
Unleash AI Performance on
Oracle Cloud
Train AI Models in Hours,
not Months
Accelerate Time to First Token by 20x
Drive GPU Utilization from 30% to Over 90%

“We immediately saw our cloud storage costs drop by 90%
when we switched to WEKA.”
Build for the Demands of Modern AI
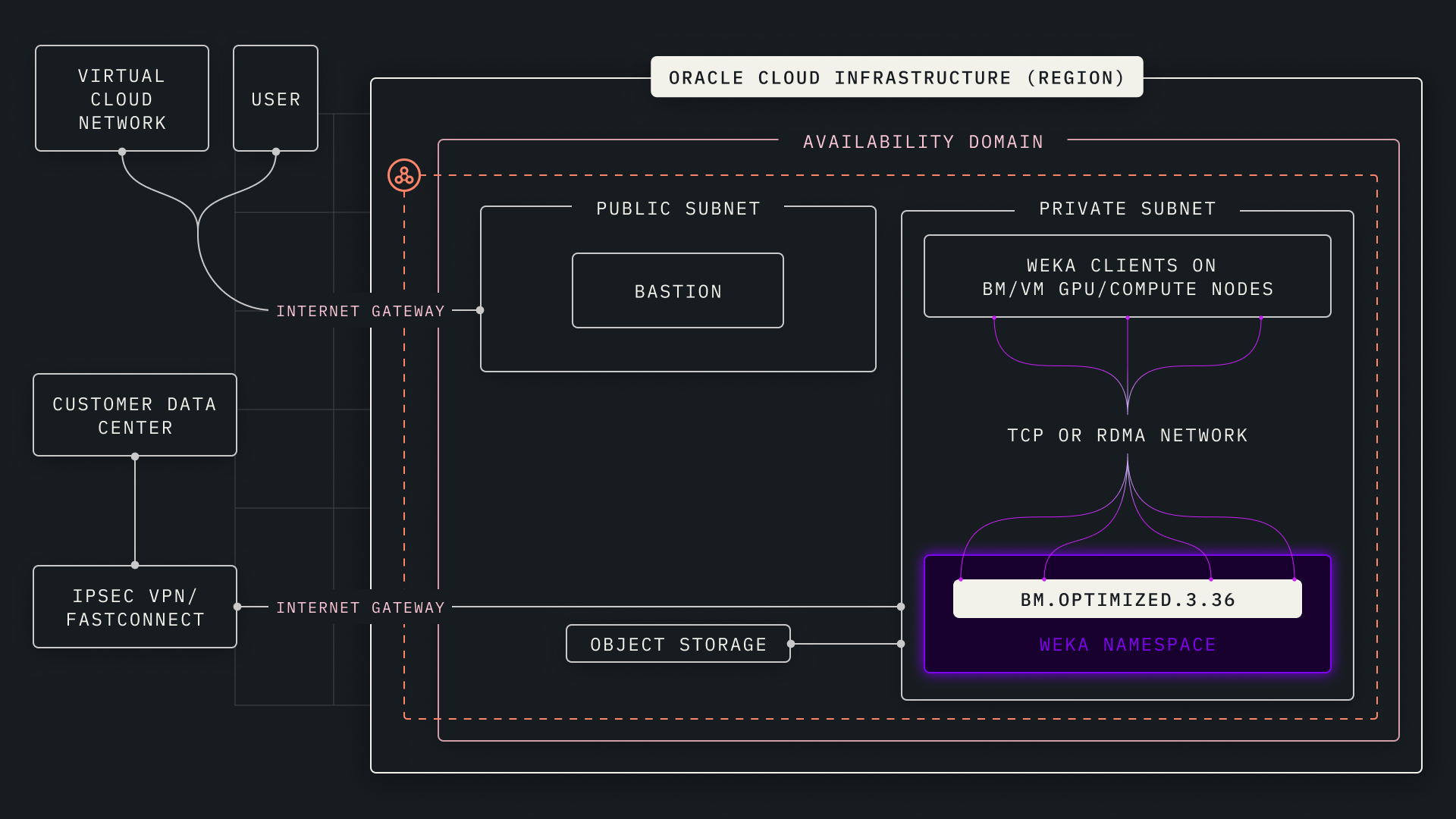
NeuralMesh on OCI
NeuralMesh™ runs on a cluster of optimized bare metal Compute shapes (BM.Optimized3.36) with local SSD to create a high-performance storage layer. NeuralMesh software can then extend the single namespace to an OCI Object Storage bucket for high-capacity storage at the lowest cost. You can easily add more OCI compute shapes or more OCI Object Storage to scale the WEKA namespace up to support Exabytes of capacity or millions of IOPs of storage performance and scale back down when capacity or performance is not needed. Data stored with your WEKA environment is accessible to applications in your environment through multiple protocols, including NFS, SMB, POSIX, NVIDIA GPUDirect, and S3.
