Token Demand Went Exponential. Your Infrastructure Didn’t Get the Memo.

AI stopped being a bet. Now it has to pay up.
The reality is the AI industry is burning billions of dollars a day on inefficient infrastructure that is silently destroying ROI, all because of one thing: the memory wall. Today's AI models hit this wall as their demand for persistent context quickly exceeds the HBM available on the GPU.
“The memory wall is basically the exponential growth in token demand and memory requirements of agent swarms colliding with the fact that there is very limited, low-growth capacity for memory from the entire supply chain,” as WEKA Chief AI Officer Val Bercovici put it during his keynote at the Xcelerated Compute Show in New York in March 2026.
The numbers are stark. On the lower end, Venture capitalist Tomasz Tunguz of Theory Ventures put a top-quartile software engineer salary at $375,000 and suggested adding $100,000 in tokens, dedicating roughly $1 in $5 of an engineer’s overall compensation to compute. NVIDIA President and CEO Jensen Huang raised the stakes, suggesting a budget of approximately $250,000 in tokens per developer, per year. Spread these figures across a team of potentially hundreds of developers, and the costs are staggering.
And as the industry pivots from training to inference, today’s primary AI challenge doesn’t come down to costs alone. Even if you have the budget to sustain the explosion of tokens, the underlying AI infrastructure simply can’t handle token demand. And the culprit isn’t the models. It’s the infrastructure supporting them, with scarce available memory as the key roadblock.
Sold out and falling behind: How the global memory supply chain became AI’s biggest liability
Global fabrication capacity for the memory types that power AI inference — particularly high-bandwidth memory (HBM) and CPU DRAM, and to a lesser extent NVMe — is effectively spoken for. TSMC, Samsung, SK Hynix, and Micron simply cannot produce enough memory to keep pace with surging demand, and shortages are expected to persist into 2027. Compounding the supply problem, power capacity around the world is becoming increasingly constrained. Data center electricity demand grew 17% in 2025 alone, outpacing global electricity supply growth by more than 5:1.
At the same time, token demand is surging exponentially. What was once a chat session two years ago (roughly 8 KB of input tokens) has become an agent swarm iterating through 1,000 turns or more. That’s 1,000x the token volume of a single chat session, and it is what production AI looks like today.
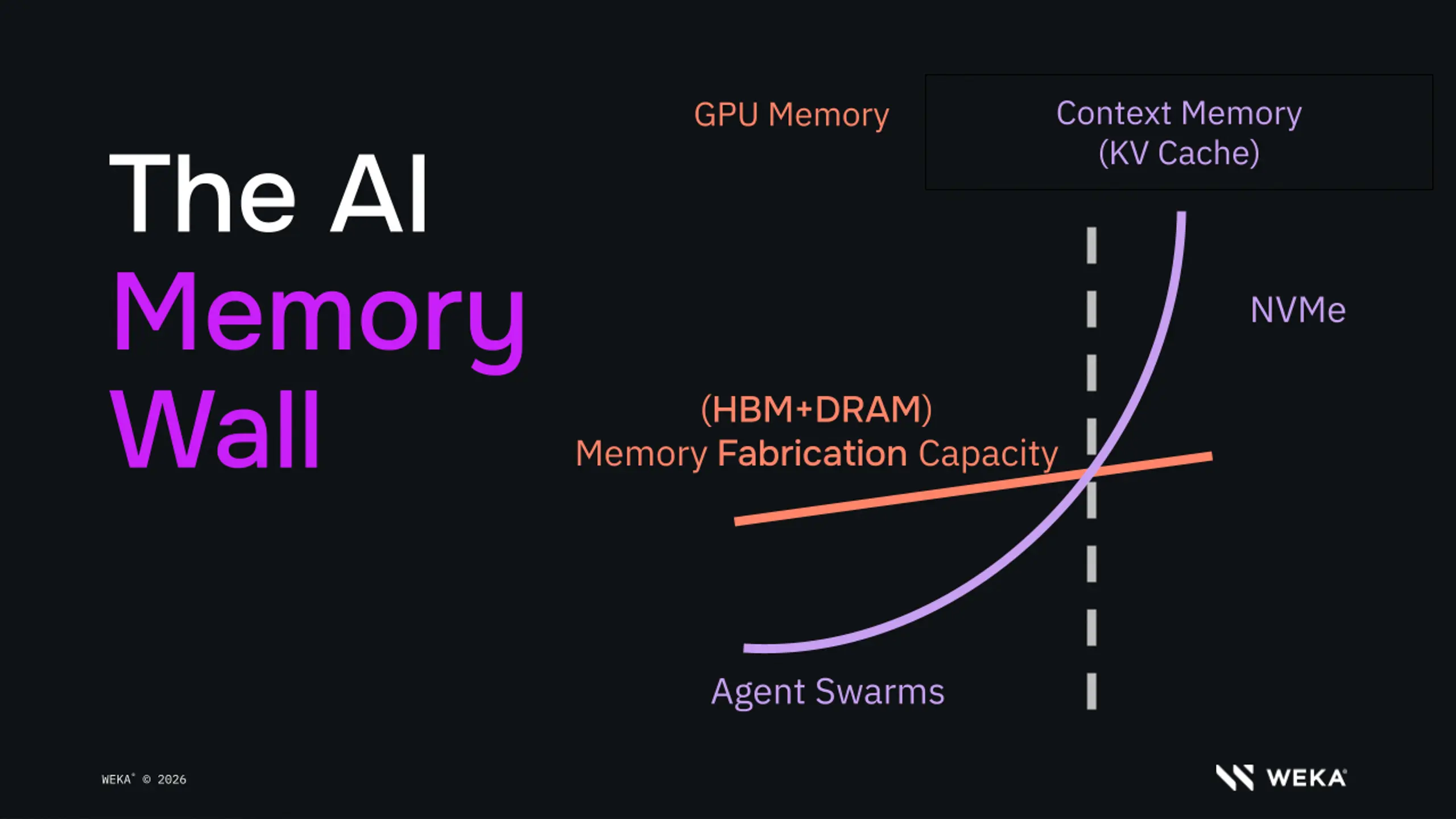
These are two trends diverging when they should be converging.
The model mix that actually runs the world’s AI workloads
