The Real State of AI: Hype vs. Reality

Key Value (KV) Cache technology is everywhere right now and for good reason. As LLMs grow larger and context windows expand, efficient handling of KV memory becomes mission-critical. But not all KV Cache solutions are created equal.
Recently, the vLLM open-source community and NVIDIA's Dynamo made major announcements around sophisticated KV Cache memory and storage hierarchies. These announcements are more than just headlines, they signal a structural shift in AI infrastructure expectations. Naturally, a wave of vendors have rushed to publish performance claims. But the truth is, in this new world, performance can’t just be good enough—it needs to be orders of magnitude faster. And that's where the real separation begins.
Today, two clear categories are emerging:
1. GPU Memory Hierarchy Solutions
This is where solutions like WEKA's Augmented Memory Grid provide value. Augmented Memory Grid isn’t just incrementally better, it delivers memory-class performance that redefines what’s possible, and drives meaningful benefits.
- Incredibly fast access to WEKA’s token warehouse™ (300 GBps)—across model types, context window sizes, and massive prompt lengths
- When using GDS, WEKA consistently outperforms traditional storage solutions, making them an indispensable pillar for AI-first companies
- Eliminate bottlenecks entirely, allowing LLMs to operate at their full potential and enabling next-gen agents to reason, adapt, and respond in real time
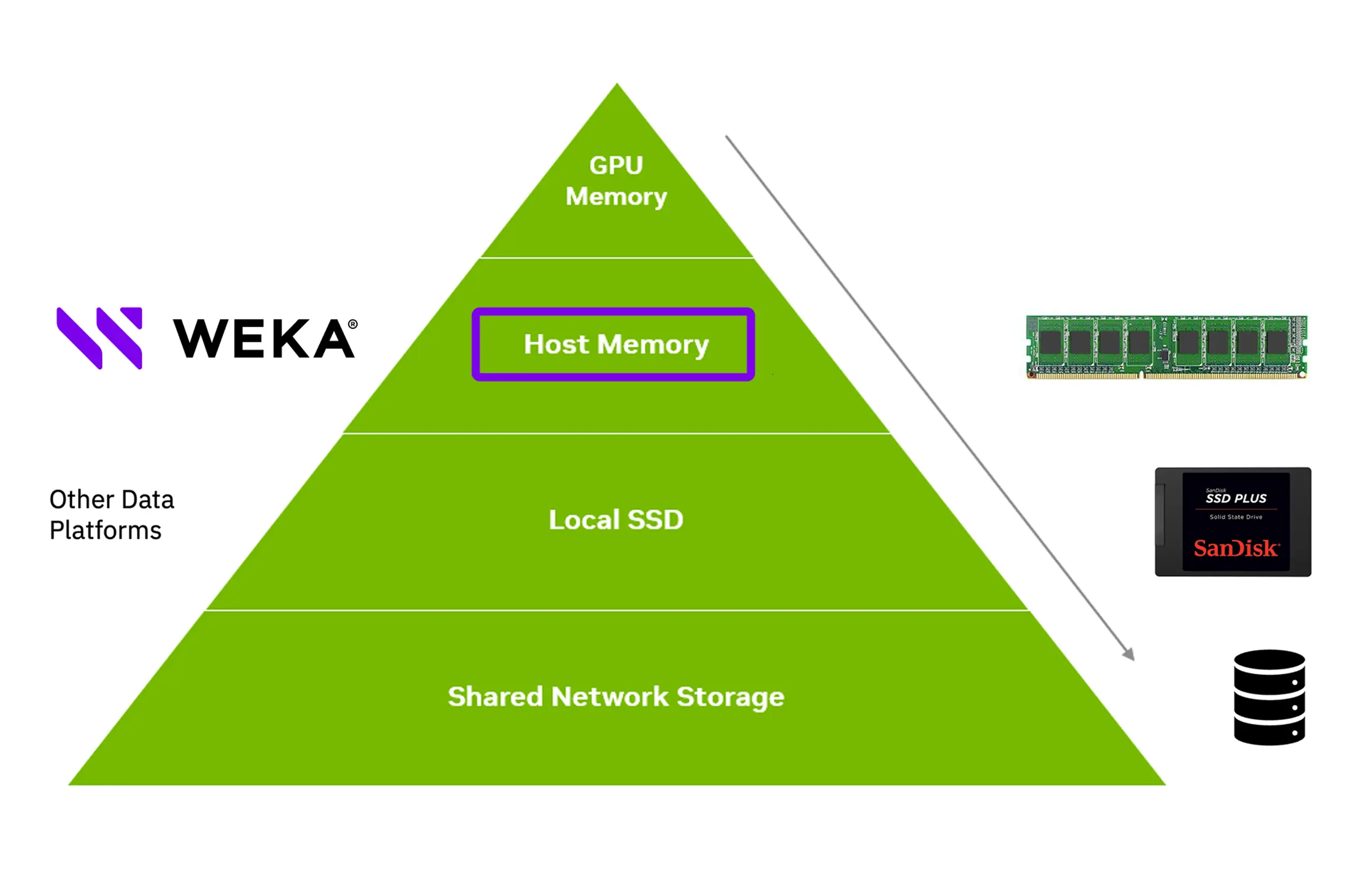
2. Commodity Storage Solutions
Then there are the others—solutions that lean heavily on traditional, commodity storage architectures.
- Inherently slower, relying on block storage, SSDs, and file systems not designed for real-time AI workloads
- Struggle to keep up with GPU performance at scale, forcing developers to trade model size or context length for performance
- Risk becoming the primary bottleneck, draining time, inflating costs, and strangling AI innovation at the edge
In a world where microseconds matter and context is king, if your KV Cache solution isn’t delivering memory-class performance, it's just another storage product, not an enabler of the AI frontier.
Inferencing economics are heating up with a cliff around memory and storage that greatly impacts end user experience and profitability. WEKA is leading the industry in KV Cache benchmarking, with a 41x improvement in time to first token TTFT—changing the tokenomics game at unprecedented scale. We draw the line sharply: augmenting the memory tiers of the KV Cache hierarchy isn't a luxury, it's a necessity for any organization serious about AI leadership. WEKA’s Augmented Memory Grid is architected from the ground up to:
- Slash rate limits and latency
- Empower smarter, more autonomous agents
- Unlock radically better user experiences
As the KV Cache landscape rapidly evolves, the winners won't be those who cling to yesterday's storage paradigms. They’ll be the ones who rethink the infrastructure stack entirely, with memory-class performance driving the future.
What's Next



Scale Production AI Faster with NeuralMesh
Your models aren't slow. Your data is. Fix AI bottlenecks with high-throughput infrastructure.