Ready to Get More From Your Azure Workloads?

Last June, we launched a new set of capabilities for our cloud customers with in NeuralMesh. In the release, we added multicloud support and several key capabilities that made running workloads in the cloud easier and faster; in January, we made WEKA available in the Azure Marketplace.
Today, we are excited to release the next version of NeuralMesh which offers new enhancements for organizations that want to run their “impossible” workloads, like generative AI, genomics sequencing, or other performance-intensive applications, in the Azure cloud. Here’s a deep dive into the NeuralMesh architecture for Azure customers.
Get Up to 10x Faster Performance in Azure
We just released our first round of performance analysis comparing NeuralMeh in Azure versus Azure NetApp Files (ANF). Compared to the published ANF benchmarks, NeuralMesh performs at least 7x faster on IOPs and 10x faster on MBps while saving customers roughly 70% versus the first-party cloud solutions. You can read all about these results here.
Azure Artists Anywhere Integration
NeuralMesh now integrates with the Azure Artist Anywhere (AAA) framework, a modular and customizable infrastructure-as-code deployment framework for the Azure rendering solution architecture. AAA enables remote artists with global render farm scale using Azure HPC Virtual Machines and Azure GPU Virtual Machines. With this integration, creative studios can now run VFX rendering, color correction, post-production, and similar workflows requiring low frame loss and zero-frame lag in the cloud.
An Architectural Overview of NeuralMesh on Azure
Customers frequently ask how NeuralMesh fits into their existing Azure environment. So let’s get into more detail and explore its key capabilities on Azure, what to expect, and how to get started. We’ll start with an overview and then dive into several key capabilities within NeuralMesh that enable you to run high-performance workloads in Azure and scale to meet the changing demands of those workloads efficiently and affordably.