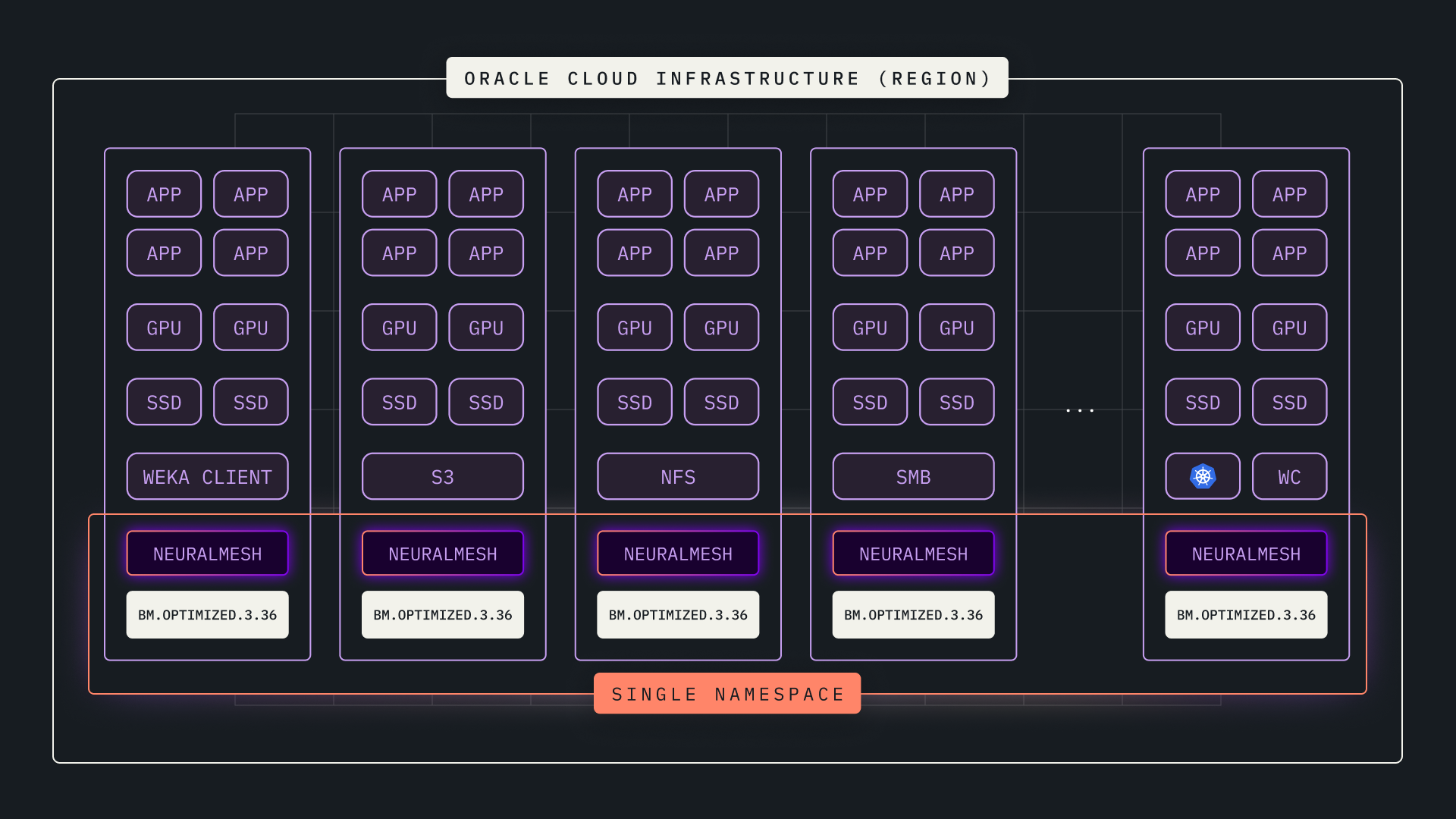
NeuralMesh Axon on OCI
NeuralMesh Axon™ fuses compute and storage into a high-performance fabric optimized for AI training and inferencing. The NeuralMesh Axon software runs directly on GPU instances in OCI, leveraging unused NVMe resources to create a high-performance storage system. By co-locating data with the GPUs and harnessing local NVMe, spare CPU cores, and OCI’s.
