Why Prefill has Become the Bottleneck in Inference—and How Augmented Memory Grid Helps

In my last blog, I covered the basics of WEKA Augmented Memory Grid, the deployment options for our memory-class token warehouse, and its benefits to the token economy. Now I will unpack more of the details around these benefits.
Balancing the Scales of Inference
An inference system, aiming to optimize serving potential, has two core objectives: maximize output value and do so at the lowest possible cost. But these objectives are at odds, what leads to a higher value or more accurate answer will likely also lead to a higher cost to serve. Inference providers are faced with a constant battle of the trade off between these two goals.
There are two critical phases of model execution: prefill and decode. Simply put, prefill optimizes the input tokens for the decode phase by building a data structure called the Key-Value (KV) cache. The decode phase adds to the KV cache as it decodes, or outputs tokens. Once the decode phase is complete, the KV cache must be kept somewhere that is persistent, and rapidly available for future use.
Historically, the decode phase got most of the attention. It’s where efficiency enhancements like mixture of experts (MoE) architectures emerged, helping scale inference by reducing compute overhead with almost zero impact to accuracy.
But as AI use cases become more complex, the prefill phase has become a dominant driver of the cost of inference. While before inference providers saw a swath of basic, single-shot questions like: “What’s the capital of Australia?”, they’re now increasingly seeing higher complexity, multi-turn conversations with much more context driven by more advanced users, Retrieval-Augmented Generation (RAG) and agentic workflows.
WEKA Augmented Memory Grid drastically improves the tokenomics of inference. The capabilities we are exploring in this blog are around the storing and retrieval of the KV cache. We employ various techniques to share the KV cache of one session with another session to maximize these efficiencies.
Importance of Cache Hit in Inference
The cache hit rate is the percentage of input tokens that avoid recomputation during the prefill phase. The higher the cache hit rate, the faster and cheaper inference becomes. For example, Google just revealed a 75% savings for caching of Gemini 2.5 *source: https://developers.googleblog.com/en/gemini-2-5-models-now-support-implicit-caching
Lets put recomputation impact into perspective using Llama-3.3-70B at FP16, and a moderate 12,000 context prompt on a 8-way H100 as an example:
- Computing the initial KV cache (without a cache hit) during the prefill phase takes ~3.1 seconds at a cost of 15,832 teraFLOPS from GPUs consuming around 5,600 watts.
- In contrast, a complete cache hit with WEKA Augmented Memory Grid bypasses this GPU intensive step entirely. It replaces it with a high-speed memory transfer from NVMe drives (each drawing up to ~25 watts), managed by lightweight CPU processing that’s more than one thousand times smaller, at mere gigaFLOPS. The savings are massive!
While the possible cache hit rate for inference largely depends on the use case and access patterns, with the right approach and techniques, significant gains are possible across a wide range of transformer models. Including those handling text, audio, or even video inputs.
Introduction to Prefix Matching
Prefix matching is one technique that we employ with WEKA Augmented Memory Grid, the technique matches repeated input token sequences (divided into pages) across inference sessions. Where a match is found, the precomputed KV cache can be used instead of recomputation.
These matches (or hits) can be complete or partial, and an input sequence must be the same from the very first token (including the system prompt) to ensure no impact to accuracy due to cross attention mechanism.