In Azure: You can deploy NeuralMesh on a cluster of Microsoft Azure LSv3 VMs with local SSD to create a high-performance storage layer. NeuralMesh also extends the single namespace to an Azure Blob Storage bucket for capacity storage at the lowest cost. You can automate your NeuralMesh deployment through HashiCorp Terraform templates for easy installation. Data stored in your NeuralMesh environment is accessible to applications in your environment through multiple protocols, including POSIX, NFS, SMB, and S3-compliant applications.
On-premises for hybrid deployments: In your data center, NeuralMesh runs on commodity server hardware, utilizing local flash storage in the server for the performance tier. You can then attach any supported object storage array for massive capacity.
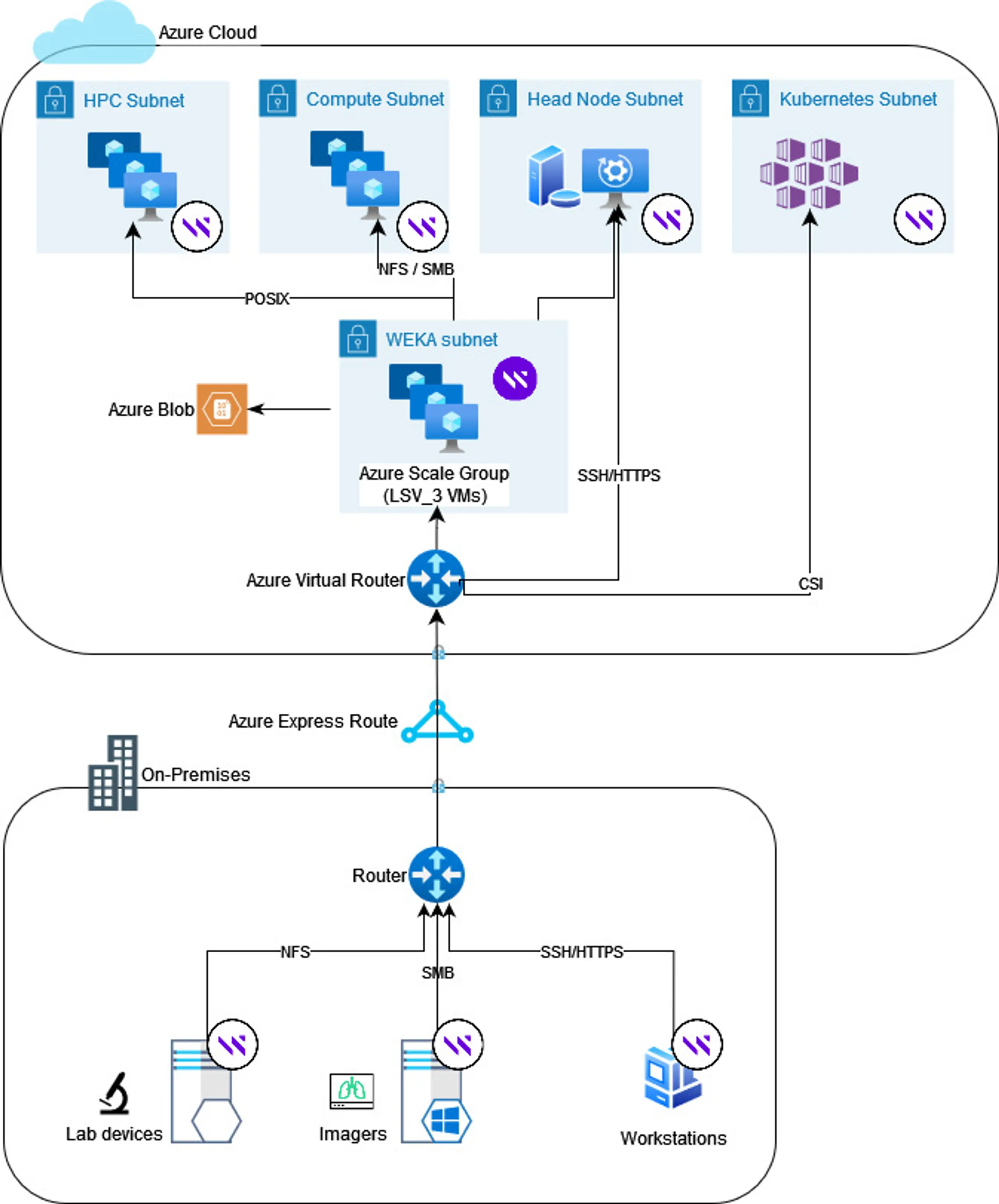
Figure 1: NeuralMesh on AWS Architecture Overview
Key Capabilities of NeuralMesh on Azure
There are several capabilities that NeuralMesh provides for your Azure workloads that are important to understand as you consider which ones will be a good fit.
Single namespace and integrated storage tiering
As mentioned above, NeuralMesh runs in Azure on a cluster of LSV-3 VMs. Each Lsv3 machine comes equipped with 1.92 TB NVMe SSD storage. So once deployed, the WEKA cluster has a pool of high-performance flash storage available to drive high I/IO, high bandwidth, and low latency for your applications. Within the same namespace, you can define a high-capacity tier that uses Azure Blob storage. When you set up your NeuralMesh environment for the first time, you’ll define the total capacity in your namespace, the % of data for flash. As a best practice, you should always have an object storage tier equal to the total capacity in your NeuralMesh environment to ensure data persistence.
Once deployed, you have a single NeuralMesh environment with high-performance NVMe flash storage attached to the Lsv3 VMs and low-cost Azure Blob storage. NeuralMesh automatically handles the tiering between the NVMe and object store, so there is no tiering policy for you to create and manage and no settings to optimize - NeuralMesh handles everything for you. NeuralMesh’s zero-tuning architecture automatically optimizes for high I/O, high throughput or low latency so you can meet the performance profile of any workload in the cloud. Finally, you can connect to your applications through any supported storage protocol, including POSIX, NFS, SMB, S3, and CSI.
