Use AI Accelerators to Get More From Your AI, ML and Deep Learning Deployments

The AI/ML Data Conundrum
Machine learning and deep learning have emerged as two of the most important computational workloads of our generation; their adoption is widespread and growing. However, they are profoundly intensive workloads to run. Testing a single new hypothesis or training a new model can take weeks or months and cost hundreds of thousands of dollars to run. This has created a significant drag on the pace of innovation, and many potentially important ideas have gone unexplored simply because they take too long and are too costly to test.
To ensure it is fully and optimally utilized, AI compute must also be constantly fed with data to keep it busy, which many organizations struggle with due to the shortcomings of their legacy data infrastructure, which is typically ill-suited to the performance demands of these next-generation workloads.
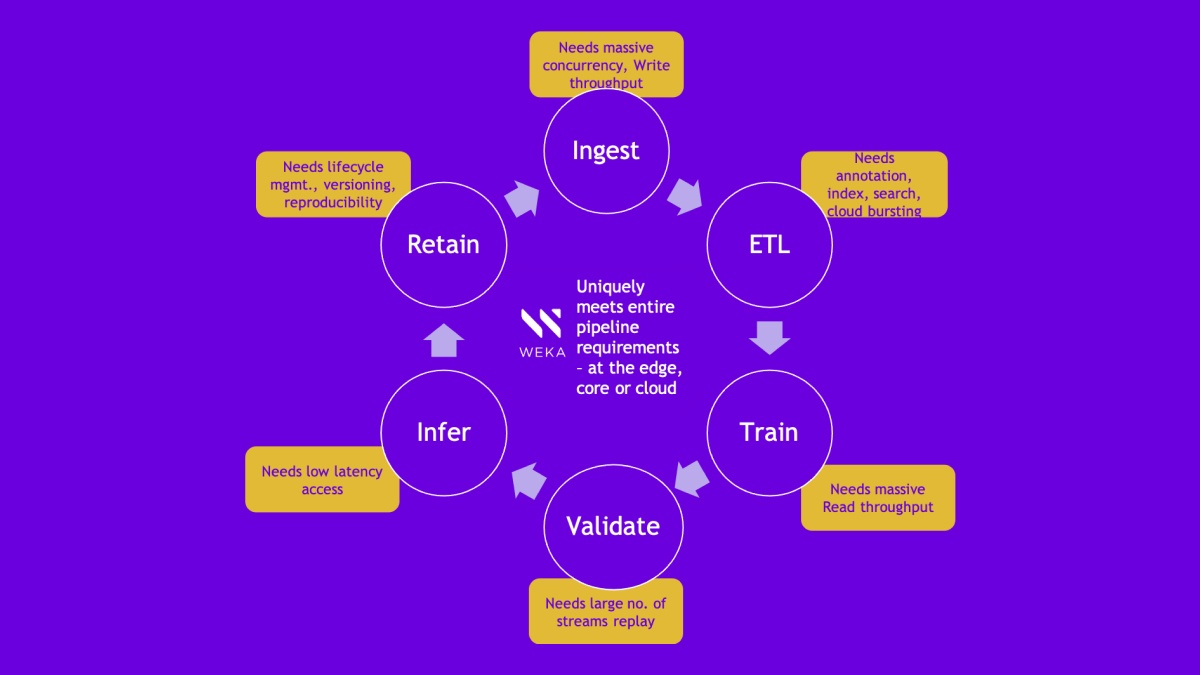
Data and AI teams need simple yet powerful data infrastructure to take their ideas from experimentation to production. Storage is a crucial component at the heart of every infrastructure deployment. Choosing and configuring the right storage is critical to provide the highly performant, reliable and efficient foundation required to support machine and deep learning projects at scale.
WEKA Data Platform for AI and AI Accelerators
WEKA developed the Data Platform for AI to solve the complex data challenges research and data science teams face today and provide truly epic performance for AI, ML and deep learning workloads at scale. Today, many of the world’s largest AI projects run on WEKA – eight of the Fortune 50 use the WEKA Data Platform for AI to fuel innovation and discovery.
WEKA, together with Graphcore and Cerebras – two of our closest AI accelerator partners, are excited to publish a joint reference architecture that can deliver significant benefits to customers looking to optimize their AI/ML data pipelines.
Used with AI accelerators from these two partners, the WEKA Data Platform provides:
- Exceptionally high performance and improved epoch times with shared storage, with choice of POSIX, S3, NFS, Kubernetes CSI protocols
- Converged mode where ETL processing can be run on same load/storage servers.
- Eliminates additional tiers, extend capacity by attaching S3 bucket to same namespace
- Choice of broad storage server partners
- Best economics
- Better Storage efficiency than RAID 0 / RAID 6 striping; Configurable data protection all the way to 16+4
- NVMe Flash performance tier with S3/HDD bucket as capacity Tier
- Ease of use at scale
- No need to manually shard data with local NVMe storage
- Better data management with snap2object, scale to Exabytes with billion files in a directory and cloud bursting as needed
As part of developing these reference architectures, we ran several AI-specific benchmarks that highlighted WEKA’s performance. Below, we will examine some of those benchmarks and the computed results in their respective documents.
WEKA Data Platform for AI with Graphcore
- Some of the AI/ML-centric benchmarks run with Graphcore are explained below. The entire reference architecture can be found here.
SPECStorage 2020 AI Image Benchmark
- The SPECstorage Solution 2020 release contains a new workload. AI_IMAGE (AI image processing). This workload is representative of AI Tensorflow image processing environments and is expected to be popular as this market continues to expand. The traces used for the basis were collected from Nvidia DGX based systems running COCO, Resnet50, and CityScape processing.
- This benchmark simulates an AI image application and runs an increasing number of concurrent workloads (jobs) against the WEKA cluster.
