AI Storage for Workloads That Can’t Wait
NeuralMesh™ redefines what storage means in the age of AI – a high-performance, software-defined system that powers HPC and AI workloads at any scale.
The world’s leading AI innovators and research teams build with WEKA











Build AI, Not Infrastructure
Traditional data infrastructure is breaking under the scale and complexity that AI and modern compute-intensive workloads require. NeuralMesh is based on service-oriented design that interconnects data, compute, and AI to accelerate AI at scale.
Core Component
The Core component creates a resilient storage environment that improves at petabyte scale and beyond. It intelligently distributes data and metadata across the system, automatically balancing I/O to prevent hotspots and idle resources. Core ensures high availability and durability, even at exabyte scale and beyond.
Accelerate Component
The Accelerate component ensures NeuralMesh delivers microsecond latency at exabyte scale for AI and compute intensive workloads. It creates direct paths between data and applications and distributes metadata across the entire system. It combines memory and flash storage in a single ultra-low latency pool for data to deliver consistently high real-world performance regardless of workload complexity or system scale.
Deploy Component
The Deploy component provides the flexibility to deploy NeuralMesh however users choose, enabling maximum deployment flexibility—from bare metal to multi-cloud and anything in between.
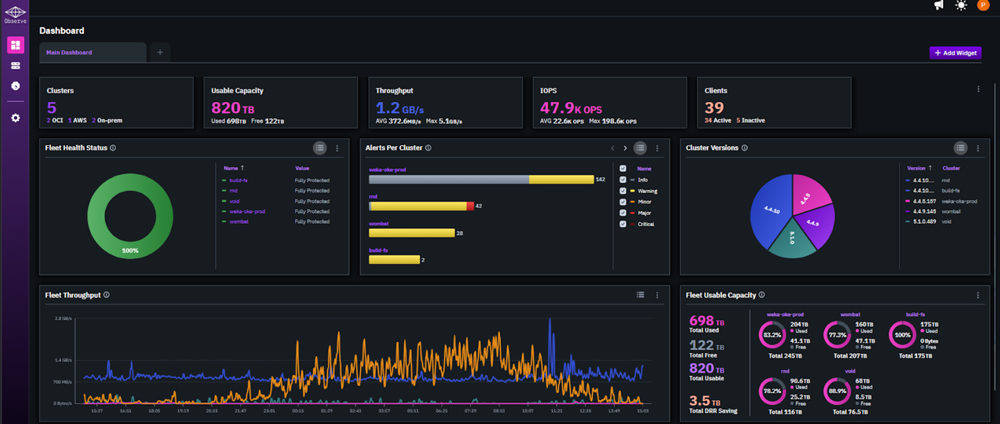
Observe Component
The Observe component delivers comprehensive visibility across your WEKA environment with multi-cluster dashboards, performance intelligence, and smart alerting.
Enterprise Services
The Enterprise Services component in NeuralMesh provides security, access management, and data protection that customers expect. Industry-leading zero tuning and zero copy capabilities ensure every workload get the exact performance it requires with no tuning and no data copies.
Why Containerized Microservices?
Containerized microservices enable a service-oriented design that delivers transformative advantages for AI infrastructure.
True Multi-Tenancy
Complete isolation between tenants through dedicated container sets. No noisy neighbors, with security boundaries at the container level.
Horizontal Scaling
Independent service scaling based on workload demands. Rebalance resources as clusters grow without disrupting operations.
Operational Flexibility
Maintain quality of service, deploy updates, perform maintenance, and troubleshoot issues on individual services with maximum uptime.
See NeuralMesh in Action
Get access to an exclusive early preview.