Open Router, one of the industry’s best proxies for real-world token consumption, tells a story that surprises most people. In under one year, global token volume exploded from roughly 2 trillion tokens per week to 20 trillion per day, and the models at the top of the chart are not necessarily the ones most enterprises are building around. At the time of Val’s keynote, Step One and Minimax — both Chinese AI startups — led the rankings, with DeepSeek, Claude Sonnet and Opus further down. During any given week, the list fluctuates.
The practical takeaway for enterprise AI teams: The future is not a single frontier model. The right strategy is model routing, where you use the best model for each subtask within a hierarchy. This approach is how you get token costs under control, and it’s now getting built into leading open inference frameworks.
Token warehousing: The infrastructure strategy AI teams need to understand now
The core inefficiency in today’s inference stack is redundant prefill. Every time a model processes a prompt, it runs a compute-intensive prefill operation: A 100,000-token prompt, for example, consumes 50 GB of HBM in prefill alone. Today, most systems repeat this operation thousands or millions of times for the same agent swarm, because they lack the memory architecture to store and reuse the result.
Val framed the solution this way: “You produce tokens at the factory, you prefill once, store that in a token warehouse at memory speeds, then decode effectively forever.” Think of it the way Amazon orchestrates logistics for the products it sells. Amazon does not ship every order directly from a factory. Instead, it warehouses inventory close to the consumer and fulfills orders from there in a hub-and-spoke model. Token warehousing applies the same principle: Prefill once, which creates a “warehouse” that stores the key-value cache (KV cache) locally at memory speeds, and decode from this cache repeatedly. The unit economics flip entirely, making inference cost-efficient to scale.
Jensen made the infrastructure implication explicit at CES 2026: Enterprises need to fundamentally re-architect their storage. Enterprise storage systems, however mature or high-performing, are not memory. NVMe is what the inference stack actually requires, and context memory storage is going to become the largest new storage market in the world.
How to close the gap between token demand and infrastructure capacity
The bottom line: You can squeeze out 4-6.5x more tokens from the same infrastructure. WEKA’s Augmented Memory Grid demonstrates what is possible when NVMe is treated as a memory tier rather than a storage tier. In publicly measured benchmarks with Oracle, performance scaled past the concurrency wall that defeats most deployments with no additional hardware, energy, CapEx or OpEx.
The companies that will win the next phase of AI are not the ones with the most GPUs. They are the ones that warehouse tokens intelligently, route models efficiently, and treat memory architecture as a strategic asset instead of an afterthought.
What's Next



Scale Production AI Faster with NeuralMesh
Your models aren't slow. Your data is. Fix AI bottlenecks with high-throughput infrastructure.