- Storage Ops/sec, latency, and throughput is captured. One can see that throughput and Storage Ops/secs scale linearly as concurrent AI workloads (jobs) are added, while latency remains close to constant.
BERT-large – NLP transformer training tests
- Bidirectional Encoder Representations from Transformers (BERT) is a transformer-based machine learning model for Natural Language Processing (NLP) pre-training developed by Google. A 2020 literature survey concluded that “in a little over a year, BERT has become a ubiquitous baseline in NLP experiments”, counting over 150 research publications analyzing and improving the model.
- BERT has two models: (1) the BERTBASE: 12 encoders with 12 bidirectional self-attention heads, and (2) the BERTLARGE: 24 encoders with 16 bidirectional self-attention heads. Both models are pre-trained from unlabeled data extracted from the English Wikipedia with 2,500M words.
- Our testing used BERTLARGE and for Phase 1 used a maximum sequence length of 128 and for Phase 2 a maximum sequence length of 384 and sequences/sec were noted for pretraining along with bandwidth. The per-host numbers showed Weka on par or better than local NVMe drive based solution.
Resnet-50 – images/sec – training tests
- ResNet-50 is a widely used image classification benchmark and is often used as a standard for measuring the performance of machine learning accelerators.
- Weka showed reliable and best-in-class performance of 16K images/sec as concurrent jobs were added.
WEKA Data Platform for AI with Cerebres
Some of the AI/ML-centric benchmarks run with Cerebras are explained as below. The joint solution brief can be found here.
U-Net model training using tfrrecords
- U-Net is a convolutional neural network that was developed for biomedical image segmentation. The network is based on a fully convolutional network whose architecture was modified and extended to work with fewer training images and yield more precise segmentation. The benchmark was run across multiple cores and multiple clients. U-Net epoch times with Weka using tfrrecords (a binary format for tensorflow) was on par and in some cases better than local NVMe drives
MNIST model training using tfrrecord
- The MNIST database (Modified National Institute of Standards and Technology database) is a large database of handwritten digits that is commonly used for training various image processing DNN’s (Deep Neural Networks). The MNIST database contains 60,000 training images and 10,000 testing images, allowing deep learning researchers to quickly check and prototype their algorithm. The benchmark was run across multiple cores and multiple clients. MNIST epoch times, with Weka using tfrrecords (a binary format for tensorflow) was on par and in some cases better than local NVMe drives.
Summary
AI is a highly data and performance-intensive workload whose compute and storage requirements are both highly demanding and idiosyncratic compared to those we have known before. Delivering best-in-class performance for machine learning requires purpose-built solutions that can support their rigorous requirements, or projects risk stalling and even failure.
WEKA and our AI accelerator partners are working closely together to develop solutions that will help organizations to overcome these challenges economically and efficiently, to unleash their research and discovery.
Popular Blogs From Shailesh Manjrekar


Related Assets
-
Supercharging Creativity Parliament Webinar

Supercharging Creativity Parliament Webinar
-
23andMe’s Continuous Cloud Journey: Featuring WEKA & Converge Technologies

23andMe’s Continuous Cloud Journey: Featuring WEKA & Converge Technologies
-
Partners: Accelerate your Cloud Migration Practices with WEKA and AWS

Partners: Accelerate your Cloud Migration Practices with WEKA and AWS