
Hey Meta, Real Talk:It’s Time to Move Beyond Lustre
See why the world’s most advanced AI companies are making the switch.

The Hidden Bottleneck Slowing Down AI at Meta?It’s Lustre.
Meta is pushing AI further than ever, but Lustre’s latency and scaling limits slow progress.
Faster data keeps GPUs active—maximizing output, efficiency, and impact.
Eliminate metadata drag to accelerate iteration speed and model quality.
Adaptive systems scale with demand—reducing rebuilds and protecting spend.
Performance Proven Head-to-Head
At Meta’s scale, these deltas compound into millions saved and months accelerated.
| WEKA on i3en.6xl | FSx Lustre 250 MB/sec | |
|---|---|---|
| Cost | $194K | $215K |
| Read Bandwidth | 227 GB/s | 227 GB/s |
| Read IOPs | 19M | 1M |
| Write IOPs | 4.7M | 545K |
| List 1M files | ~6s | ~20s |
| List 10M files | <6 min | >28 min |
Born in the Cloud.Purpose-Built for Agentic AI.
Meta needs storage that performs anywhere. NeuralMesh™ delivers identical, high-performance storage across on-prem, multi-cloud, and hybrid — with zero performance loss.
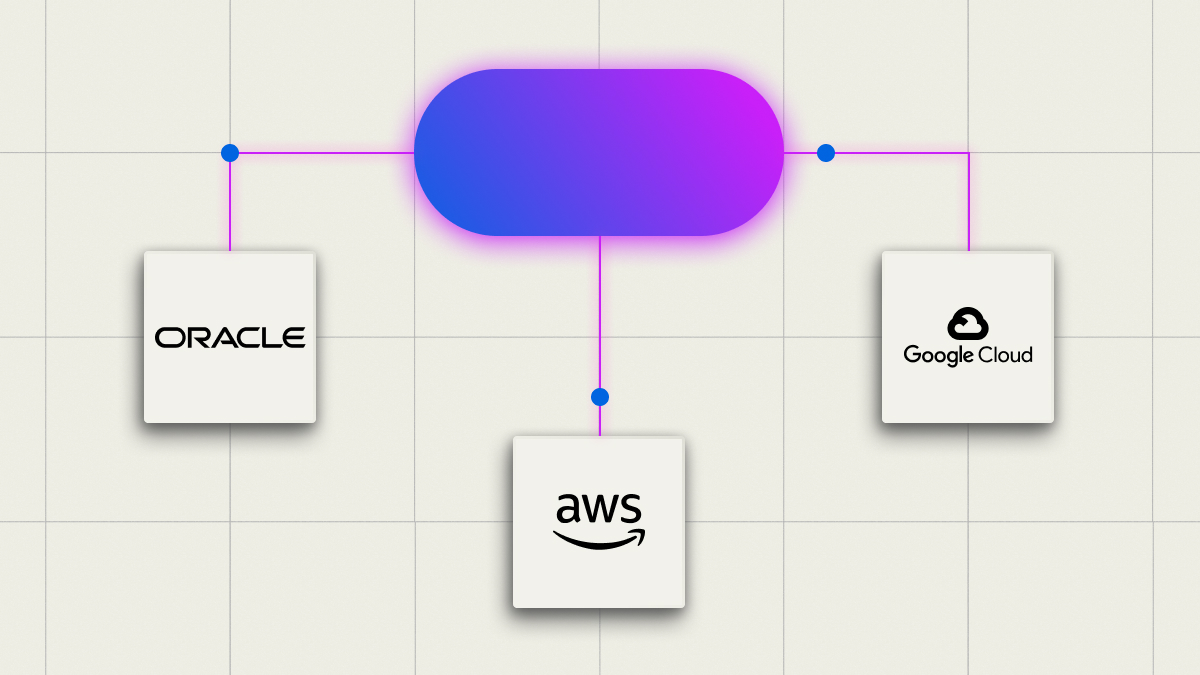
Multi-Cloud Flexibility
Run seamlessly on AWS, GCP, OCI, or AI-native clouds.
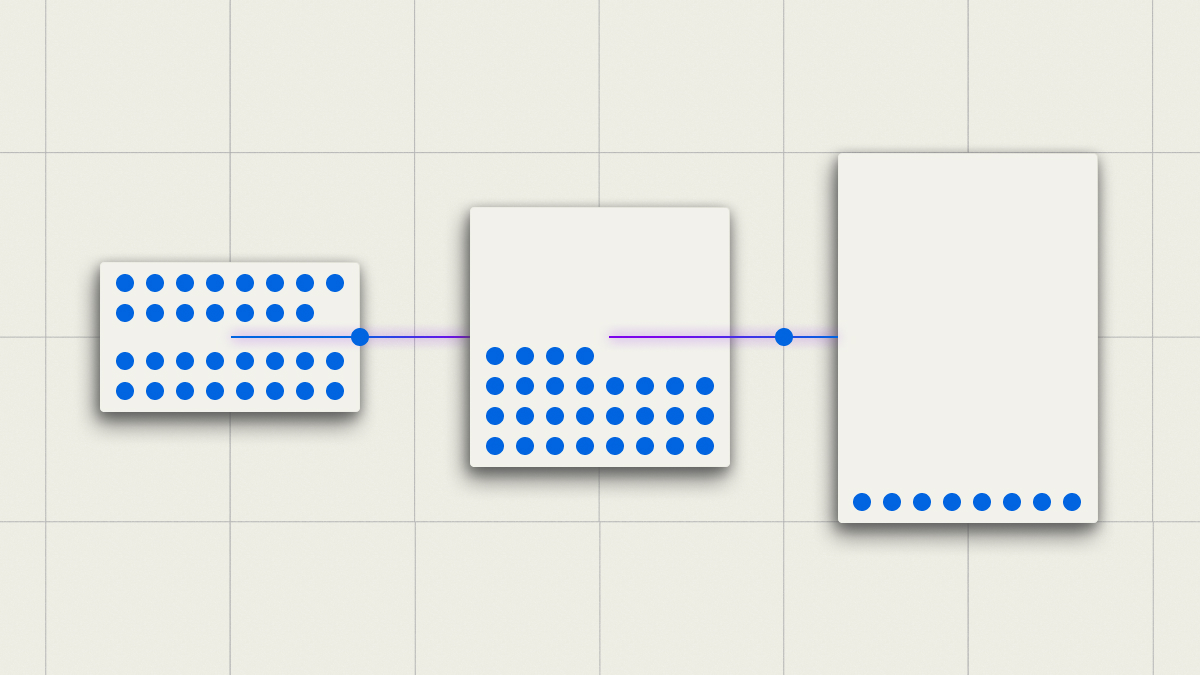
Effortless Tiering
Move data across hot and cold storage tiers without breaking performance.
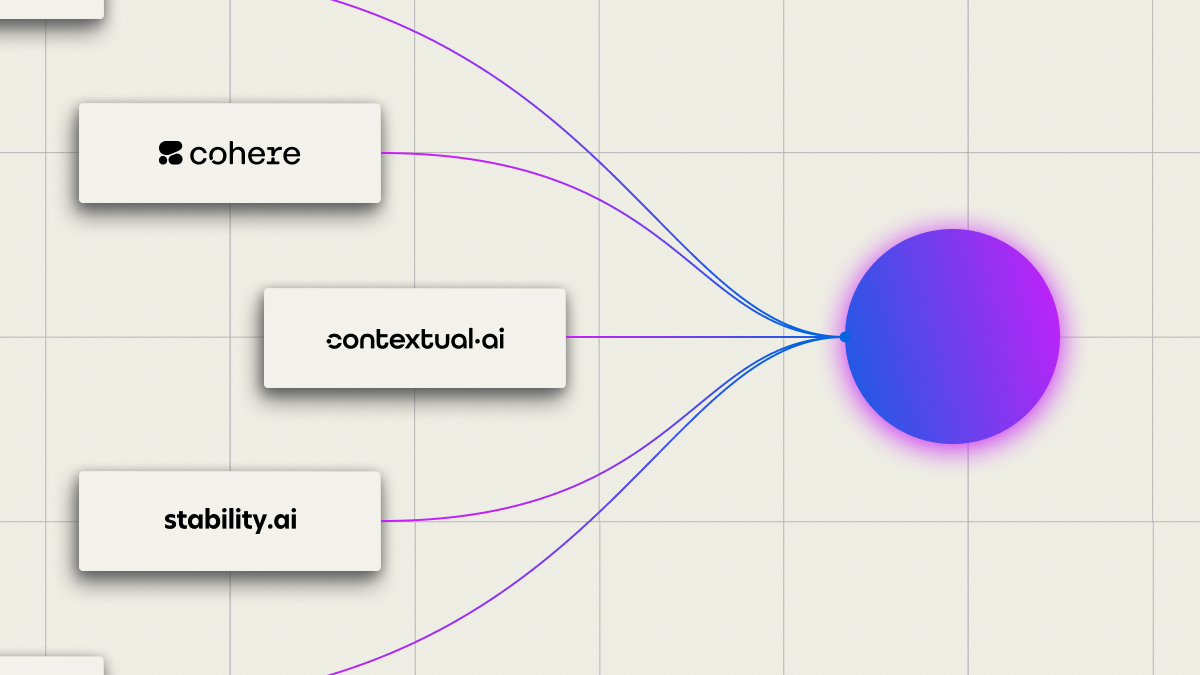
Proven in the Cloud
Stability AI (AWS), Contextual AI (GCP), and more trust WEKA.
Snap Environments Together
Cloud-to-cloud, on-prem-to-cloud, or back again — no rewrites, no re-benchmarking.
See the Proof