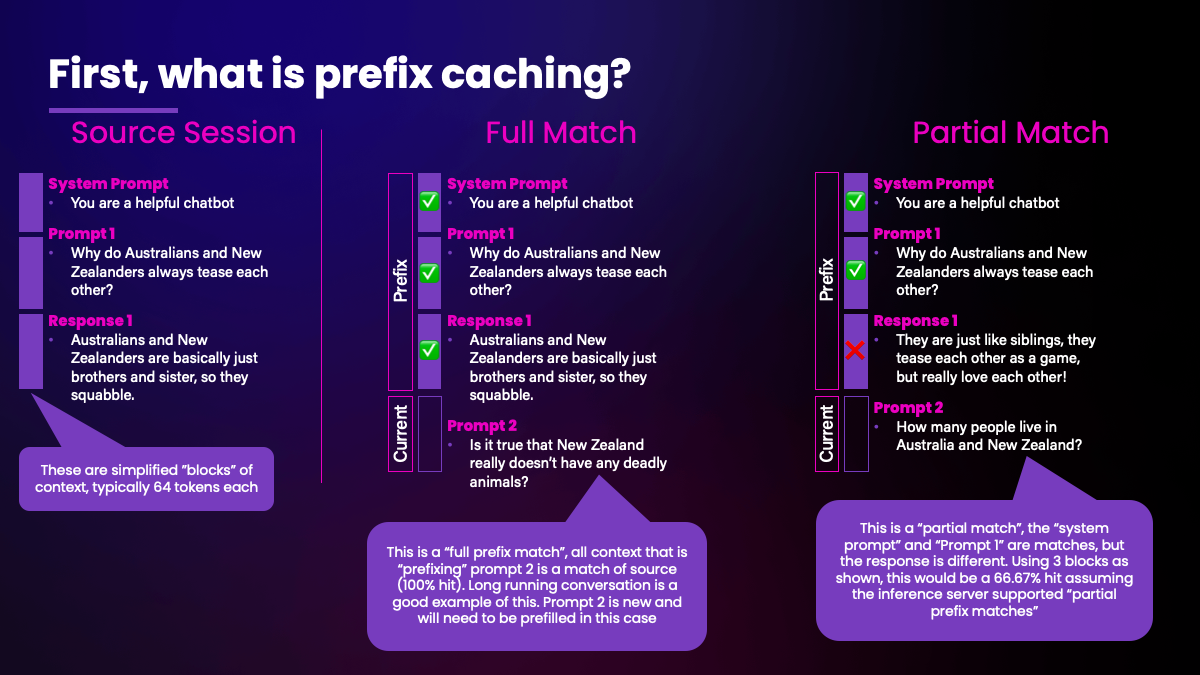
Lets look at the key factors that explore our effectiveness using this technique for an inference system.
Rapidly storing the KV cache
Before a prefix match can be made, the initial KV cache must be first generated and then stored somewhere. Now ideally this would stay within a GPU’s High Bandwidth Memory (or HBM) but that just isn’t practical most of the time due to immense pressure on HBM.
When storing the cache outside of HBM, WEKA Augmented Memory Grid stores KV Cache rapidly and asynchronously to maximize efficiency and solve for two main drivers:
- First, inference providers often use large, memory-hungry models for better accuracy. Even with high-HBM GPUs like NVIDIA H200 or AMD MI300X, these models often barely fit on 8-way systems using tensor parallelism, leaving limited free HBM. This leftover HBM is what sets the number of concurrent sessions or tokens that can be batched together. To achieve optimal batching, rapid eviction of cache from HBM is essential to quickly liberate space.
- Second, the prefill rate matters, or how fast GPUs generate the KV cache. If the prefill rate is faster than the storing of the KV cache, then precious HBM is being used to buffer caching operations at great cost to overall efficiency. The prefill rate varies by hardware, model, quantization, and input length. For example, on an 8-way H100, Llama 3.1–70B hits ~19K tokens/s, while Llama 4 Maverick hits ~50K tokens/s. On Blackwell or specialized chips like Cerebras, rates are much higher and growing quickly with each generation. If storage of KV cache cannot keep up with the prefill rate, the system will never get ahead.
Sizing of the KV cache
So how fast can WEKA Augmented Memory Grid store? Well that depends on the size of the KV Cache and the token warehouse we have sized for the solution. As an example, utilizing our memory-class token warehouse based on an 8-host WEKApod with 72 drives in our Lab for Llama-3.3-70B at FP16, a single client 8-way host can store at a rate of ~493,000 tokens/s.
But to be specific, the size of the KV cache varies based on the model, any quantization strategies, and the input length:
- Smaller models like Qwen2.5-1.5B-Instruct (FP16) have tiny footprints, just 28KB per token, making them trivial to store and retrieve. Larger monolithic models scale up fast: LLaMA-3.3-70B (FP16) uses around 326KB per token, and LLaMA-3.1-405B (FP16) hits 516KB per token.
- Mixture-of-Experts (MoE) models employ different strategies. LLaMA-4-Maverick-17B-128E (FP16) comes in lower at 192KB per token, while Deepseek-V3 (FP16), a more heavyweight MoE model, requires a massive 1,748KB per token.