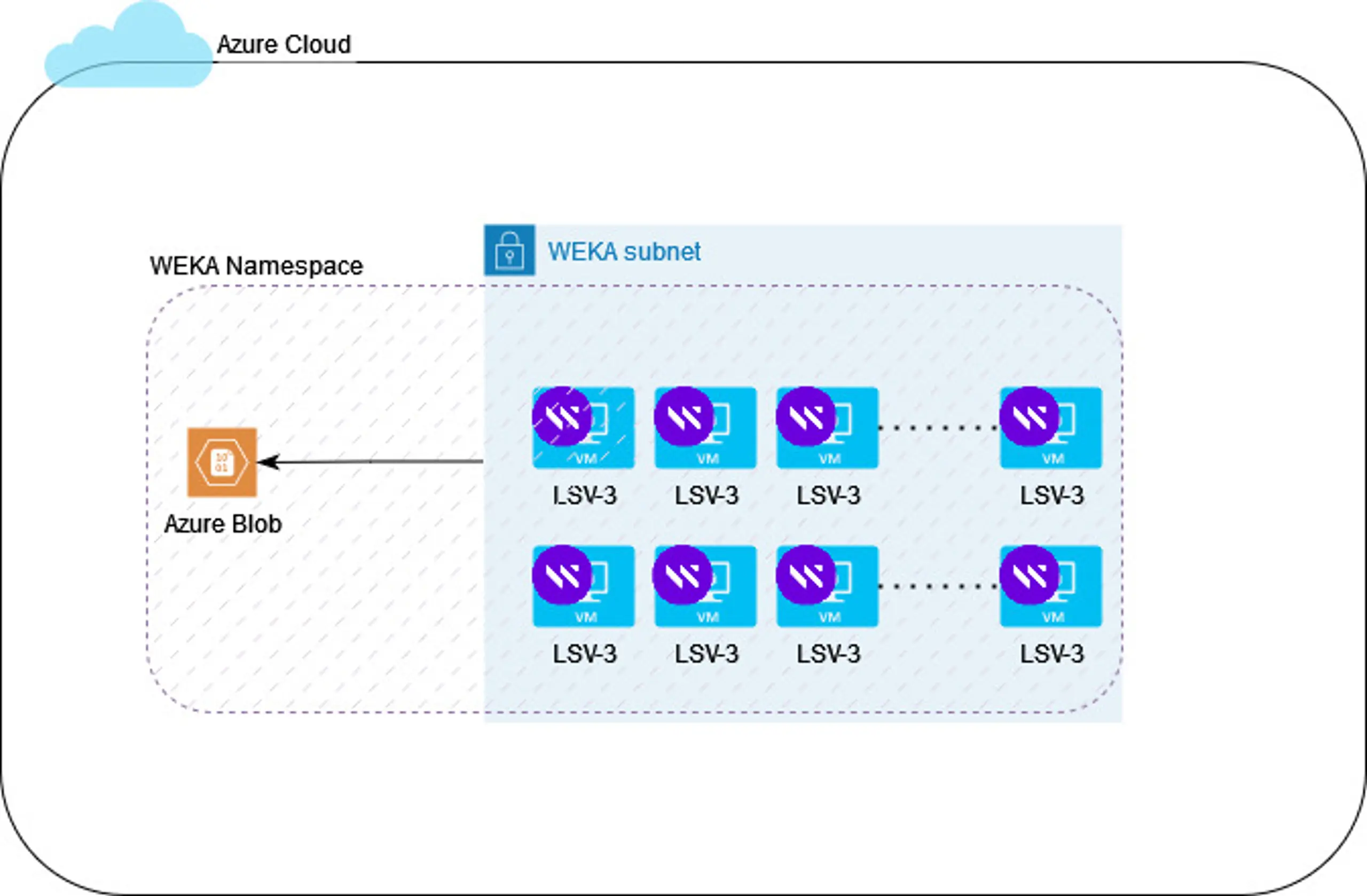
Figure 2: NeuralMesh on Azure Single Namespace
Autoscaling (VM Scale sets)
Autoscaling with NeuralMesh is unique in two ways:
- You can scale your NeuralMesh environment up and down, which helps to ensure you can respond to peak demand without overprovisioning storage. During initial deployment, WEKA Terraform scripts automatically place Azure Virtual Machines within an Azure VM Scale Set to enable autoscaling. By leveraging VM Scale Sets, you can automatically scale your WEKA cluster up or down to meet your performance requirements.
- With NeuralMesh autoscaling, it is possible to scale the capacity or the performance tier independently. So you never have to provision storage capacity you don’t need to meet a performance profile.