Eliminate AI Bottlenecks. Put Your GPUs on Rails.
Lustre was built for yesterday’s workloads. NeuralMesh™ is built for agentic AI — at Meta scale.
Meta is defining the future of AI. To keep GPUs fully fed, pipelines fluid, and costs in check, storage can’t be the bottleneck.
With NeuralMesh, teams can:
- Cut costs by eliminating idle GPU time
- Accelerate workloads with unmatched metadata + IOPS performance
- Scale without fragility using a distributed, elastic architecture
Future-proof AI infrastructure for exabyte-scale demands

Why Stability AI Left Lustre for NeuralMesh Axon
Challenge: Stability AI pushed the limits of AWS with Lustre. GPUs sat idle, storage costs skyrocketed, and over-provisioning led to inefficiency.
Solution: Deploying NeuralMesh™ Axon® on AWS, Stability AI scaled to ~400 Amazon EC2 P4d instances with 2.2PB NVMe flash and 5PB object storage to power Stable Diffusion training.
Results:
- 🚀 93% GPU utilization efficiency — no more idle compute
- 💰 95% lower storage cost per TB vs. Lustre
- ⚡ 35% faster training cycles, cutting 3 weeks from a 60-day epoch
At Meta Scale, Every Bottleneck Compounds
Over the course of a year, Lustre’s inefficiencies result in millions of wasted GPU hours and delayed
time-to-value. NeuralMesh eliminates this drag.
Your GPUs Deserve NeuralMesh
DISCLAIMER: Intended for internal Meta audience only, not for general distribution. Product comparisons are based on publicly available information as of December 2025. Actual performance, pricing and capabilities may vary by configuration, use case and deployment. Provided for informational purposes and not intended as an offer, warranty or commitment. Product and company names are trademarks of their respective owners.