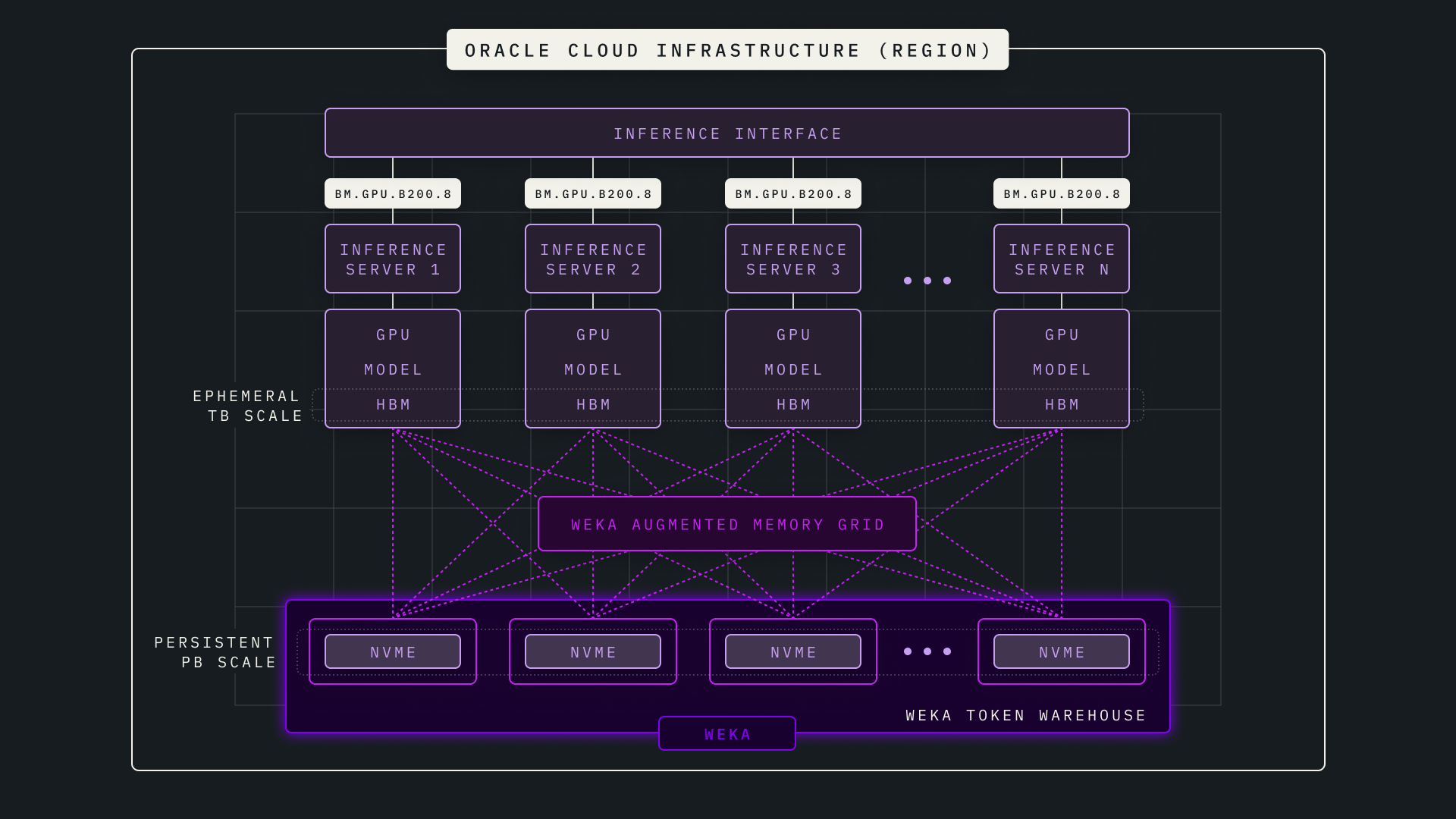
Augmented Memory Grid on OCI
Augmented Memory Grid™ extends GPU high-bandwidth memory into a persistent, petabyte scale token warehouse, eliminating the memory wall that limits long-context and agentic AI workloads. Built on NeuralMesh and deployed with NeuralMesh Axon, Augmented Memory Grid continuously streams key-value cache data between GPU memory and flash storage using RDMA and GPUDirect Storage, leveraging OCI’s bare metal GPU infrastructure to achieve memory-speed performance without adding physical DRAM. This breakthrough eliminates costly token recomputation when GPU memory fills, delivering 20x faster time to first token, 1000x more KV cache capacity, and up to 7.5M read IOPs—enabling AI cloud providers, model builders, and enterprises to maximize GPU utilization, reduce inference costs, and profitably serve long-context AI applications.
Resources

Breakthrough Performance, Scalability, Flexibility, and Economics for Oracle Cloud
Learn How AI Teams Scale Faster
with NeuralMesh
Go inside the NeuralMesh ecosystem and learn how leading AI teams are maximizing GPU utilization, eliminating latency, and cutting infrastructure costs.