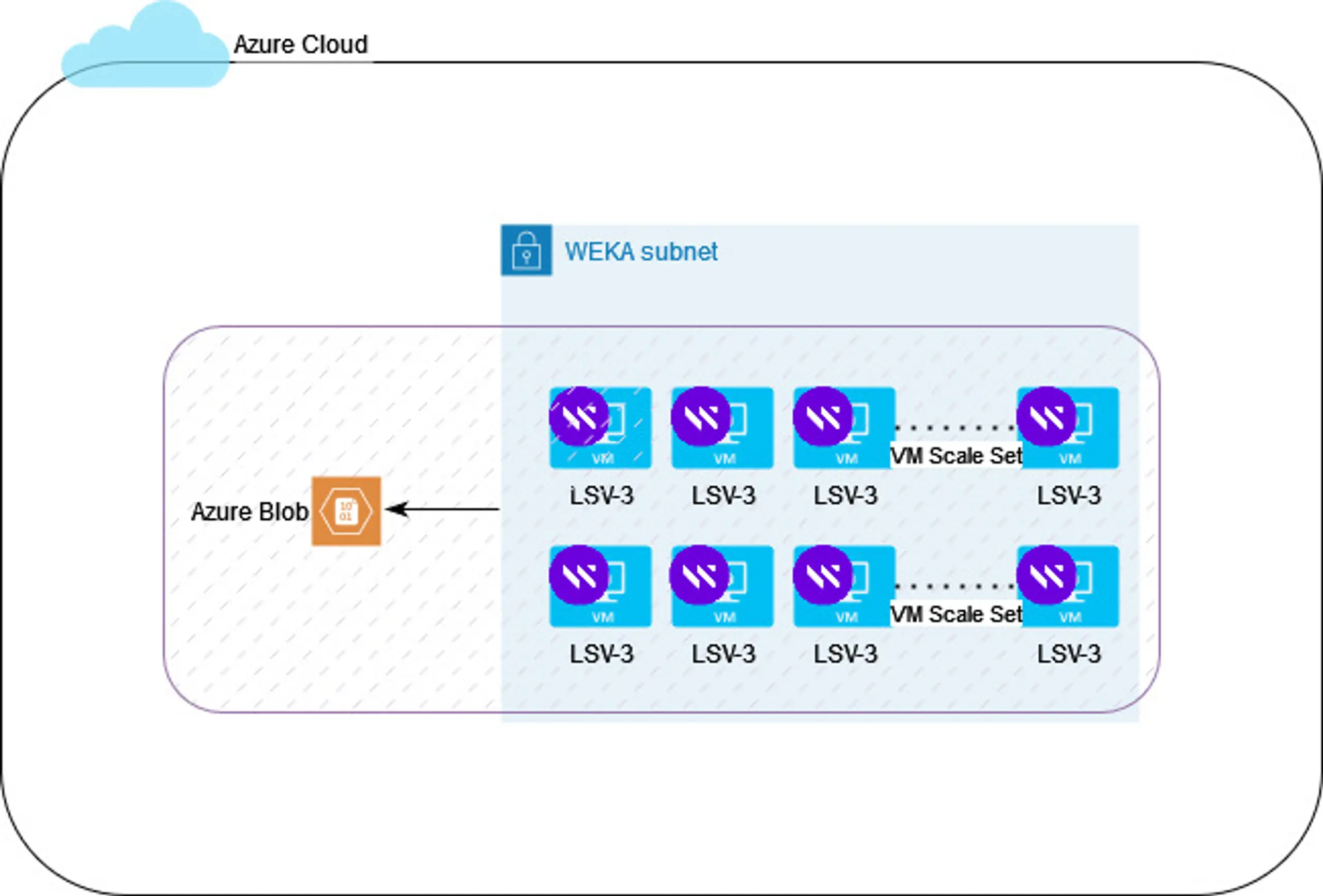
Figure 3: NeuralMesh on Azure Autoscaling
Snap-to-Object
You can use NeuralMesh to create a snapshot of the entire file system (both the data and metadata) and copy it directly to any object store. This Snap-to-Object feature introduces the ability to easily port your entire storage environment from on-premises to Azure. WEKA customers have found this feature extremely useful in data migration and cloud-bursting scenarios.
