectively expand GPU memory capacity, laying a robust foundation for high-speed inference and the next generation of AI-driven services.
Looking Ahead
NeuralMesh Axon isn’t just storage—it’s a fundamental rethink of how storage, compute, and memory can be optimized for even the largest AI workloads. By fusing storage directly into every GPU server, NeuralMesh Axon erases the historical boundary between data and compute, unlocking performance headroom that was previously trapped in idle accelerator cycles and stranded NVMe drives. The result is an AI factory that gets stronger as it scales, driving dramatically higher utilization while slashing power, cooling, and rack requirements.
NeuralMesh Axon has limited availability today for both on premises and cloud deployment options, with general availability slated for Fall 2025.
Popular Blogs From Ajay Singh


Related Assets
-
The Buyer’s Guide to AI Storage

The Buyer’s Guide to AI Storage
-
The NAND Flash Shortage Survival Guide

The NAND Flash Shortage Survival Guide
-
See NeuralMesh in Action

See NeuralMesh in Action