- As input sequences increase, the caching requirements quickly grow. Every day we see more use cases that have increased context lengths. We are seeing agentic workloads or code generation use cases where the system prompts (or the instruction given to the model before the user prompt) are stretching into ranges of 5,000–22,000 tokens. This is before any user prompt is even added.
Here is a table to show the size of the cache at varying context lengths at FP16 as a comparison:
| Model | 1,000 tokens | 10,000 tokens | 100,000 tokens | 1,000,000 tokens |
|---|---|---|---|---|
| Qwen2.5-1.5B-Instruct (FP16) | 0.028 GB | 0.28 GB | 2.8GB | 28GB |
| LLaMA-3.3-70B (FP16) | 0.326 GB | 3.26 GB | 32.6 GB | 326 GB |
| LLaMA-3.1-405B (FP16) | 0.516 GB | 5.16 GB | 51.6 GB | 516 GB |
| Deepseek-V3 (FP16) | 1.748 GB | 17.48 GB | 174.8 GB | 1,748 GB |
Extremely Fast Retrieval of the KV Cache in a Cache Hit
It is very difficult to predict when a session will need access to KV cache ahead of time – so prefetch of cache is almost impossible. So what does that mean? Well when a session needs access to a KV cache (or part of one), it needs to be serviced extremely fast to prevent the GPUs from waiting. This is where it pays to talk in microseconds rather than milliseconds.
With WEKA’s Augmented Memory Grid’s integration with our memory-class token warehouse we can retrieve tokens extremely fast. As an example, based on testing within our Lab with a 8-host WEKApod with 72 NVMe drives a single 8-way H100 (with tensor parallelism of 8) demonstrated a retrieval rate of 938,000 tokens per second.
One challenge we had to overcome here was getting the inference server and the KV cache offload to keep up, when you can retrieve so quickly the overhead implied by the scheduling of the inference server can be quite high. This is because a TTFT number includes the decode of the first token, and in an aggregated prefill and decode the switching overhead can be quite high (more on disaggregated prefill in the future).
| Context Lengths (tokens) | Prefill rate baseline (vLLM) | WEKA & LM Cache TTFT |
|---|---|---|
| 50 | 0.084s | 0.046s |
| 1000 | 0.1396s | 0.0602s |
| 2000 | 0.2012s | 0.0557s |
| 8000 | 0.4212s | 0.09656s |
| 16000 | 0.8785s | 0.2588s |
| 24000 | 1.35269s | 0.2444s |
| 32000 | 1.7986s | 0.1944s |
| 64000 | 4.0928s | 0.497s |
| 96000 | 6.97s | 0.3995s |
| 128000 | 10.5378s | 0.51919s |
Ensuring the size of the cache provided by WEKA Augmented Memory Grid and our token warehouse is absolutely critical. We are developing sizing tools to simplify this for our customers.
We found that many of our customers had insufficient caching with the existing strategies (usually pooling local DRAM). In some cases the customer had less than 15 minutes worth of cache on average before recomputation would occur. This problem isn’t just confirmed to small inference providers, even the large labs state Time To Live (TTL) metrics in the 5-15 minutes often with no SLA around a guarantee.
WEKA Augmented Memory Grid allows for the sizing of the cache to be disaggregated from the size of system DRAM and replaced with NVMe at magnitudes more capacity density. With NeuralMesh Axon (covered in the last blog here), the footprint for this storage can be the NVMe already in your GPU compute servers to add this capability without any additional infrastructure.
Tying It All Together
We’ve discussed cache hit rate and the system optimizations needed to improve it, but we haven’t yet addressed how much this actually benefits overall inference. We are building tools to help our customers understand the impact, but let’s go over the specifics.
We’ve optimized the prefill phase, so the next question is: how much time does this use case actually spend in prefill?
- The lengths of input and output tokens – If a use case features short prompts, say 500 tokens, and a long generation of around 1,000 tokens. Then prefill phase accounts for only a small fraction of total inference time, even if you achieve a 100% cache hit rate the benefits would be almost negligible. However, generally the ratio of input tokens to output tokens is at least 20:1.
- Model architecture and quantization – Mixture-of-Experts (MoE) models which are effectively models with many submodels activate a subset of the model weights per token, they behave very differently than monolithic models in terms of prefill (and decode) performance.