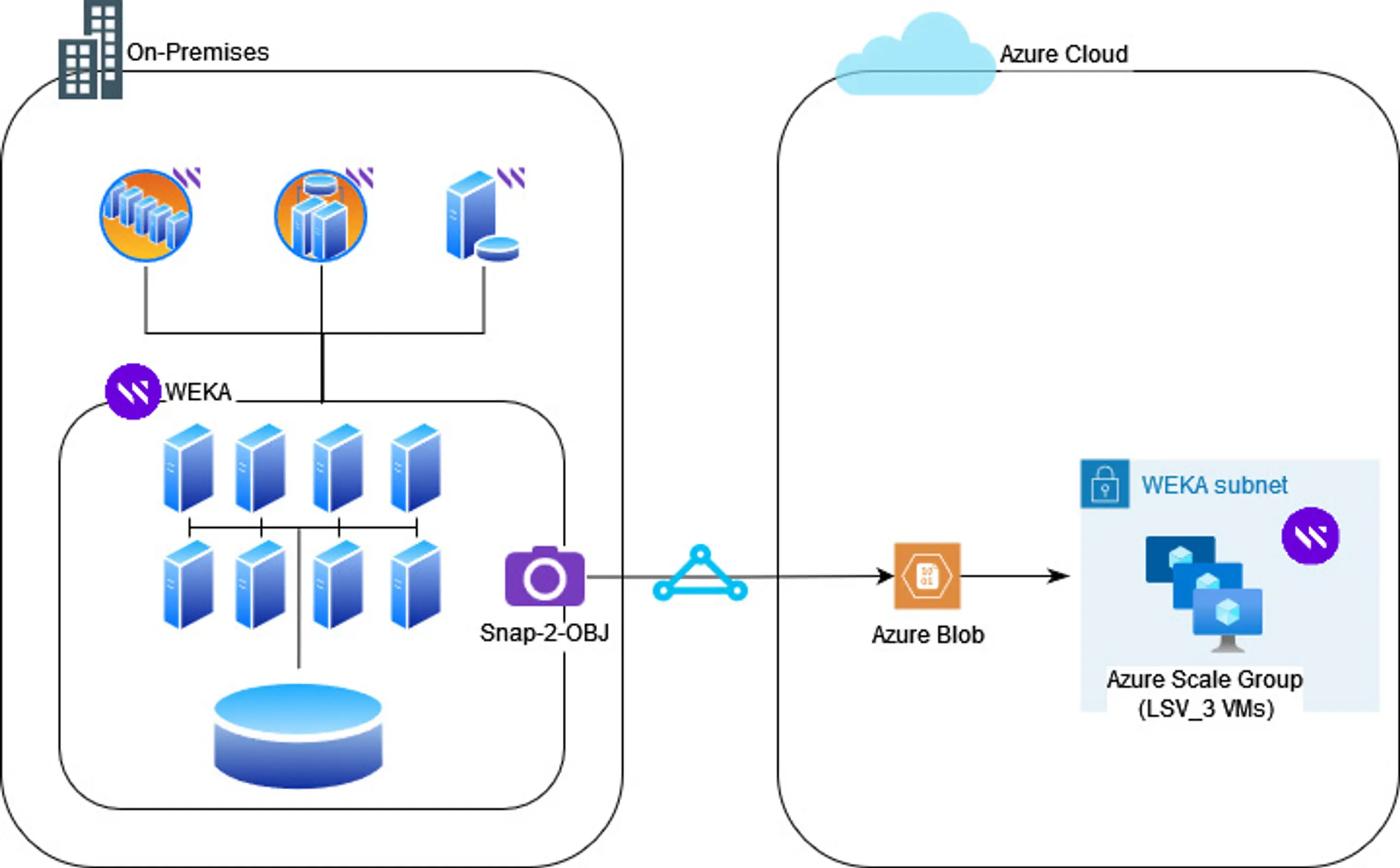
Figure 4: WEKA on Azure Snap-to-Object
Ready to get started with WEKA on Azure?
Deploying NeuralMesh in your Azure environment has never been easier. You can find the latest offerings listed in the Azure Marketplace, and you’ll also find the latest Terraform scripts in the GitHub repo which provides several example templates to help get you started in WEKA for your environment.
What's Next



Scale Production AI Faster with NeuralMesh
Your models aren't slow. Your data is. Fix AI bottlenecks with high-throughput infrastructure.