- Type of GPU – This impacts the prefill (and decode) rates. With features like disaggregated prefill and decode, we’re enabling customers to optimize resource allocation, pairing the right GPUs with the right workloads. This is increasingly important for organizations managing the financial and operational overhead of high-value GPU deployments.
Here is a subset of the data we have collected for sizing, this sample highlights the % of time a model spends in prefill based on different model types, using 256 output tokens on a single 8-way H100 DGX running vLLM. It clearly illustrates the differing performance patterns between modern MoE architectures and large-scale monolithic models.
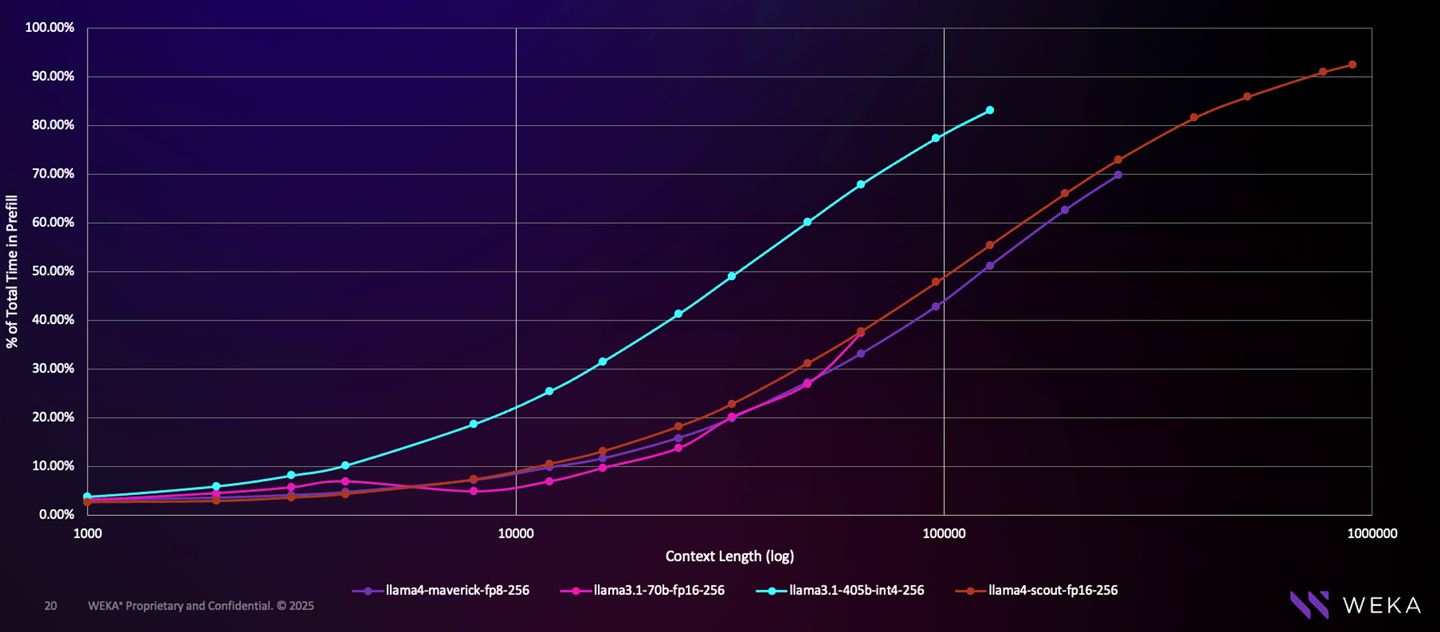
So the best case scenario is where input length is longer, and the generated tokens are less. The good news is that there are plenty of use cases that meet these characteristics. We recently wrote a blog about code generation and how this is almost a perfect use case.
Final Thoughts
We are currently in active beta testing of WEKA Augmented Memory Grid and to allow customers easier access to testing some of these benefits, we gave back to the open-source community by releasing an implementation of GPU Direct Storage (GDS) integration into some leading KV cache managers.
Popular Blogs From Callan Fox


Related Assets
-
The NAND Flash Shortage Survival Guide

The NAND Flash Shortage Survival Guide
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure